Redefining the state of the art for long-running agents, advanced coding, and complex reasoning.
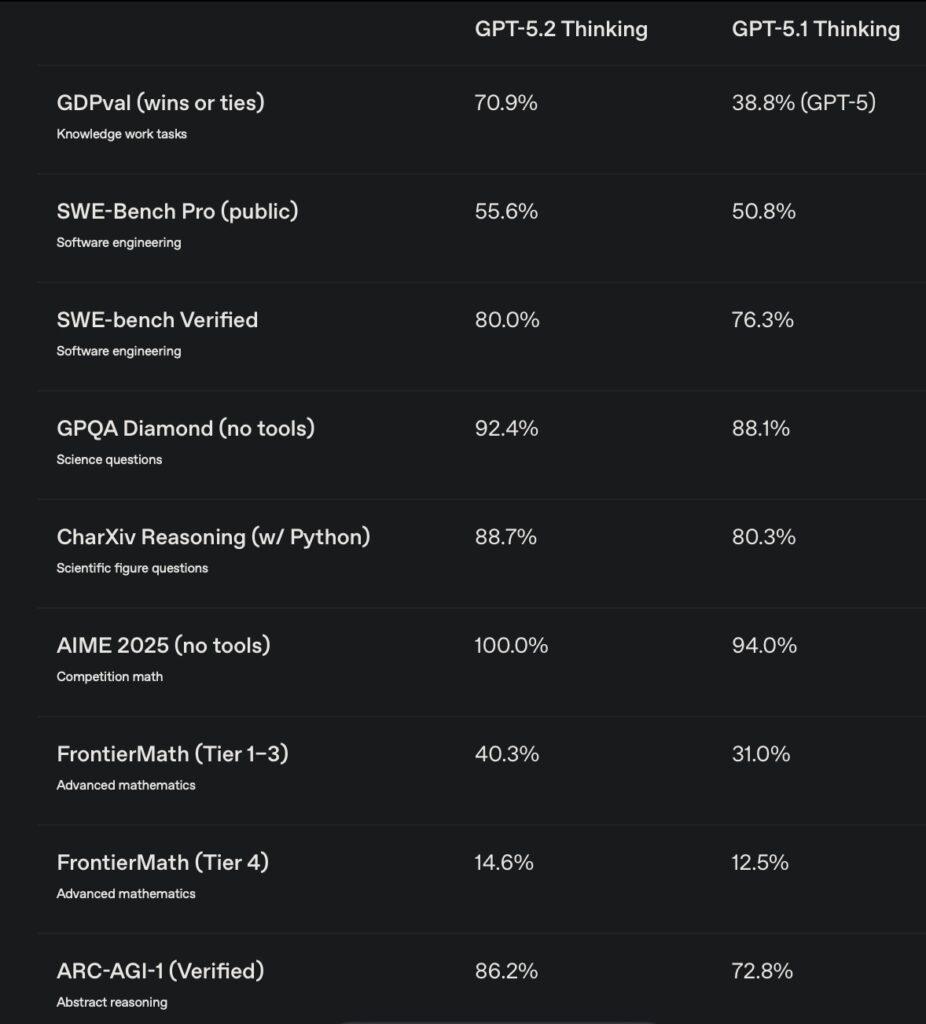
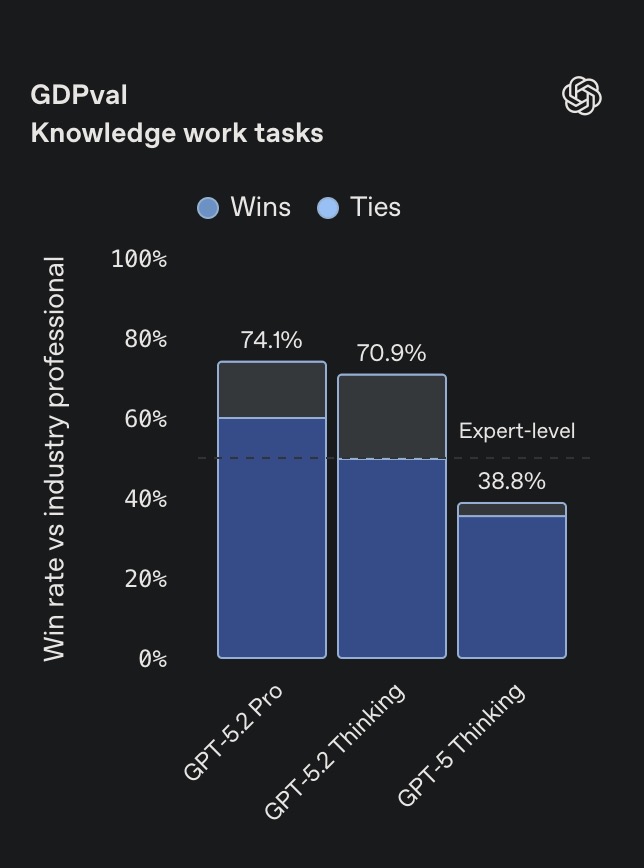
- Human-Level Professional Expertise: GPT-5.2 performs at or above the level of human experts on 70.9% of professional knowledge work tasks, delivering results at >11x the speed and <1% of the cost.
- A Leap in Agentic Coding: Setting a new standard with 80% on SWE-bench Verified, the model excels at full-stack engineering, complex UI implementation, and self-correcting agentic workflows.
- Unmatched Reasoning & Accuracy: Achieving 100% on AIME 2025 competition math and near-perfect long-context retention, GPT-5.2 drastically reduces hallucinations while handling massive documents and datasets.
We are entering a new era of AI-driven economic value. With average enterprise users already saving nearly an hour a day using AI, the demand for models that can handle genuine professional complexity has never been higher. Today, we are introducing GPT-5.2, the most capable model series yet for professional knowledge work. Designed to execute multi-step projects, perceive complex images, and understand vast amounts of context, GPT-5.2 unlocks new possibilities for spreadsheets, presentations, and autonomous agents.
The First Model to Rival Human Experts
For the first time, an AI model has demonstrated performance that matches or exceeds that of human experts in well-specified professional tasks. On GDPval, a rigorous benchmark spanning 44 occupations, GPT-5.2 Thinking beats or ties top industry professionals in 70.9% of comparisons.
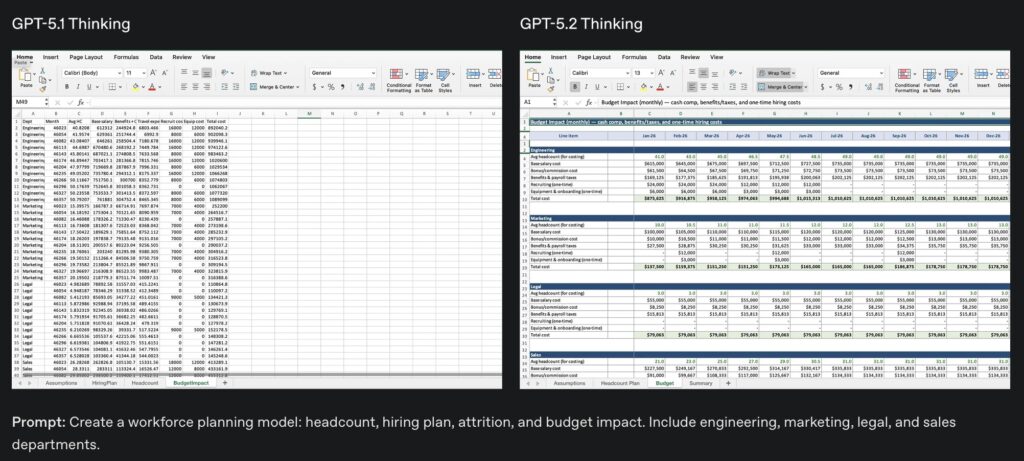
Whether it is generating sophisticated slide decks or managing complex spreadsheets, the model offers a staggering efficiency boost—producing outputs at more than 11 times the speed and less than 1% of the cost of human professionals. In blind comparisons, judges noted that the model’s output appeared to be the work of “a professional company with staff,” featuring surprisingly well-designed layouts. This jump in quality is also evident in specialized fields; on internal investment banking tasks, such as building leveraged buyout models, GPT-5.2 saw a 9.3% score increase over its predecessor, GPT-5.1.
A Powerhouse for Engineering and Agents
GPT-5.2 represents a massive leap forward for software engineering. On SWE-bench Verified, the model achieves a record-breaking 80%, while also setting a new state of the art on the more rigorous, multi-language SWE-Bench Prowith a score of 55.6%.
Beyond raw metrics, GPT-5.2 Thinking is practically better at the daily grind of coding. It is significantly stronger at front-end development, particularly when handling 3D elements and unconventional UIs. Early testers report that it allows them to collapse fragile, multi-agent systems into single “mega-agents” that are faster and easier to maintain. As one tester noted, “It feels like pure magic,” citing the ability to execute complex architectures off a simple, one-line prompt.
This agentic capability extends to tool use across the board. On the Tau2-bench Telecom evaluation, GPT-5.2 achieved 98.7%, proving it can reliably coordinate workflows—like rebooking flights while arranging medical assistance and compensation—without breaking down between steps.
Deep Reasoning, Vision, and Science
The “Thinking” capabilities of GPT-5.2 have been refined to tackle the hardest problems in math and science. The model achieves 100% on AIME 2025 (competition math) and 92.4% on GPQA Diamond (graduate-level science), making it a premier partner for research. In fact, GPT-5.2 Pro has already been used to propose a proof in statistical learning theory that was subsequently verified by human experts.
This intelligence is supported by a massive upgrade in context window and vision:
- Long Context: The model is the first to achieve near 100% accuracy on the 256k token “needle-in-a-haystack” test (MRCRv2), enabling deep analysis of hundreds of research papers or contracts without losing coherence.
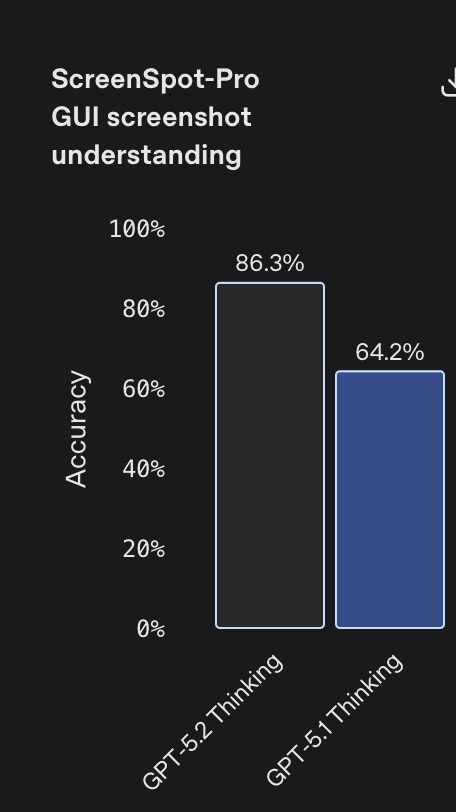
- Vision: Error rates on chart reasoning and software interface understanding have been cut roughly in half. In tasks like identifying motherboard components, GPT-5.2 accurately places bounding boxes and understands spatial arrangements where previous models failed.
Reliability and Safety
For professionals to rely on AI, accuracy is non-negotiable. GPT-5.2 reduces hallucinations by 30% compared to GPT-5.1. It also introduces the “safe completion” approach, ensuring helpful answers that remain within safety boundaries. We have made meaningful improvements in handling sensitive topics, such as mental health distress, resulting in fewer undesirable responses. Additionally, we are rolling out age prediction models to better protect users under 18.
Availability
GPT-5.2 is rolling out today in Instant, Thinking, and Pro variations.
- For Users: Available immediately to paid subscribers (Plus, Pro, Team, Enterprise) in ChatGPT.
- For Developers: Available now in the API. Developers can utilize the new
xhighreasoning effort for tasks where quality is paramount.
