Pushing the Boundaries of AI Interaction in a World of Complex Workflows
- Realistic Benchmarking for Real-World Challenges: MCPMark introduces 127 expertly crafted tasks that simulate diverse, multi-step interactions, revealing how top LLMs struggle with comprehensive CRUD operations and long-horizon planning.
- Performance Insights and Gaps: Evaluations show even leading models like gpt-5-medium achieving only moderate success rates, highlighting the need for smarter reasoning, better context management, and enhanced stability in AI agents.
- Future Directions for Progress: The benchmark identifies key areas for improvement in models, frameworks, and tools, while calling for scalable task creation and expansions to handle ambiguity and diverse digital environments.
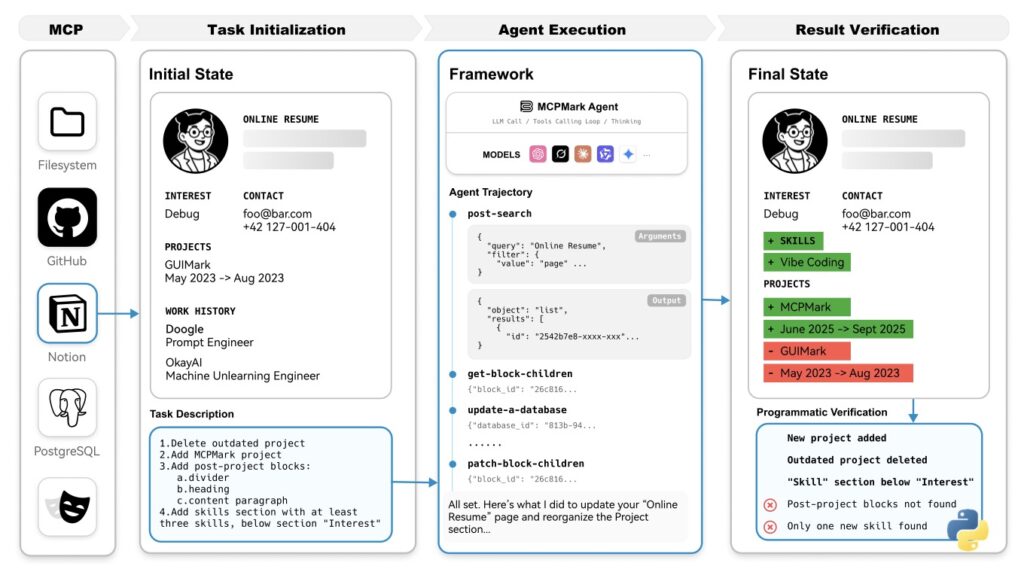
In an era where artificial intelligence is rapidly evolving from simple chatbots to sophisticated agents capable of interacting with the digital world, the need for robust evaluation tools has never been more critical. Enter MCPMark, a groundbreaking benchmark designed to stress-test the true capabilities of large language models (LLMs) in using the Model-Controller-Provider (MCP) standard. This standard forms the backbone of how LLMs connect with external systems, enabling them to perform tasks that mimic real-world workflows. But while existing MCP benchmarks have scratched the surface—often limiting themselves to read-heavy tasks or shallow interactions—MCPMark dives deeper, offering a more realistic and comprehensive assessment. Developed collaboratively by domain experts and AI agents, it comprises 127 high-quality tasks, each starting from a curated initial state and verified through programmatic scripts. These aren’t just theoretical exercises; they demand a broad spectrum of create, read, update, and delete (CRUD) operations, pushing agents to navigate complex environments with the kind of depth seen in everyday professional scenarios.
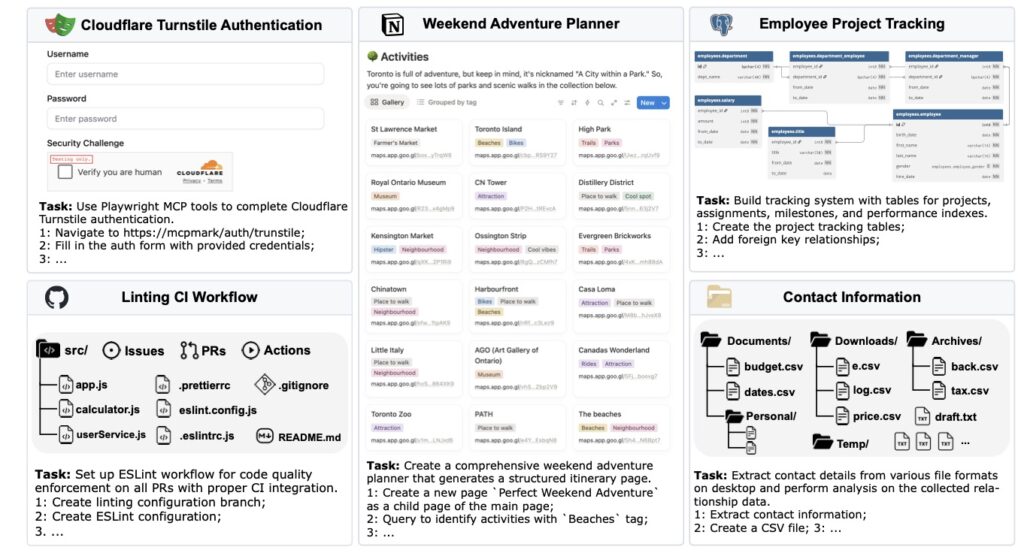
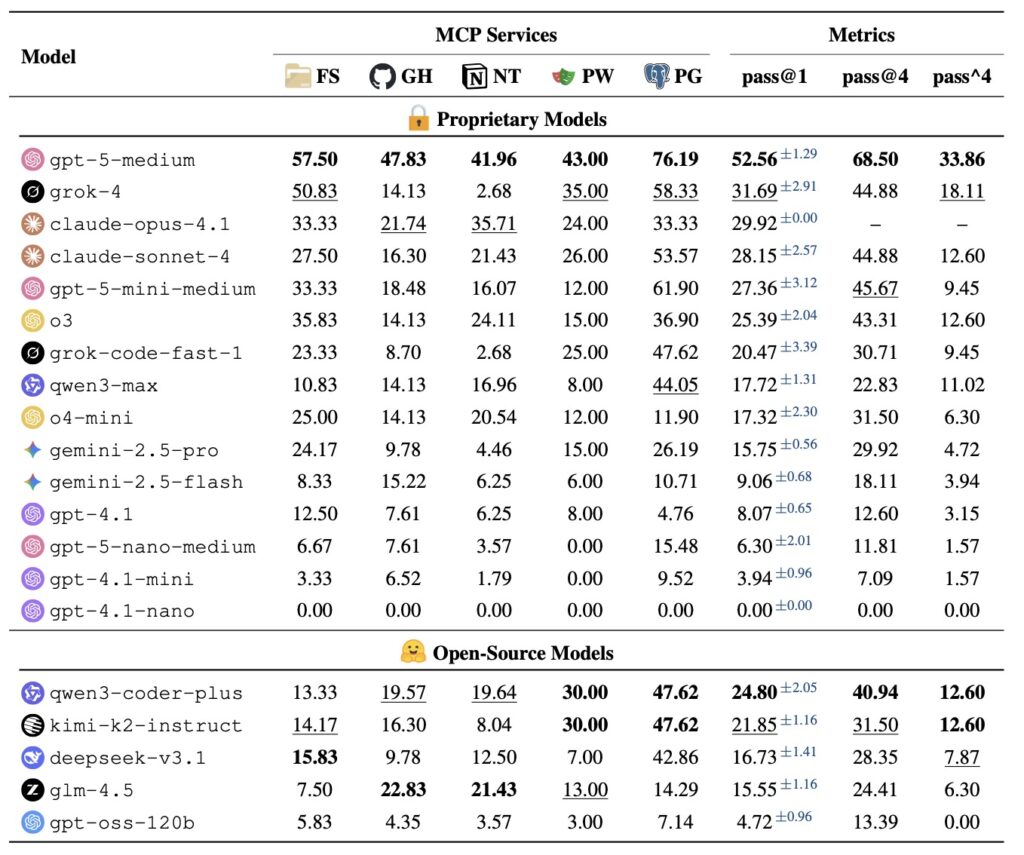
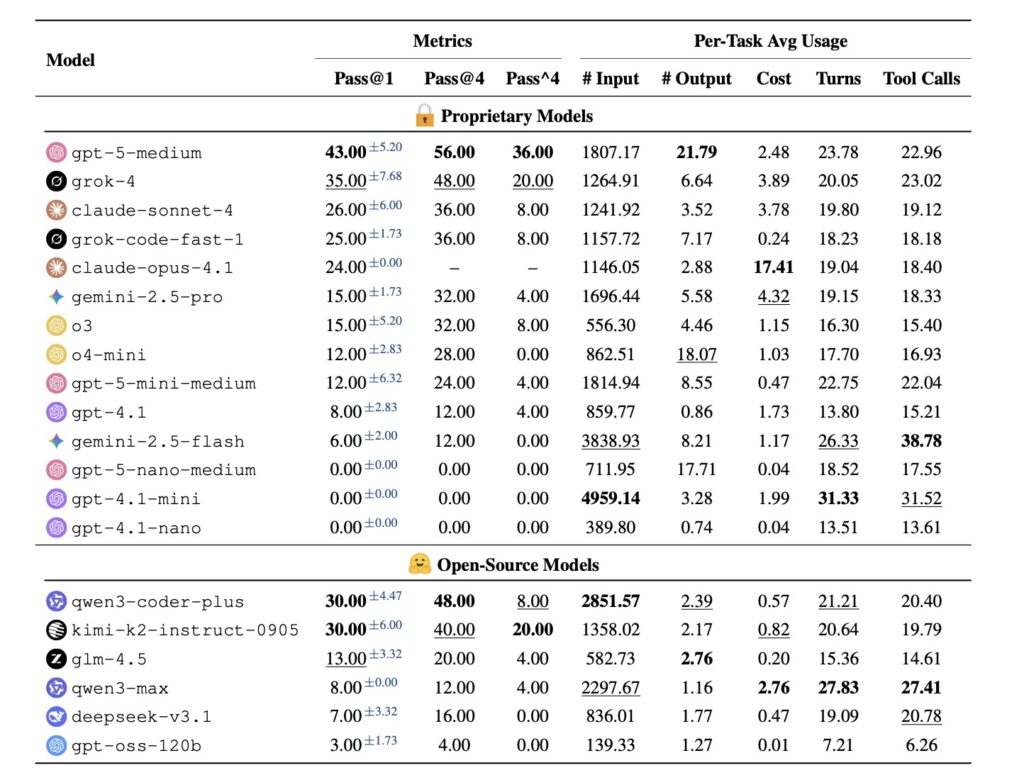
What makes MCPMark stand out is its emphasis on realism. Traditional benchmarks might evaluate an AI’s ability to fetch data or perform basic queries, but they fall short in capturing the multifaceted nature of real-world applications—like managing databases, updating records in dynamic systems, or handling multi-step processes that evolve over time. MCPMark addresses this by requiring richer interactions, where agents must make decisions that build on previous actions, much like a human professional juggling emails, spreadsheets, and APIs in a busy workday. To put this to the test, researchers evaluated cutting-edge LLMs using a minimal agent framework that operates in a tool-calling loop, simulating how these models would function in practical settings. The results are eye-opening: the top performer, gpt-5-medium, managed only a 52.56% pass rate on the first attempt (pass@1) and 33.86% after four tries (pass^4). Other strong contenders, such as claude-sonnet-4 and o3, dipped below 30% pass@1 and 15% pass^4. On average, these LLMs needed 16.2 execution turns and 17.4 tool calls per task—far exceeding the demands of prior benchmarks and underscoring MCPMark’s role as a true stress test.

These findings illuminate three pivotal directions for advancing AI agents, spanning the core language models, the frameworks that support them, and the server-side tools they interact with. First, agents must shift from reactive, trial-and-error tool use to more sophisticated reasoning. The data shows that success isn’t about making more attempts but fewer, smarter decisions. By enhancing reasoning capabilities, agents could generalize better across tasks, adapting to novel situations without constant recalibration. This evolution could transform AI from helpful assistants into reliable partners in complex domains like healthcare, finance, or logistics, where precision matters.
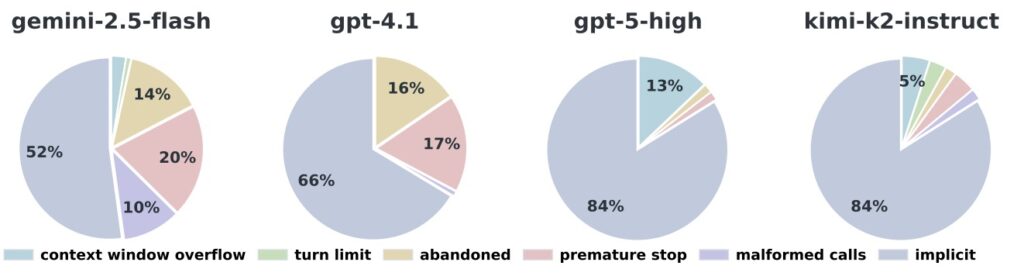
Second, tackling long-horizon tasks—those requiring sustained effort over many steps—demands breakthroughs in context efficiency. It’s not just about expanding a model’s context window; the real hurdle is managing an ever-growing history of interactions. MCPMark reveals how agents can get bogged down by verbose tool outputs and accumulated data, suggesting the need for advanced summarization strategies and more concise responses from tools. Imagine an AI agent coordinating a project across multiple platforms: without efficient history management, it risks losing track, much like a human overwhelmed by an endless email thread. Future improvements here could enable seamless, extended workflows, making AI indispensable for tasks that span days or weeks.
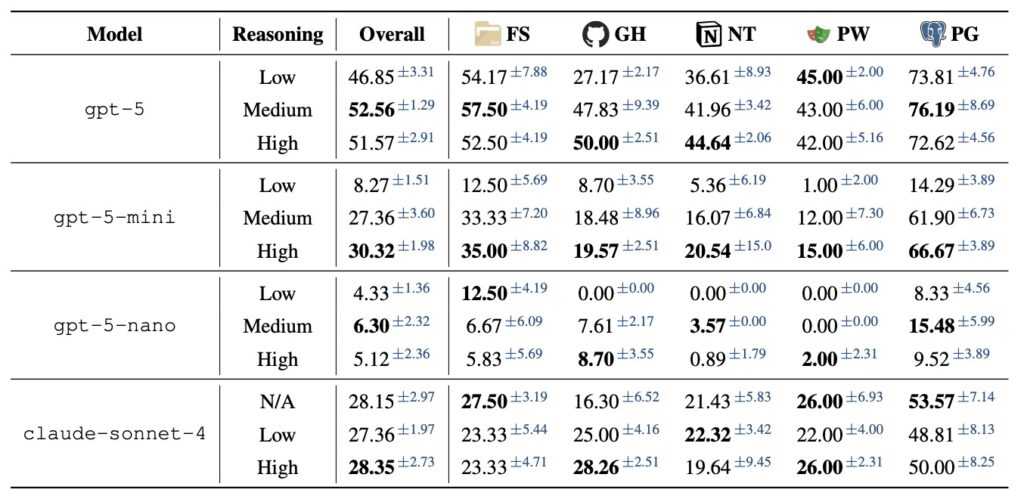
Finally, for AI systems to earn trust in real-world applications, they must achieve a profound leap in execution stability. MCPMark’s evaluations exposed inconsistencies across multiple runs, pointing to inherent unreliabilities that no amount of raw intelligence can mask. Building robust error-handling and self-correction mechanisms is essential—think of it as giving agents an internal “debug mode” to recover from missteps autonomously. MCPMark serves as an ideal testbed for measuring progress in these areas, providing concrete metrics to guide researchers toward more dependable systems.
Yet, as AI agents grow more capable, the benchmarks evaluating them must keep pace. MCPMark’s task creation pipeline, while ensuring top-notch quality through expert collaboration, is labor-intensive and hard to scale. This creates a bottleneck in generating the large-scale training data needed to propel the field forward. Moreover, the benchmark’s steep difficulty curve makes it less suitable for assessing smaller, more efficient models, which are crucial for edge computing or resource-constrained environments. To address this, future iterations could introduce a fine-grained difficulty gradient, perhaps via semi-automated task generation and shorter execution chains, allowing for broader applicability.
Expanding MCPMark to include tasks with ambiguous user intent would add another layer of realism. In the real world, instructions aren’t always crystal-clear; agents might need to ask clarifying questions or infer underlying goals, testing their conversational and adaptive skills. Additionally, incorporating a wider variety of MCP servers could challenge agents across diverse digital tools, from cloud services to specialized APIs, better mirroring the eclectic tech landscapes of modern enterprises. By evolving in these ways, MCPMark not only highlights current limitations but also paves the path for the next generation of AI agents—ones that are not just smart, but truly reliable and versatile in an increasingly interconnected world.