The First 32B Parameter Model Trained Through Globally Distributed Reinforcement Learning
- INTELLECT-2 marks a groundbreaking achievement as the first 32-billion-parameter language model trained using globally distributed reinforcement learning, shifting away from traditional centralized training methods.
- This innovative model is supported by custom-built infrastructure like PRIME-RL, SHARDCAST, and TOPLOC, enabling asynchronous training across a diverse, decentralized network of compute contributors.
- With open-sourced code, data, and future plans for enhanced inference compute and tool integration, INTELLECT-2 paves the way for collaborative, open-source advancements in AI research.
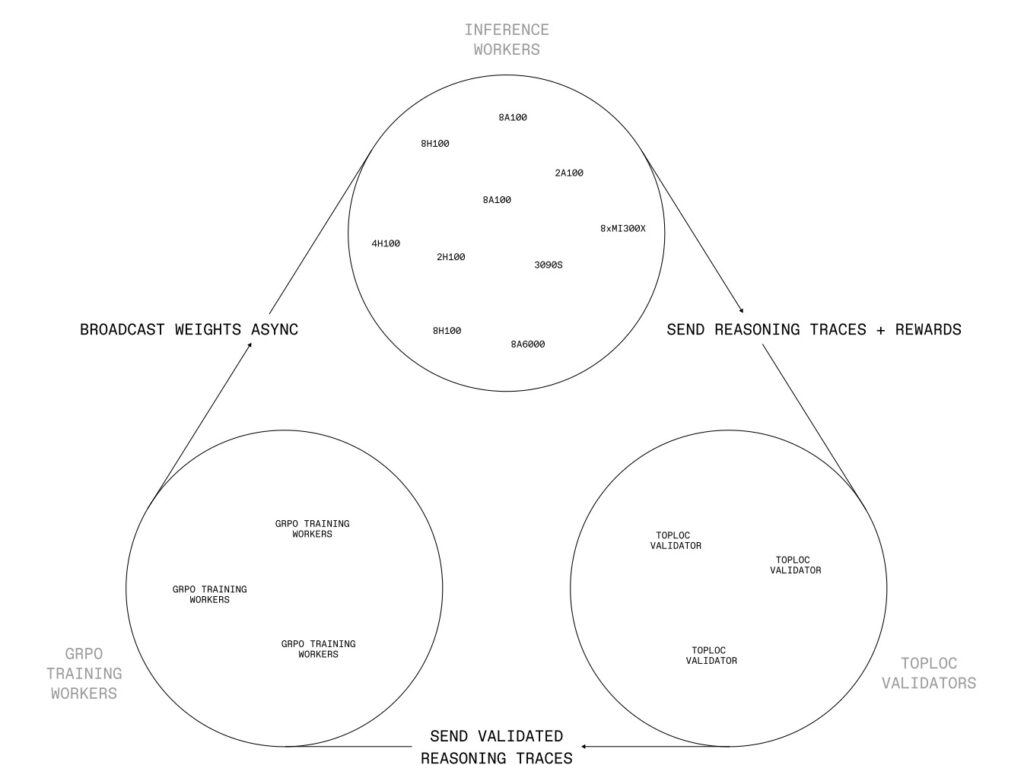
In the ever-evolving landscape of artificial intelligence, a seismic shift is underway with the release of INTELLECT-2, a 32-billion-parameter language model that redefines how we approach training large language models (LLMs). Unlike the conventional centralized training methods that rely on massive, co-located GPU clusters with high-speed interconnects, INTELLECT-2 harnesses the power of globally distributed reinforcement learning (RL). This pioneering approach leverages a dynamic, heterogeneous swarm of permissionless compute contributors, creating a paradigm shift that could democratize AI development. By training asynchronously across unreliable and diverse networks, INTELLECT-2 not only challenges the status quo but also opens new doors for scalable, decentralized AI innovation.
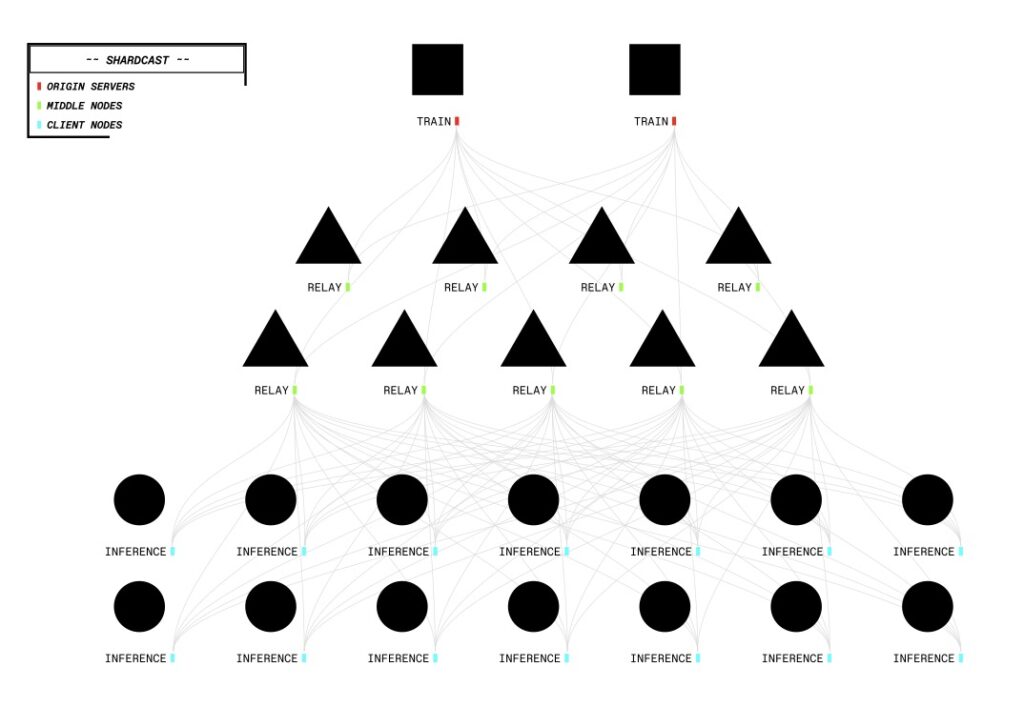
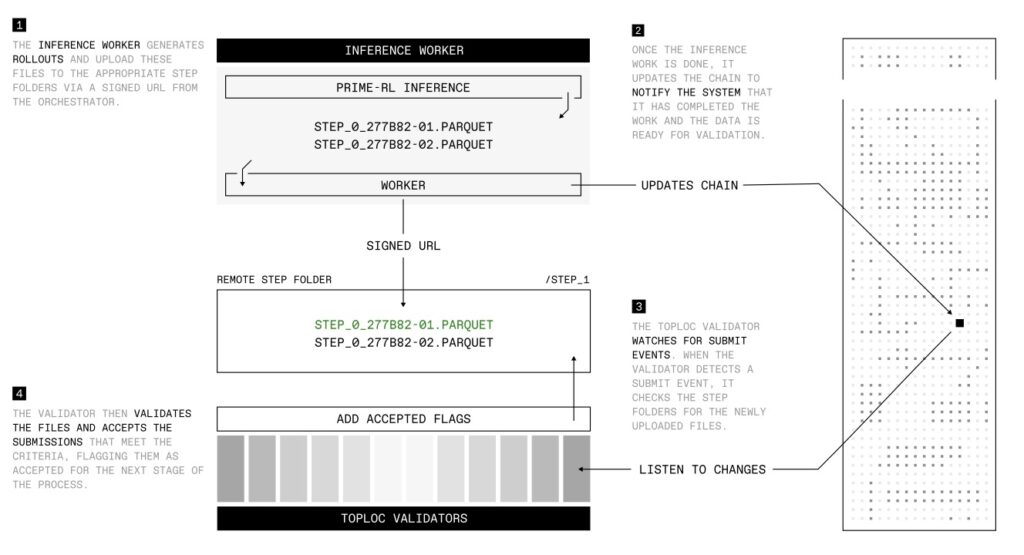
At the heart of this breakthrough lies a suite of custom-built infrastructure components designed to tackle the unique challenges of distributed RL. The cornerstone is PRIME-RL, a fully asynchronous reinforcement learning framework tailored for decentralized environments. PRIME-RL decouples critical processes like rollout generation, model training, and weight broadcasting, ensuring seamless operation across varied and often unstable networks. Built on top of PyTorch FSDP2 for training and vLLM for inference, it incorporates the GENESYS schema from SYNTHETIC-1 for verification. Complementing this framework are SHARDCAST, a library that efficiently distributes updated model weights to inference workers via an HTTP-based tree-topology network, and TOPLOC, a locality-sensitive hashing scheme for verifiable inference. TOPLOC ensures the integrity of rollouts by detecting tampering or precision changes across nondeterministic GPU hardware, with a robust validation process that accepts valid contributions and penalizes invalid ones through an on-chain event system.
Beyond the infrastructure, the journey to create INTELLECT-2 required significant adaptations to traditional RL training recipes. Modifications to the standard GRPO approach and innovative data filtering techniques were essential to achieve training stability and ensure the model met its objectives. The results speak for themselves: INTELLECT-2 demonstrates marked improvements over its predecessor, QwQ-32B, particularly in mathematics and coding benchmarks. Two key experiments, TARGET-SHORT and TARGET-LONG, highlighted the model’s capabilities with short and long target lengths, respectively. Throughout these experiments, task rewards improved significantly, reflecting enhanced performance on complex problems, while length penalties decreased, albeit more slowly than in ablation studies. This success was underpinned by efficient compute utilization, achieved by overlapping communication with computation through a two-step asynchronous RL process.
The implications of INTELLECT-2 extend far beyond its immediate performance gains. By open-sourcing the model, along with its code, data, and infrastructure components, the team behind INTELLECT-2 invites the global research community to explore decentralized training further. This move aligns with a broader vision of fostering open-source AI development, where collaborative efforts can outpace the progress of closed, proprietary labs. The release of PRIME-RL and associated tools is not just a technical contribution but a call to action for researchers and developers to contribute to a growing ecosystem of distributed RL environments and tasks.

Looking ahead, the roadmap for INTELLECT-2 and decentralized RL is brimming with potential. One key focus is increasing the ratio of inference to training compute, capitalizing on the inherently parallel and communication-free nature of inference. This approach suits decentralized setups perfectly, as methods like VinePPO, which prioritize Monte Carlo-based value estimates over value networks, and online data filtering for curriculum learning could further enhance training efficiency. Additionally, integrating tool calls—such as web search and Python interpreters—into the reasoning chain of models like INTELLECT-2 promises to unlock new capabilities for scientific and research applications, building on promising open-source research in this area.
Another exciting avenue is crowdsourcing RL tasks and environments, a domain where open-source communities can shine. Developing diverse RL environments to teach models new skills is a highly parallelizable software engineering challenge, ideally suited for community-driven efforts. The team behind INTELLECT-2 is committed to making it easy for contributors to add to PRIME-RL, envisioning a future where domain experts from around the world collaborate to build richer, more varied training landscapes. Furthermore, innovations like model merging and DiLoCo (Distributed Low-Communication) offer tantalizing possibilities for scaling decentralized RL. By fusing independently trained models—either post-training or continuously during training—researchers could create unified models capable of handling diverse reasoning tasks, potentially scaling compute resources by orders of magnitude.
INTELLECT-2 is more than a technological milestone; it is a bold step toward a future where AI development is not confined to a handful of well-funded labs but is instead a global, collaborative endeavor. While this model represents the first of its kind in decentralized RL at this scale, it is merely the beginning. Challenges remain, from optimizing inference-heavy RL recipes to ensuring robust tool integration and community engagement. Yet, with each advancement, the vision of open frontier reasoning models trained through distributed efforts comes closer to reality. As the AI community rallies around initiatives like INTELLECT-2, we stand on the brink of a new era—one where the collective brainpower of a decentralized world drives the next generation of intelligent systems.