Bridging the gap between generalist AI and high-precision physical mastery through a novel reinforcement learning pipeline.
- From Generalist to Specialist: GR-RL is a groundbreaking framework that transforms broad Vision-Language-Action (VLA) models into highly capable specialists, overcoming the “noisy” nature of human demonstrations in precise tasks.
- The “Shoe Lacing” Breakthrough: The framework is the first learning-based policy capable of autonomously lacing a shoe—a complex, long-horizon task involving soft-body mechanics—achieving an impressive 83.3% success rate.
- A Three-Stage Evolution: Success was achieved through a pipeline of filtering data via offline Reinforcement Learning (RL), applying morphological symmetry augmentation, and fine-tuning through online RL to correct behavior in the real world.

The field of robotics is currently undergoing a massive transformation driven by the emergence of large-scale Vision-Language-Action (VLA) models. Much like how Large Language Models (LLMs) revolutionized text, VLAs promise to create generalist robotic agents that can understand visual cues and follow natural language instructions. However, a significant gap remains between understanding a task and physically executing it with precision. While current systems show impressive generalization across different objects and environments, they often struggle with tasks requiring extreme dexterity and long-term reasoning. Enter GR-RL, a new framework from ByteDance that aims to turn these generalist robots into reliable, real-world experts.

The Problem with Human Teachers
For years, the gold standard in training robots has been “Behavior Cloning”—essentially, having a robot watch a human perform a task and try to copy it. This relies on the assumption that human demonstrations are optimal. The researchers behind GR-RL challenge this core belief. They argue that for highly dexterous, millimeter-precision tasks, human movements are actually “noisy” and suboptimal. When a robot blindly mimics a human, it inherits these imperfections, leading to failure in complex scenarios.
To solve this, GR-RL proposes that we shouldn’t just copy humans; we should filter their actions, augment their data, and let the robot practice until it surpasses its teachers.
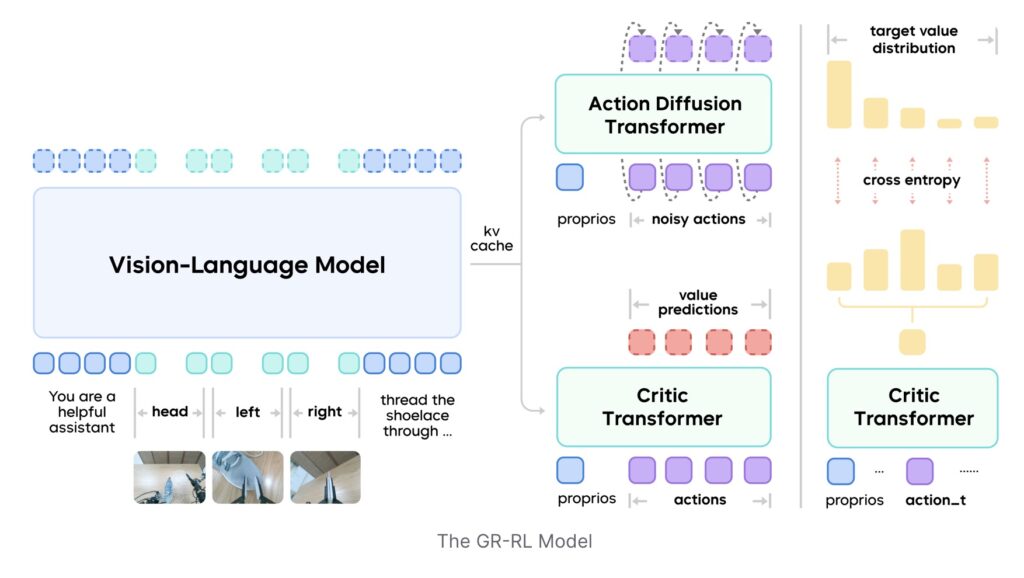
The Three-Stage Pipeline to Precision
The GR-RL framework utilizes a sophisticated multi-stage training pipeline designed to refine a robot’s capabilities systematically.
- Filtering with Offline RL: The first step involves cleaning up the data. GR-RL learns a vision-language-conditioned task progress tracker. By applying offline Reinforcement Learning (RL) with sparse rewards, the system generates Q-values that act as a “progress function.” This allows the system to filter out “junk” data from human demonstrations, keeping only the transitions that positively contribute to the goal.
- Morphological Symmetry Augmentation: To improve generalization, the team introduced simple yet effective augmentation tricks. By manipulating the data through symmetry (e.g., flipping or rotating perspectives), the robot learns to understand the task structure better, regardless of orientation.
- Online RL and Noise Prediction: Finally, to align the policy with the harsh reality of physics, the robot undergoes online RL. This involves learning a latent space noise predictor to handle the unpredictability of the real world. This stage is crucial for high-precision control, allowing the robot to adjust its movements dynamically.
The Ultimate Test: Lacing a Shoe
To prove the efficacy of this framework, the researchers chose a task that is deceptively simple for humans but nightmarishly difficult for robots: lacing a shoe. This task requires “long-horizon reasoning” (planning many steps ahead), millimeter-level precision to hit the eyelets, and the ability to manipulate “soft bodies” (floppy shoelaces) that change shape unpredictably.
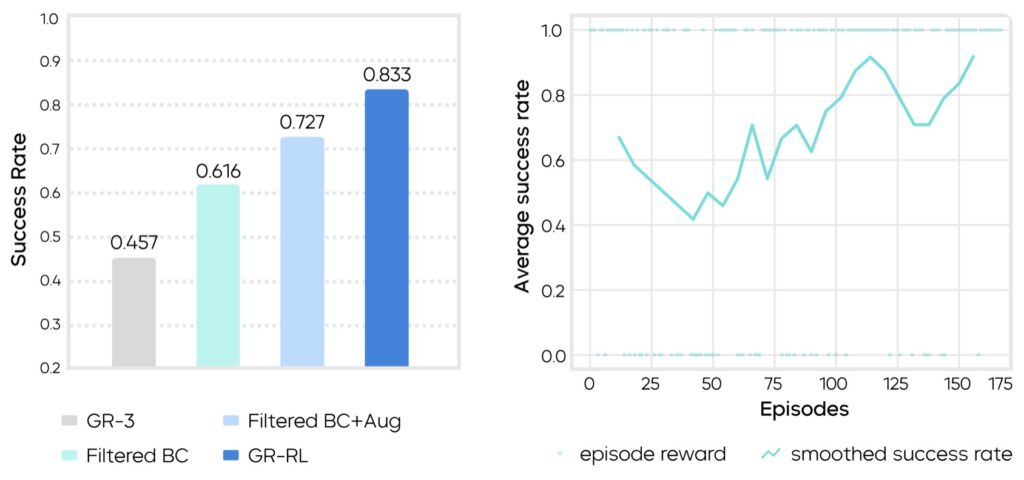
The results were staggering. A baseline model trained only on human imitation achieved a success rate of just 45.7%. However, as the GR-RL pipeline was applied, performance climbed steadily:
- After Data Filtering: Success rose to 61.6%.
- After Augmentation: Success jumped to 72.7%.
- After Online RL: The final model achieved an 83.3% success rate.
This makes GR-RL, to the researchers’ knowledge, the first learning-based policy capable of autonomously threading shoelaces through multiple eyelets.
Robustness and “Intelligent” Recovery
What makes GR-RL truly impressive is not just that it can lace a shoe, but how it handles failure. The system demonstrates robust, adaptive behaviors that mimic human problem-solving.
For instance, if the robot drops the shoelace or misses an eyelet, it automatically retries. If the shoelace ends are crossed with the target end buried underneath, the robot identifies the issue and pulls the correct end free. It even manipulates the environment to make its job easier: if a shoe is too far away, the robot pulls it closer. If the grasping point on the lace is too far from the tip, it places the lace down and “re-grasps” it closer to the end for better control. It can even handle shoes of different colors, sizes, and textures, proving it isn’t just memorizing a specific shoe but understanding the concept of lacing.

The Road Ahead
Despite these successes, the journey is not over. The researchers note that the system still faces “behavior drifting,” where the policy can become unstable during online learning due to sparse rewards. This suggests that the lightweight noise predictor may have limited capacity, or that credit assignment in such a large action space remains a hurdle.
However, GR-RL represents a significant leap forward. By proving that generalist models can be refined into specialists through rigorous filtering and reinforcement learning, ByteDance has provided a blueprint for the future. It is a step toward a world where robot foundation models don’t just understand our commands, but have the dexterity to execute them flawlessly.