How AutoDeco Eliminates Manual Tweaks and Ushers in Truly End-to-End AI Creativity
- Challenging the Status Quo: Current large language models (LLMs) aren’t truly “end-to-end” due to their reliance on manual, non-differentiable decoding processes that demand hand-tuning of parameters like temperature and top-p.
- Introducing AutoDeco: This innovative architecture augments standard transformers with lightweight heads that dynamically predict token-level temperature and top-p values, enabling models to self-control their generation strategy in a single forward pass.
- Key Breakthroughs and Future Potential: AutoDeco outperforms default methods across benchmarks, matches oracle-tuned performance without extra tuning, and exhibits emergent abilities to follow natural language instructions for decoding—paving the way for more intuitive AI interactions and joint training advancements.
In the rapidly evolving world of artificial intelligence, large language models (LLMs) have become the backbone of everything from chatbots to creative writing tools. Yet, despite their impressive capabilities, a fundamental flaw has long persisted: the so-called “end-to-end” nature of these models is more myth than reality. Traditional LLMs generate text through a two-part process—first computing probabilities for the next token, then sampling from those probabilities using a decoding strategy. The catch? This decoding step is non-differentiable, meaning it can’t be optimized during training. Instead, it relies on human intervention to tweak hyperparameters like temperature (which controls randomness) and top-p (which limits sampling to the most probable tokens). This manual labor not only slows down development but also limits the models’ adaptability to different contexts, turning what should be a seamless AI pipeline into a clunky, hand-tuned machine.

Enter AutoDeco, a groundbreaking architecture designed to shatter this barrier and deliver truly end-to-end generation. At its core, AutoDeco builds on the standard transformer model by adding lightweight prediction heads. These heads work in tandem with the model’s existing logit computations, dynamically forecasting context-specific temperature and top-p values at each generation step. The result is a parametric decoding process that’s integrated directly into the model’s forward pass. No more static settings applied uniformly across an entire output—AutoDeco allows the AI to self-regulate its sampling strategy on a token-by-token basis, adapting in real-time to the nuances of the task at hand. This shift transforms decoding from a rigid, external hack into an intrinsic, learnable skill, making AI generation more efficient and intelligent.
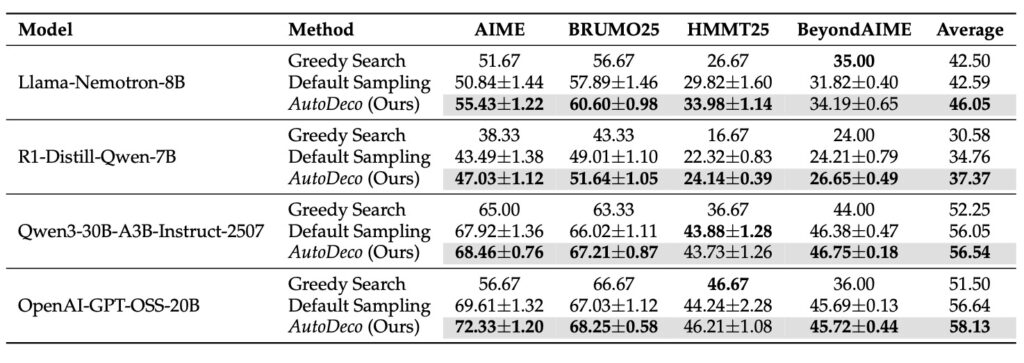
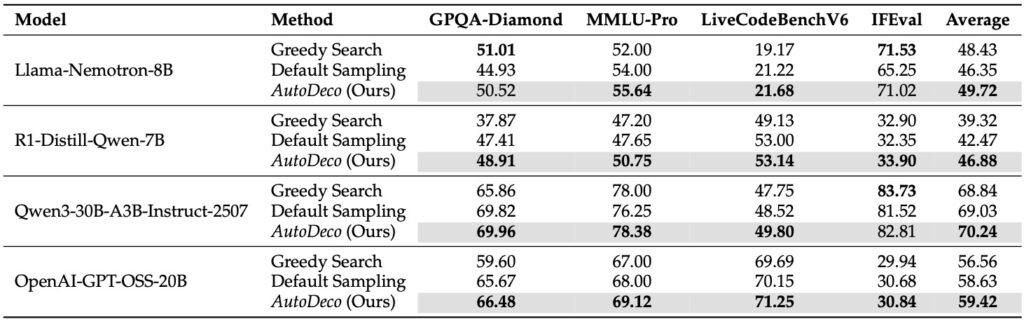
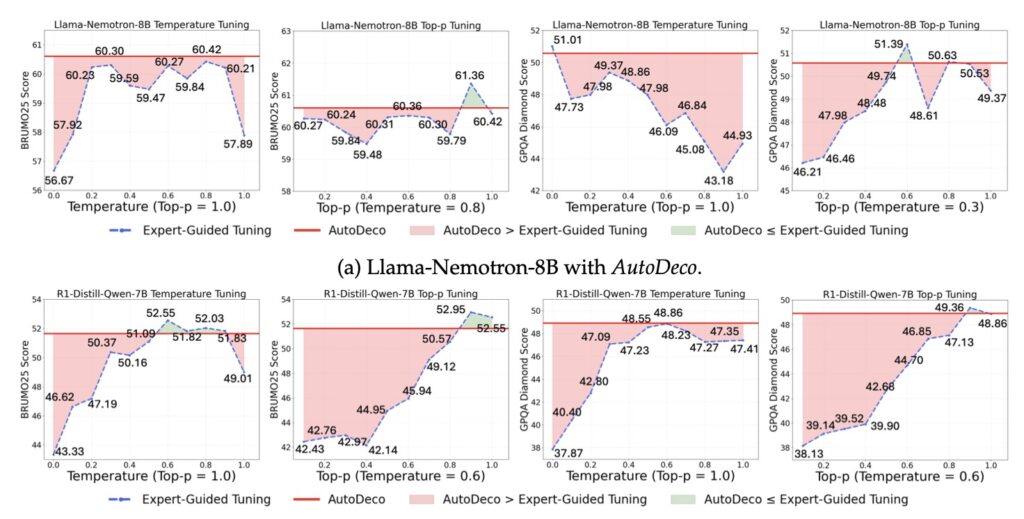
The power of AutoDeco isn’t just theoretical; it’s backed by rigorous experimentation across eight diverse benchmarks, spanning tasks like natural language understanding, code generation, and creative storytelling. In these tests, AutoDeco consistently outperformed default decoding strategies, which often require trial-and-error tuning to achieve decent results. Remarkably, it even rivaled an “oracle-tuned” baseline—a hypothetical upper limit derived from exhaustively “hacking the test set” to find the perfect static hyperparameters for each scenario. Achieving this without any task-specific adjustments highlights AutoDeco’s exceptional generalization capabilities. Whether applied to smaller models or massive ones, it delivers superior performance across the board, proving that self-regulated decoding isn’t just a nice-to-have—it’s a game-changer for AI reliability and versatility.
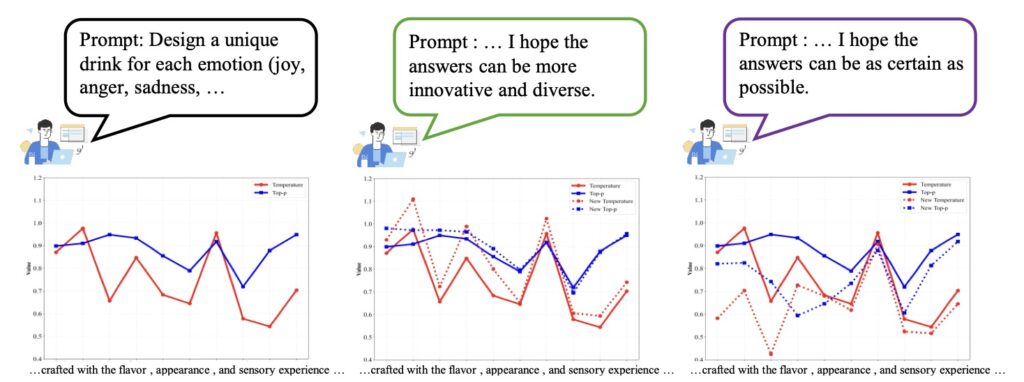
One of the most exciting discoveries from this research is AutoDeco’s emergent capability for instruction-based control. Beyond mere self-regulation, the model learns to interpret natural language commands embedded in prompts, such as “generate with low randomness” or “be more creative.” In response, it adjusts its predicted temperature and top-p values dynamically, token by token, to align with the user’s intent. This isn’t a pre-programmed feature; it arises naturally from the training process, representing a significant leap toward more intuitive human-AI collaboration. Imagine prompting an AI to “write a precise technical summary” and having it automatically dial down randomness for accuracy, or requesting “a whimsical story” and watching it amp up creativity on the fly. This emergent behavior underscores how AutoDeco bridges the gap between rigid algorithms and flexible, user-directed intelligence.
From a broader perspective, AutoDeco signals a paradigm shift in AI development. In an era where LLMs are deployed in critical applications—from healthcare diagnostics to autonomous content creation—the need for models that can adapt without constant human oversight is paramount. By eliminating the laborious hyperparameter tuning, AutoDeco reduces development time and democratizes access to high-performance AI, making it feasible for smaller teams or even individual developers to deploy sophisticated systems. Moreover, its negligible computational overhead—adding just a fraction of the resources needed for the base model—ensures it’s a practical, drop-in enhancement for any transformer-based architecture. This efficiency could accelerate innovations in fields like personalized education, where AI tutors adapt generation styles to student needs, or in creative industries, enabling tools that respond fluidly to artistic directives.
The potential for AutoDeco extends even further. Current limitations, such as occasional imprecision in prompt-based control or biases inherited from frozen backbone models, stem from training the decoding heads separately. Future work aims to address this by jointly training the entire base model alongside AutoDeco, fostering deeper integration and more granular control over generation. This could mitigate data biases and enhance the model’s ability to handle complex, nuanced instructions, ultimately leading to AI systems that feel less like tools and more like collaborative partners. As we move toward this future, AutoDeco stands as a pivotal step in realizing the full promise of end-to-end language models—ones that not only think but also decide how to express those thoughts with unprecedented autonomy and finesse.