How Scalable Online Post-training (SOP) is transforming robot fleets into continuous learners that improve within hours of deployment.
- The Deployment Gap: While Vision-Language-Action (VLA) models provide robots with broad general knowledge, they often lack the expert-level proficiency and reliability required for specific real-world tasks.
- The SOP Solution: Scalable Online Post-training (SOP) bridges this gap by coupling execution with learning, allowing a fleet of robots to stream experiences to a cloud learner and receive updated policies in real-time.
- The Power of Scale: SOP demonstrates that intelligence scales with the number of robots; a fleet of four robots learns 2.4x faster than a single unit, proving that deployment is not the end of development, but the start of rapid, collective evolution.
For general-purpose robots to operate at scale in the real world, mere task feasibility is far from enough. We dream of robots that can handle household chores or industrial assembly, but the reality is often clunky. The real challenge is that general-purpose robots working in the physical world must maintain high stability and reliability in complex, ever-changing environments while retaining exceptional generalization across vastly different tasks.
At the same time, these robots should not have their capabilities frozen upon deployment; instead, they should be able to rapidly adapt to environmental changes and continuously learn from real-world physical experience. To address this, we introduce SOP (Scalable Online Post-training), a framework designed to enable online updates of Vision-Language-Action (VLA) models across robot fleets.
The Foundation Model Paradox: Broad but Clumsy
Over the past few years, pre-trained VLA models have provided general-purpose robots with remarkable generalization capabilities. Through pre-training on internet-scale data, these models know what a cup is, how to hold a rag, and how to identify an apple. However, pre-training alone cannot efficiently yield high performance on specific tasks.
To address performance issues, “post-training” has become the primary solution. While Large Language Models (LLMs) have mastered this through reinforcement learning, robotics faces a harder path. Post-training in the physical world faces numerous challenges:
- Distribution Shift: There is a disconnect between high-quality static training data and the messy reality of robot deployment.
- Scale Limits: Single-robot learning is painfully slow.
- Catastrophic Forgetting: Learning a specific task often makes the robot forget its general capabilities.
We have seen considerable progress in addressing these issues individually, but a method that solves all three simultaneously has been elusive—until now.
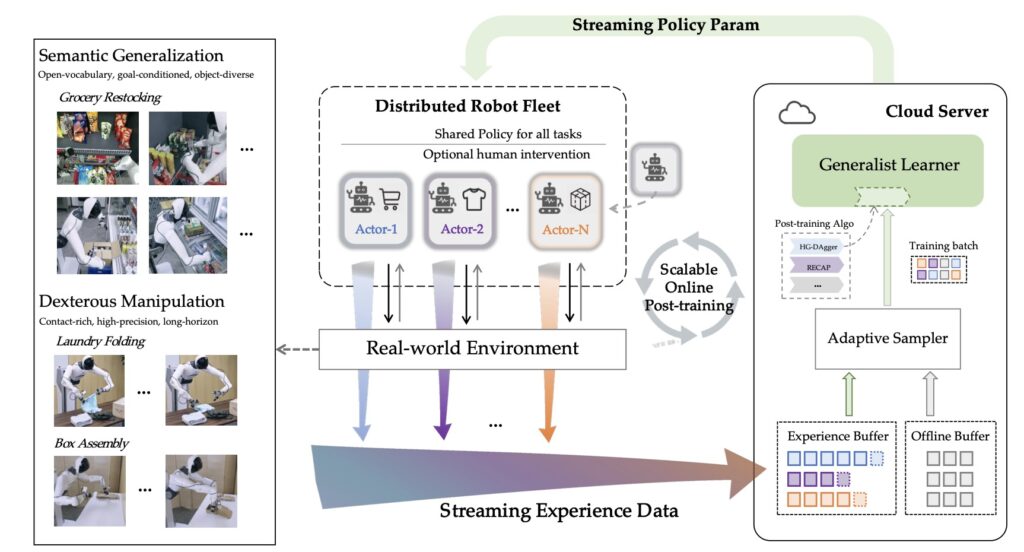
SOP: A Hive Mind for Robotics
SOP is the first system to integrate online, distributed, and multi-task learning in real-world post-training. The core philosophy is simple yet transformative: online mechanisms alleviate distribution shift, distributed architectures enable efficient exploration, and multi-task learning preserves generalization.
By shifting the learning paradigm from offline to distributed online training, SOP establishes a mechanism for efficient reuse and rapid iteration of individual experience across the fleet.
1. Multi-robot Parallel Execution
Under this architecture, multiple robots share a single VLA policy while simultaneously handling a wide variety of tasks. This approach significantly broadens the coverage of state-action distributions in the real world. It overcomes the limitations of single-machine learning by achieving parallelism in space rather than sequentiality in time.
2. Centralized Cloud Online Updates
Through centralized cloud updates, all execution trajectories, reward signals, and human corrections are streamed in real-time. Within cloud GPU clusters, the policy model undergoes continuous online updates, with optimized parameters synchronized back to all robots within minutes. This ensures the fleet is always learning from the latest “current policy.”
3. Preserving Generalization
Traditional single-machine online training often causes the model to degrade into a “specialist” that only excels at one thing. SOP prevents this. Because multi-task learning occurs simultaneously across a broader distribution, the VLA’s generality is not compromised by targeted performance improvements.

Proven Performance in the Real World
To validate SOP, we tested it against standard algorithms like HG-DAgger and RECAP. We integrated these algorithms into the SOP framework (creating SOP w/ HG-DAgger and SOP w/ RECAP) and deployed them on real-world manipulation tasks including cloth folding, box assembly, and grocery restocking.
The results were consistent: performance improved substantially across all scenarios when combined with SOP. We also found that for cloth folding and box assembly tasks, certain recovery behaviors introduced during the SOP process significantly improved task throughput. After SOP training, our robots operated autonomously on target tasks for over 36 hours without requiring human intervention.
The Mathematics of Scale: Why More Robots Mean Smarter Robots
One of the most exciting findings of our research is the relationship between fleet size and learning speed. We compared single, dual, and quad-robot configurations. The results suggest that scaling robot deployments is a form of scaling compute for learning—each additional robot accelerates policy improvement.
Performance Scaling by Fleet Size:
| Fleet Size | Success Rate (3H) | Time to 80% Performance | Speedup |
| 1 Robot | 80.5% | 173.6 min | 1.0× |
| 2 Robots | 88.7% | 126.5 min | 1.4× |
| 4 Robots | 92.5% | 71.7 min | 2.4× |
Exportovat do Tabulek
Under a 3-hour training limit, the 4-robot fleet reached a 92.5% success rate—12% higher than the single-robot configuration. More importantly, SOP translates hardware scaling into time savings. Reaching 80% performance took nearly 3 hours with one robot, but only 72 minutes with four.
On-Policy Experience vs. Offline Data
We also explored the “quality vs. quantity” debate. We compared the gains from adding massive amounts of offline pre-training data against the gains from short bursts of SOP online training.
The results were stark. SOP achieved approximately 30% performance improvement with just three hours of on-policy experience. In contrast, adding 80 hours of additional offline pre-training data only provided a 4% gain. This confirms a recurrent theme in robotics: static datasets cannot fully anticipate the state distribution induced by a deployed policy. You cannot simply “pre-train” your way to perfection; the robot must experience the physical world to master it.
The Era of Living Machines
SOP changes more than just technical techniques—it redefines the lifecycle of robotic systems. We believe that robots should not be “standardized products with fixed performance,” but rather “living entities that continuously improve in the real world.”
In this view, deployment is not the end of technical iteration, but the starting point for learning at a larger scale. If VLA gave robots their first general understanding, SOP allows the shared experience of a fleet to drive the rapid growth of intelligence. Training is no longer locked in the past; intelligence grows in the present. This is the critical step required to bring general-purpose robots out of the lab and into the real world.