Revolutionizing AI Access with Powerful, Open-Weight Models for Everyone
- Breakthrough Performance on a Budget: OpenAI’s new gpt-oss-120b and gpt-oss-20b models deliver top-tier reasoning, tool use, and efficiency, rivaling proprietary systems like o4-mini and o3-mini, all while running smoothly on everyday hardware like a single 80GB GPU or even edge devices with just 16GB of memory.
- Safety and Customization at the Forefront: Built with rigorous safety protocols, including adversarial fine-tuning tests and alignment with OpenAI’s Model Spec, these Apache 2.0-licensed models offer full customizability, chain-of-thought reasoning, and seamless integration into agentic workflows, empowering developers from individuals to enterprises.
- Pushing Open AI Forward: Trained using advanced techniques from frontier models, these releases mark OpenAI’s first open-weight language models since GPT-2, fostering innovation through partnerships, open-sourcing tools like the o200k_harmony tokenizer, and initiatives like a red teaming challenge with a half-million-dollar prize fund to enhance community-driven safety.
In a move that’s set to democratize artificial intelligence, OpenAI has unveiled its latest innovation: two free, open-weight GPT models that anyone can download and run directly on their personal devices. Dubbed gpt-oss-120b and gpt-oss-20b, these models represent a significant shift in the AI landscape, blending state-of-the-art performance with unprecedented accessibility. For the first time in six years, since the release of GPT-2, OpenAI is opening up its weights under the flexible Apache 2.0 license, allowing developers, researchers, and even hobbyists to tinker, customize, and deploy powerful AI without relying on costly cloud infrastructure. This isn’t just about sharing code—it’s about empowering a global community to build AI on their own terms, from on-device apps to enterprise solutions.
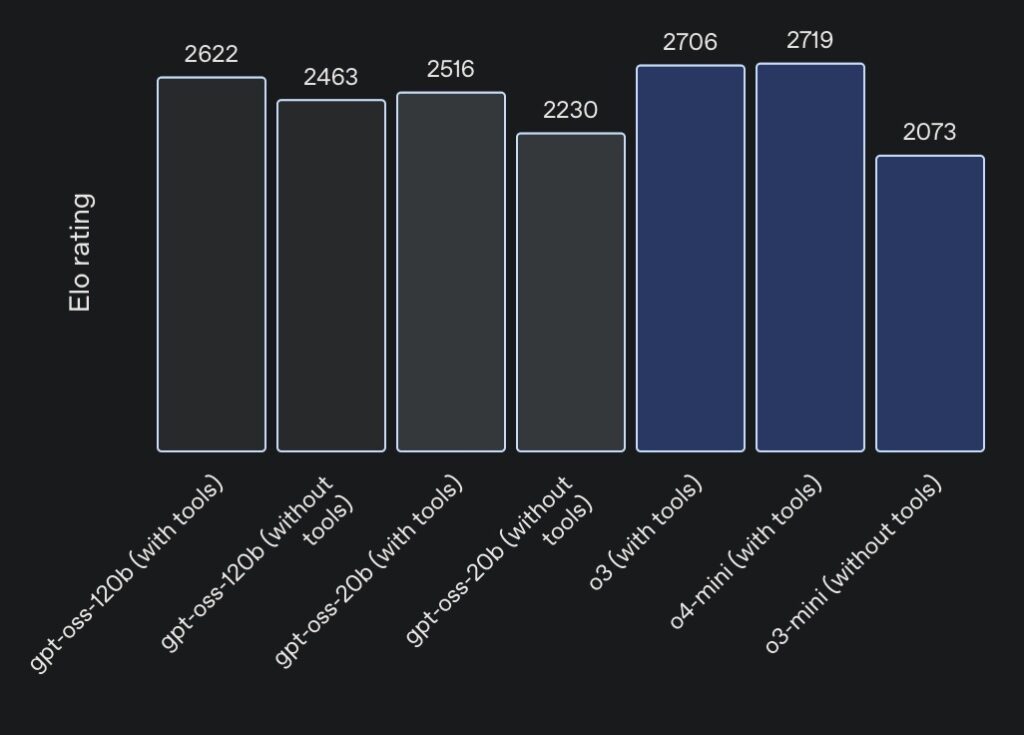
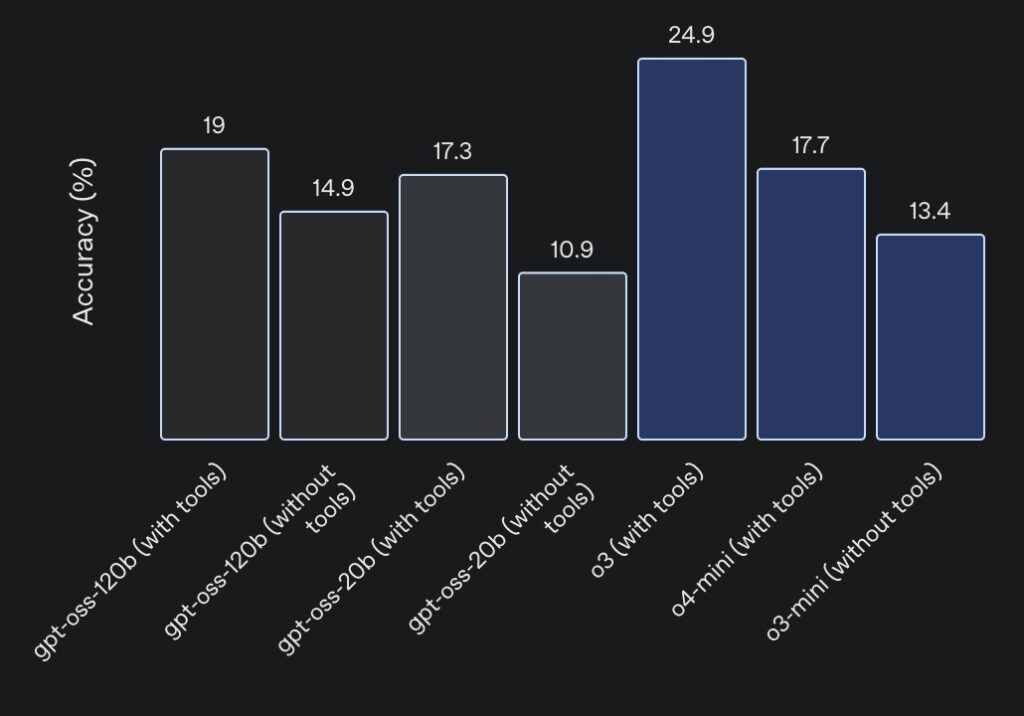
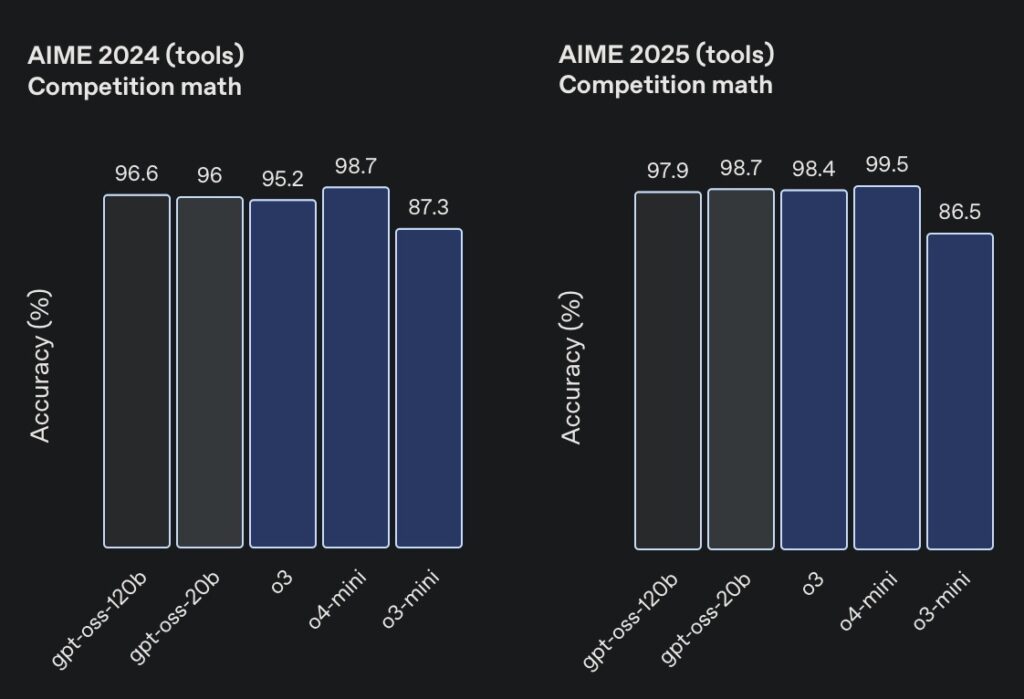
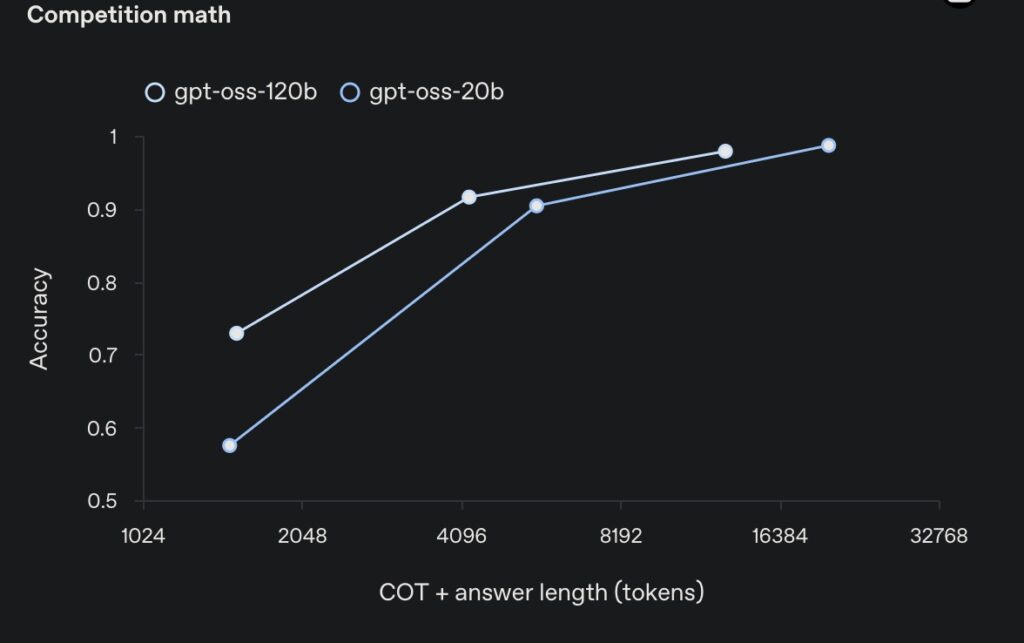
At the heart of these models is a focus on efficiency and real-world usability. The gpt-oss-120b, with its 117 billion total parameters, activates only about 4.3 billion per token thanks to a mixture-of-experts (MoE) architecture, making it remarkably lightweight for its capabilities. It achieves near-parity with OpenAI’s o4-mini on core reasoning benchmarks, excelling in areas like competition coding on Codeforces, general problem-solving on MMLU and HLE, and even health-related queries on HealthBench—where it outperforms proprietary heavyweights like o1 and GPT-4o. Meanwhile, the smaller gpt-oss-20b, boasting 21 billion parameters and activating roughly 3.6 billion per token, matches or surpasses o3-mini on similar evaluations, including competition mathematics on AIME 2024 and 2025. What makes them truly groundbreaking is their optimization for consumer hardware: the larger model runs efficiently on a single 80GB GPU, while the smaller one thrives on edge devices with just 16GB of memory, perfect for local inference, rapid prototyping, or privacy-sensitive applications.
These models were crafted using OpenAI’s most advanced pre-training and post-training techniques, drawing inspiration from frontier systems like o3 and others. Built on a Transformer architecture with alternating dense and locally banded sparse attention patterns—similar to GPT-3—they incorporate grouped multi-query attention for better inference speed and Rotary Positional Embedding (RoPE) for handling context lengths up to 128k tokens. Trained primarily on an English, text-only dataset emphasizing STEM, coding, and general knowledge, the models use the newly open-sourced o200k_harmony tokenizer, a superset of those in o4-mini and GPT-4o. Post-training mirrors the process for o4-mini, involving supervised fine-tuning and high-compute reinforcement learning (RL) to align with OpenAI’s Model Spec. This enables exceptional instruction following, tool use—such as web search or Python code execution—and chain-of-thought (CoT) reasoning. Developers can even adjust reasoning effort levels (low, medium, high) via a simple system message, balancing latency and performance for tasks ranging from quick queries to complex problem-solving.
One of the standout features is their prowess in agentic workflows and evaluations. On the Tau-Bench agentic suite, both models shine in few-shot function calling and tool use, while HealthBench results highlight their edge over closed models in specialized domains. Importantly, OpenAI avoided direct supervision on the CoT to allow for better monitoring of potential misbehavior, deception, or misuse—a principle echoed in recent research and shared by industry peers. This transparency is crucial, as CoTs can sometimes contain hallucinations or unsafe content, so developers are advised not to expose them directly to end-users. Instead, the models support Structured Outputs and are compatible with OpenAI’s Responses API, making them ideal for building customizable AI agents that reason efficiently without unnecessary overhead.
Safety remains a cornerstone of this release, especially for open-weight models that could be fine-tuned by anyone. OpenAI applied comprehensive safety training, filtering harmful data during pre-training (like CBRN-related content) and using deliberative alignment and instruction hierarchy in post-training to refuse unsafe prompts and resist injections. To assess worst-case scenarios, they created adversarially fine-tuned versions of gpt-oss-120b on biology and cybersecurity data, evaluating them under the Preparedness Framework. These tests, reviewed by external experts, showed that even malicious fine-tuning couldn’t elevate the models to high-risk capability levels. The findings are detailed in a research paper and model card, setting new standards for open model safety. To further bolster the ecosystem, OpenAI is launching a Red Teaming Challenge with a half-million-dollar prize fund, inviting global participants to uncover novel risks. Winners, judged by experts from OpenAI and other labs, will contribute to an open-sourced evaluation dataset, accelerating industry-wide safety research.
OpenAI’s collaboration with partners like AI Sweden, Orange, and Snowflake underscores the models’ real-world potential. From on-premises hosting for data security to fine-tuning on specialized datasets, these early adopters are exploring applications that prioritize privacy and cost-efficiency. The models are available for download on Hugging Face, natively quantized in MXFP4 for minimal memory use, and supported by open-sourced tools like a harmony prompt renderer in Python and Rust, plus reference implementations for PyTorch and Apple’s Metal. Partnerships with platforms such as Azure, Hugging Face, vLLM, Ollama, llama.cpp, LM Studio, AWS, Fireworks, Together AI, Baseten, Databricks, Vercel, Cloudflare, and OpenRouter ensure broad accessibility. Hardware optimizations from NVIDIA, AMD, Cerebras, and Groq, along with Microsoft’s ONNX Runtime integration for Windows devices via Foundry Local and the AI Toolkit for VS Code, make deployment seamless across systems.
This release isn’t just technical—it’s a philosophical statement on why open models matter. By complementing proprietary API offerings, gpt-oss models lower barriers for emerging markets, small organizations, and resource-limited sectors, fostering innovation and democratic access to AI. They enable everything from local AI on laptops to customized enterprise solutions, without multimodal features or built-in tools that API models provide. Developers can experiment in OpenAI’s open model Code Playground or follow guides for fine-tuning and integration. As OpenAI continues to evolve based on feedback—potentially adding API support—these models invite the world to collaborate, push boundaries, and build a safer, more inclusive AI future. Whether you’re a solo coder or a government agency, the power of frontier-level AI is now in your hands, ready to spark the next wave of creativity and discovery.