How Managing Policy Entropy Could Revolutionize Reinforcement Learning for LLMs
- Policy entropy collapse in reinforcement learning (RL) for large language models (LLMs) severely limits exploratory capacity, leading to predictable performance ceilings and stunted reasoning gains.
- Theoretical and empirical analyses reveal that entropy dynamics are driven by the covariance between action probability and advantage, necessitating innovative management techniques like Clip-Cov and KL-Cov to sustain exploration.
- Addressing entropy collapse is pivotal for scaling RL compute, potentially transforming LLMs into more intelligent, reasoning-centric systems beyond the constraints of imitation learning.
The realm of artificial intelligence is witnessing a paradigm shift as large language models (LLMs) evolve from mere imitators of human text to sophisticated reasoning entities. At the heart of this transformation lies reinforcement learning (RL), a method that enables models to learn from experience rather than static datasets. However, a critical challenge looms large over this promising frontier: the collapse of policy entropy. This phenomenon, observed consistently across extensive RL training runs, sees a sharp decline in policy entropy early in the process, resulting in overly confident models that lose their ability to explore diverse solutions. This diminished exploratory capacity directly correlates with a saturation in performance, capping the potential of LLMs to achieve groundbreaking reasoning capabilities.
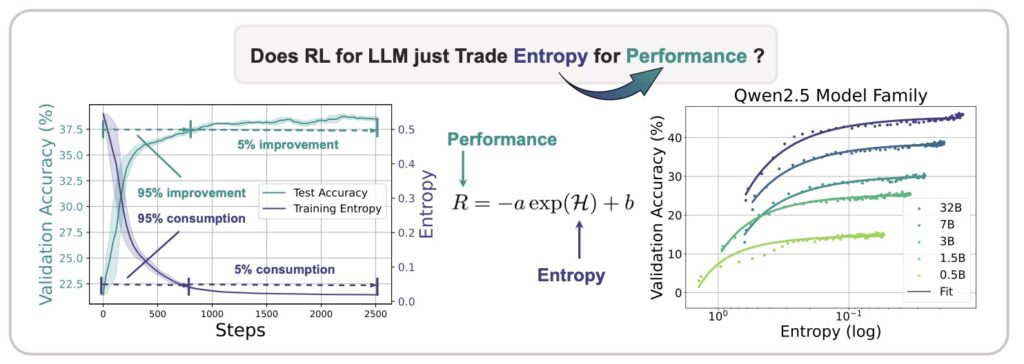
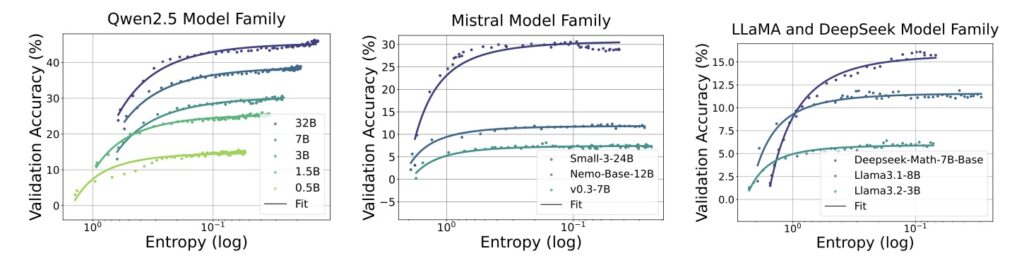
Delving deeper into this issue, researchers have uncovered a striking empirical relationship between policy entropy (H) and downstream performance (R), encapsulated in the transformation equation R = -a exp H + b, where a and b are fitting coefficients. This equation reveals a sobering truth: performance gains are often traded at the expense of entropy, meaning that as entropy approaches zero, performance hits a predictable ceiling (R = -a + b). In essence, the exhaustion of policy entropy bottlenecks the model’s ability to improve further. This finding underscores the urgent need for entropy management to ensure continuous exploration, especially as RL emerges as the next critical axis for scaling compute beyond traditional pre-training and fine-tuning methods.
To address this challenge, a comprehensive investigation into entropy dynamics offers both theoretical and empirical insights. The theoretical derivation highlights that the change in policy entropy is driven by the covariance between action probability and the change in logits, which is proportional to the advantage in Policy Gradient-like algorithms. Simply put, a high-probability action with a high advantage reduces policy entropy, while a rare action with a high advantage increases it. Empirical studies reinforce this conclusion, showing an exact match between the covariance term and entropy differences, with the covariance term remaining predominantly positive throughout training. This persistent positivity explains the monotonic decrease in policy entropy, as the model increasingly favors high-probability actions, further limiting exploration.
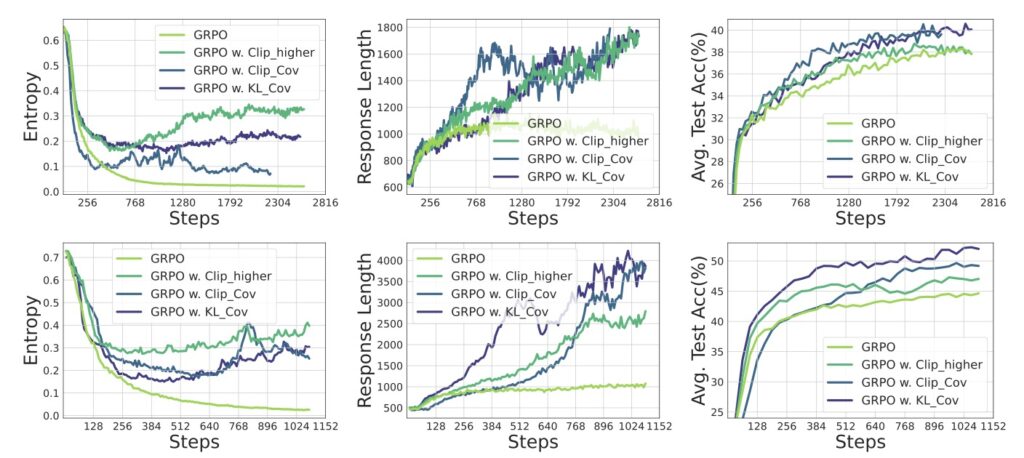
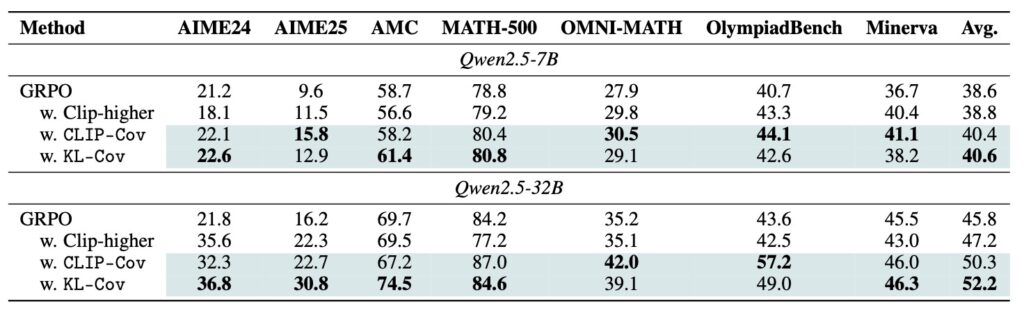
Understanding these mechanisms has paved the way for innovative solutions to counteract entropy collapse. Two novel techniques, Clip-Cov and KL-Cov, have been proposed to manage entropy by targeting high-covariance tokens—those most responsible for entropy reduction. Clip-Cov clips the updates of these tokens to prevent excessive confidence, while KL-Cov applies a Kullback-Leibler (KL) divergence penalty to maintain diversity in action selection. Experiments demonstrate that both methods effectively encourage exploration, helping the policy escape the trap of entropy collapse and achieve superior downstream performance. These approaches mark a significant step forward in ensuring that RL-trained LLMs retain the flexibility to explore a vast landscape of possibilities, rather than converging prematurely on suboptimal solutions.
The implications of this research extend far beyond the immediate challenge of entropy management. RL’s potential to serve as a new scaling axis for LLMs introduces a broader exploratory landscape, as evidenced by recent reasoning gains reported by leading AI research groups like OpenAI and DeepSeek-AI. Unlike imitation learning, which confines models to task-specific patterns, RL empowers LLMs with sweeping generalization capabilities, enabling them to tackle complex reasoning tasks with unprecedented proficiency. Yet, scaling compute for RL remains non-trivial, with entropy collapse representing just one of many hurdles. The insights gained from studying entropy dynamics provide a foundation for addressing these broader challenges, potentially unlocking a higher level of intelligence in reasoning-centric models.

The journey to fully harness RL for LLMs is only beginning. While techniques like Clip-Cov and KL-Cov offer promising avenues for sustaining exploration, they are but pieces of a larger puzzle. Scaling RL compute demands a holistic approach that transcends entropy minimization, encompassing advancements in algorithmic design, computational efficiency, and model architecture. The ultimate goal is to foster LLMs that not only mimic human reasoning but surpass it, achieving a level of cognitive flexibility that mirrors true intelligence. By shedding light on the entropy enigma, this research serves as a beacon for future explorations, guiding the AI community toward a horizon where reinforcement learning redefines the boundaries of what language models can achieve.