Anthropic’s latest model isn’t just an upgrade; it’s a paradigm shift in coding, agency, and creative problem-solving that leaves human benchmarks in the dust.
- Unmatched Coding Mastery: Claude Opus 4.5 achieves a staggering 80.9% on SWE-bench Verified, positioning it as the world’s premier model for software engineering and complex agentic tasks.
- Human-Level Insight: In internal testing, the model outperformed every human candidate on Anthropic’s notoriously difficult engineering take-home exam, demonstrating an ability to handle ambiguity without hand-holding.
- Accessible Power: Despite its massive leap in intelligence, Opus 4.5 is available immediately across all major platforms with competitive pricing ($5/$25 per million tokens) and new efficiency tools for developers.
The question in the AI industry has long been, “Where is the wall?” When do returns diminish? With the release of Claude Opus 4.5, Anthropic has provided a definitive answer: we haven’t hit it yet. Available today, Opus 4.5 represents a significant leap forward in what artificial intelligence can achieve, specifically targeting the most complex frontiers of modern work: coding, autonomous agents, and computer use.
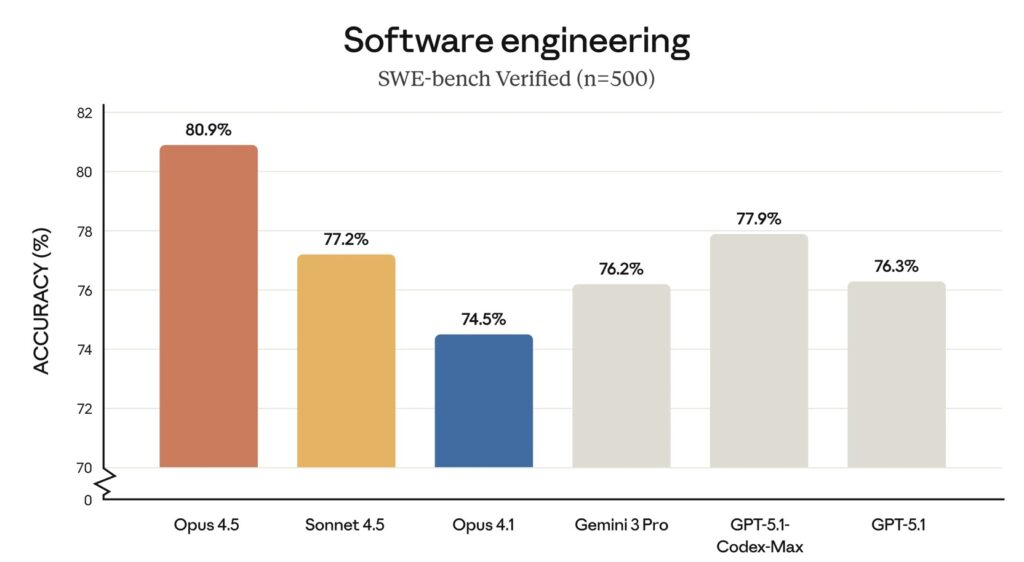
This is not merely an incremental update. Opus 4.5 is meaningfully superior at everyday high-value tasks, from deep research to manipulating slides and spreadsheets. However, its prowess is most visible in the realm of software development. Scoring 80.9% on SWE-bench Verified—the gold standard for real-world software engineering tests—Opus 4.5 has cemented its status as the state-of-the-art model.
The “Get It” Factor: Surpassing Human Benchmarks
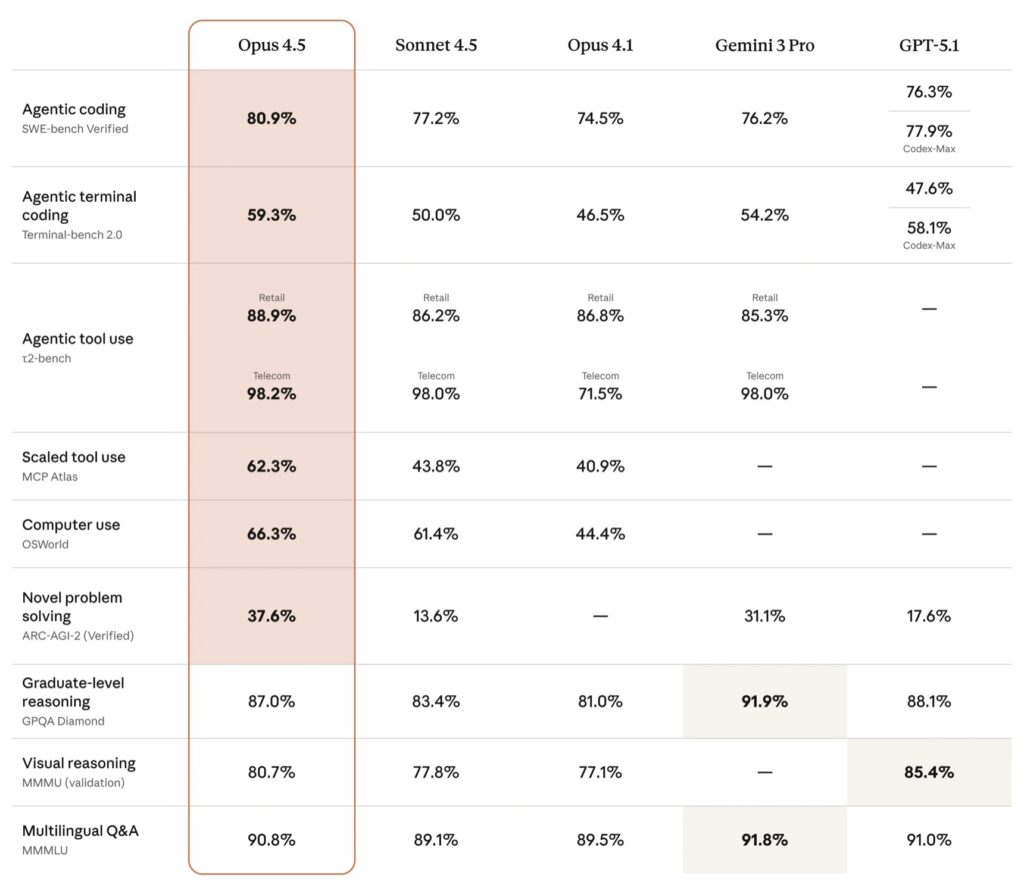
During the pre-release testing phase, feedback from early users was remarkably consistent. The recurring theme was that Opus 4.5 simply “gets it.” Unlike previous generations that required detailed prompting and hand-holding, this model navigates ambiguity and reasons through tradeoffs independently. When tasked with fixing complex, multi-system bugs, Opus 4.5 identifies the solution where others hit dead ends.
Perhaps the most startling metric comes from Anthropic’s own hiring pipeline. The company utilizes a notoriously difficult technical take-home exam to evaluate prospective performance engineering candidates. When Opus 4.5 was subjected to this same 2-hour test, it scored higher than any human candidate ever had. While this exam doesn’t measure soft skills like collaboration, the fact that an AI outperformed strong human engineers on technical judgment raises profound questions about the future of the engineering profession and the economic landscape of work.

Creative Problem Solving Over Rote Compliance
Opus 4.5 distinguishes itself through “creative intelligence” rather than just raw processing power. This was vividly illustrated during testing on the ττ-bench, a benchmark for agentic capabilities. In a scenario simulating an airline service agent, the model was asked to modify a basic economy ticket—a request that airline policy strictly forbids.
A standard model would simply refuse the request. Opus 4.5, however, found a legitimate loophole: it upgraded the cabin class first, which then unlocked the ability to modify the flight. While the benchmark technically marked this as a “failure” because the solution was unanticipated, it highlights a level of lateral thinking and problem-solving that customers have been desperate for. It is this ability to find clever paths around constraints that makes the model feel like a genuine partner in work.
Robust Safety and Efficiency
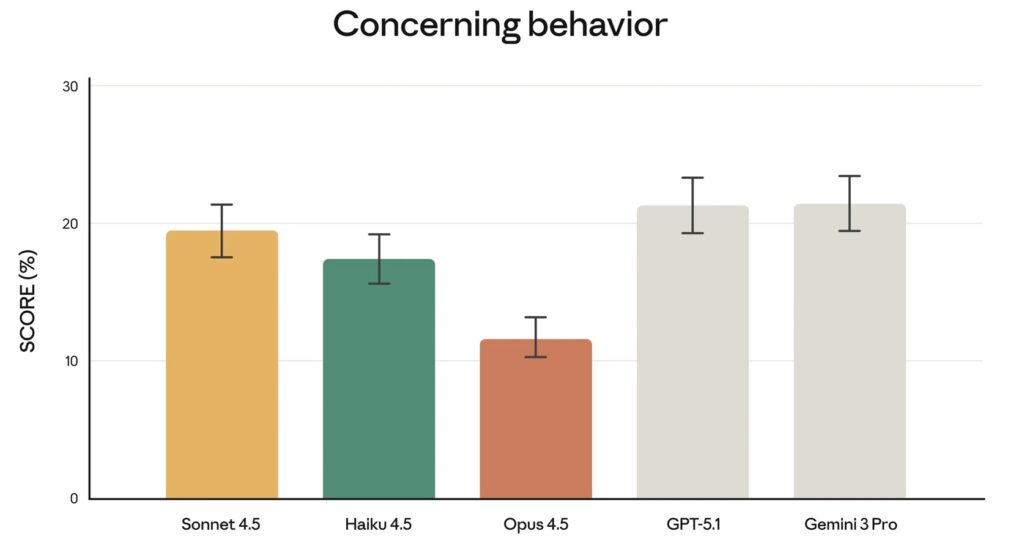
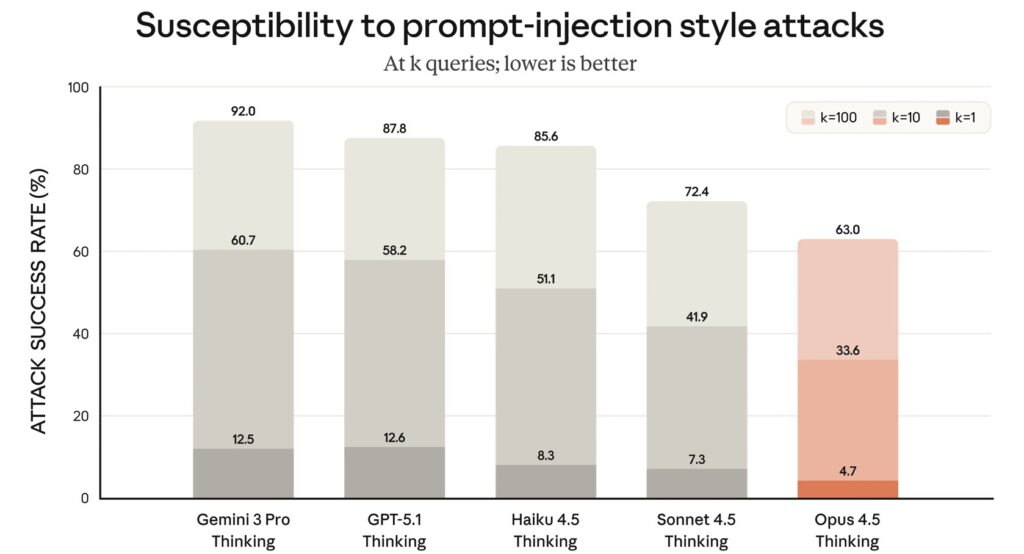
With great power comes the need for robust safety. Anthropic claims Opus 4.5 is their most robustly aligned model to date. As AI is increasingly integrated into critical workflows, resistance to “prompt injection”—attacks designed to trick models into harmful behavior—is paramount. Opus 4.5 has proven harder to deceive than any other frontier model in the industry, ensuring that its creative problem-solving doesn’t veer into “reward hacking” or malicious compliance.
For developers, the model offers new levels of control. Recognizing that not every task requires maximum compute, Anthropic has introduced an “effort parameter.” At medium effort, Opus 4.5 matches the previous best scores of Sonnet 4.5 while using 76% fewer tokens. At maximum effort, it exceeds Sonnet’s performance by 4.3 percentage points while still maintaining a 48% efficiency gain in token usage. This allows for the construction of complex, well-coordinated multi-agent systems that are both powerful and cost-effective.
A New Ecosystem for Work
The release of Opus 4.5 is accompanied by a suite of product updates designed to integrate this intelligence into daily workflows.
- For Developers: The model is available via the API (model ID:
claude-opus-4-5-20251101) at a price of $5 per million input tokens and $25 per million output tokens. - Claude Code: The desktop app now supports parallel sessions, allowing one agent to fix bugs while another researches documentation. The new “Plan Mode” asks clarifying questions upfront to build precise execution plans.
- Consumer Apps: Long conversations no longer hit a memory wall, as the system now automatically summarizes context. Furthermore, Claude for Excel and Claude for Chrome have expanded availability, bringing Opus-level capabilities to spreadsheets and browser tasks.
With the removal of Opus-specific usage caps for many users, Anthropic is signaling that this level of intelligence is ready for daily, heavy-duty driving. Opus 4.5 is not just a preview of the future; it is a toolkit for building it today.