A novel prompting strategy opens up new possibilities for LLMs in the recommendation domain
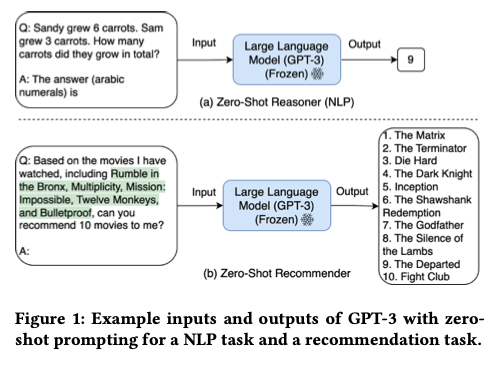
Large language models (LLMs), such as GPT-3, have shown remarkable zero-shot performance in various natural language processing (NLP) tasks. However, their potential for next-item recommendations in a zero-shot setting remains untapped. In their paper, Wang and Lim identify two primary challenges in utilizing LLMs for recommendations: the large recommendation space and the absence of knowledge about the target user’s past interactions and preferences.
Key Points:
- Large language models (LLMs) have demonstrated impressive zero-shot performance in NLP tasks, but their potential in next-item recommendations remains unexplored.
- The proposed Zero-Shot Next-Item Recommendation (NIR) prompting strategy overcomes the challenges of large recommendation spaces and limited user preference knowledge.
- The three-step prompting process involves capturing user preferences, selecting representative items, and recommending a ranked list of movies.
- The approach is evaluated using GPT-3 on the MovieLens 100K dataset, showing strong zero-shot performance and outperforming some sequential recommendation models.
- The promising results open up new research opportunities for LLMs as recommenders in various domains and settings.
To overcome these challenges, the researchers propose a prompting strategy called Zero-Shot Next-Item Recommendation (NIR). This approach involves using an external module to generate candidate items based on user-filtering or item-filtering. The three-step prompting process guides GPT-3 to capture user preferences, select representative previously watched movies, and recommend a ranked list of 10 movies.
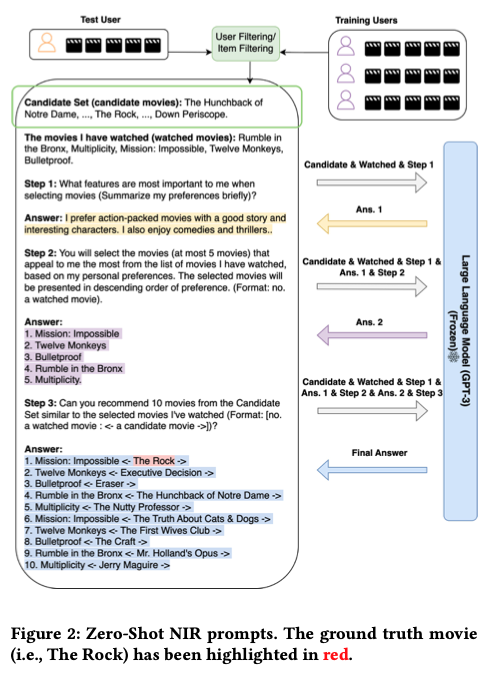
The researchers evaluate their proposed approach using GPT-3 on the MovieLens 100K dataset. The results demonstrate strong zero-shot performance, with the NIR prompting strategy even outperforming some sequential recommendation models trained on the entire training dataset.
The promising findings of this study highlight the potential for using LLMs as recommenders and open up new research opportunities in the recommendation domain. Future work can explore applying LLMs to recommendation tasks in other domains and in few-shot settings.