Understanding critical statistics for optimizing LLM applications: a deep dive into Anyscale’s newly published guide
- Anyscale, a developer-centric company, has compiled essential figures and ratios for Large Language Model (LLM) developers, analogous to Google engineer Jeff Dean’s well-known list for engineers.
- This guide includes key factors like token-word ratios, cost metrics for different models, and the GPU memory capacities required for LLM serving and embedding.
- The numbers underline the cost-effectiveness of fine-tuning versus training models from scratch and indicate the substantial financial and computational resources required to train large LLMs.
Drawing from Google’s legacy of providing insightful metrics for engineers, Anyscale, the developer-first company, has published an essential guide containing figures and facts every LLM developer should know. This comprehensive compendium is set to empower developers with back-of-the-envelope calculations for effective LLM applications.
The guide focuses on various aspects, including tokenization, costs, training, and GPU memory utilization. For instance, it reveals that appending “Be Concise” to a prompt can result in a saving of 40-90%, given that billing is typically based on tokens. Understanding the average tokens per word ratio (1.3:1 for English) is crucial for this reason.
Cost-wise, a comparison of GPT-4 to GPT-3.5 Turbo shows a substantial cost ratio of ~50:1. Anyscale thus recommends using GPT-4 for generation and the data to fine-tune a smaller, cheaper model like GPT-3.5 Turbo. The cost ratio dramatically falls to 5:1 for generating text using GPT-3.5 Turbo versus OpenAI embedding, stressing the cost-effectiveness of looking up information rather than generating it.
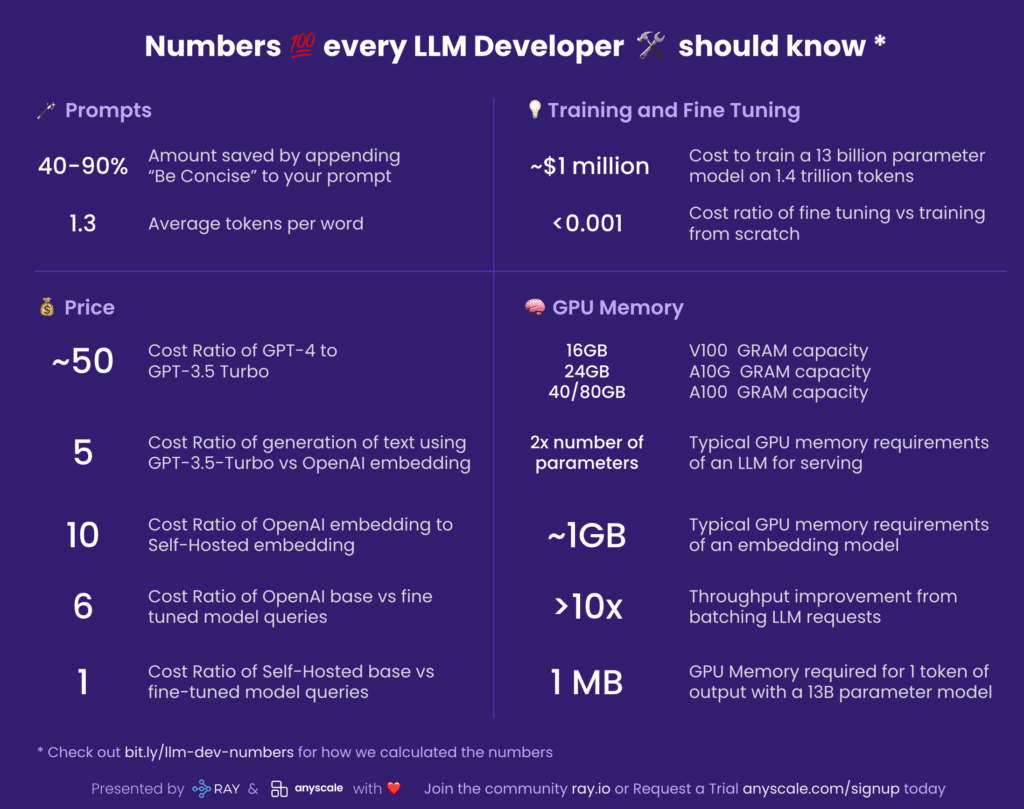
The guide also delves into the realm of training and fine-tuning, cautioning developers about the hefty ~$1 million cost to train a 13-billion parameter model on 1.4 trillion tokens. Interestingly, fine-tuning costs are trivial in comparison, with a cost ratio of less than 0.001 when compared to training from scratch.
Lastly, Anyscale highlights the importance of understanding GPU memory for those self-hosting a model. Knowing the memory capacity of different GPU types is critical, as is being aware of the typical GPU memory requirements of an LLM for serving, which is roughly twice the number of parameters. Similarly, an embedding model typically requires ~1GB of GPU memory.
Batching LLM requests can also significantly improve throughput, but developers must be mindful of the proportional GPU memory required for each token of output.
The guide, periodically updated on Github, invites community contributions to ensure accuracy and to add more helpful numbers. Anyscale’s new compilation appears set to become an invaluable resource for developers working with large language models.