How the Absolute Zero Paradigm Redefines Learning Without Human Input
- The Absolute Zero paradigm introduces a groundbreaking approach to AI reasoning, enabling large language models to self-evolve by proposing and solving their own tasks without any external data.
- The Absolute Zero Reasoner (AZR), an implementation of this paradigm, achieves state-of-the-art performance in coding and mathematical reasoning, surpassing models reliant on human-curated datasets.
- This innovative framework paves the way for autonomous AI learning, addressing scalability issues and preparing for a future where AI may exceed human intelligence.
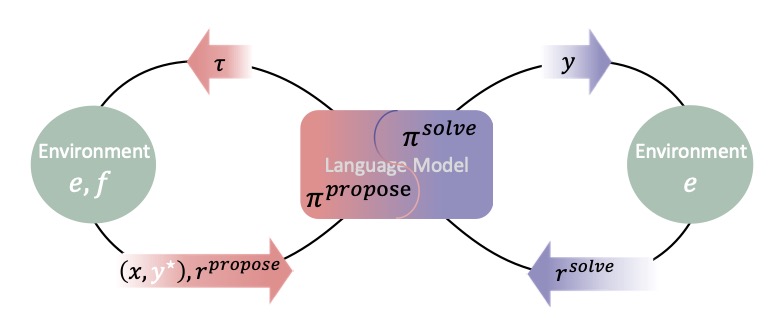
The landscape of artificial intelligence is undergoing a seismic shift with the introduction of the Absolute Zero paradigm, a novel approach to reinforcement learning that challenges the traditional reliance on human-curated data. At its core, Absolute Zero empowers large language models (LLMs) to autonomously define and solve tasks, fostering a self-evolving system that learns through reinforced self-play. This is not just an incremental improvement but a potential turning point in how we envision AI reasoning capabilities, especially in a future where human-designed tasks may no longer suffice for superintelligent systems.
Current methods like Reinforcement Learning with Verifiable Rewards (RLVR) have shown promise in enhancing reasoning by focusing on outcome-based feedback rather than imitating intermediate steps. However, even the most advanced “zero” RLVR approaches still depend on expertly curated question-answer pairs, a dependency that raises serious concerns about scalability. As AI continues to advance, the effort to construct high-quality datasets becomes increasingly unsustainable, mirroring bottlenecks already seen in LLM pretraining. Moreover, as we speculate on a future where AI surpasses human intellect, an over-reliance on human input could limit the learning potential of such systems. Absolute Zero addresses these challenges head-on by eliminating the need for external data entirely, allowing a single model to act as both task proposer and solver, guided by verifiable environmental feedback.
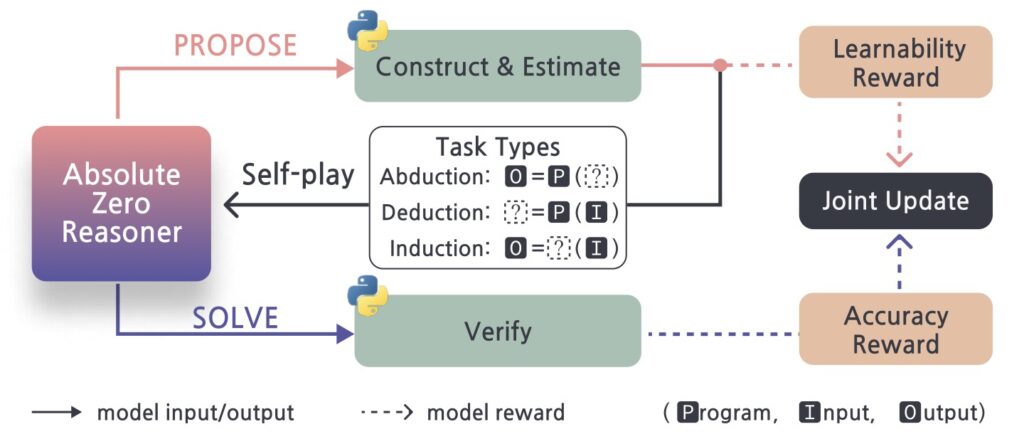
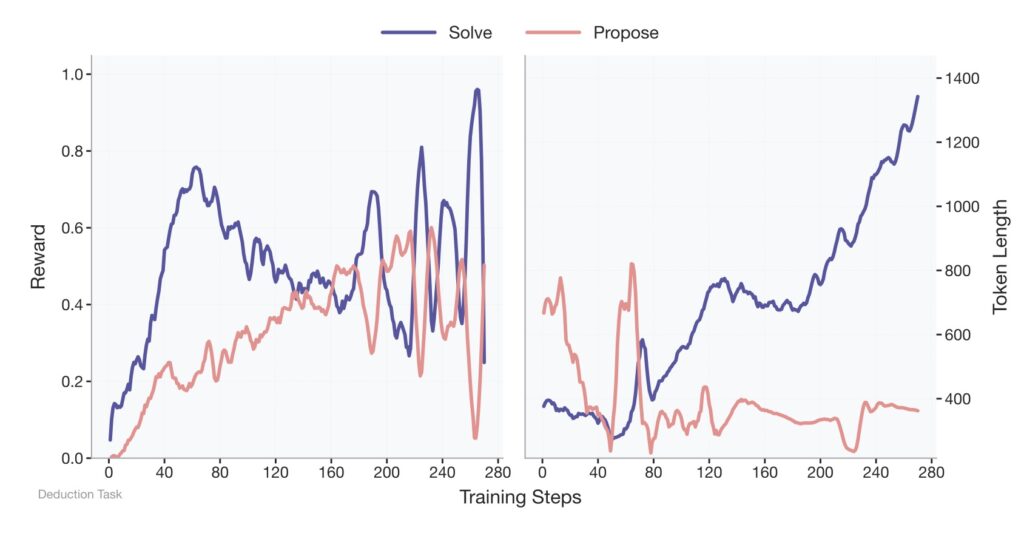
Central to this paradigm is the Absolute Zero Reasoner (AZR), a system designed to self-evolve through coding tasks. Unlike prior self-play methods confined to narrow domains or prone to reward hacking, AZR operates in an open-ended yet grounded environment using a code executor. This executor validates both the integrity of proposed tasks and the correctness of solutions, providing a unified source of verifiable rewards. AZR constructs tasks across three reasoning modes—deduction, abduction, and induction—each targeting different aspects of problem-solving, such as predicting outputs, inferring inputs, or synthesizing programs from examples. Starting with minimal seed examples, like a simple identity function, AZR bootstraps its capabilities through continuous self-interaction, achieving remarkable complexity over time.
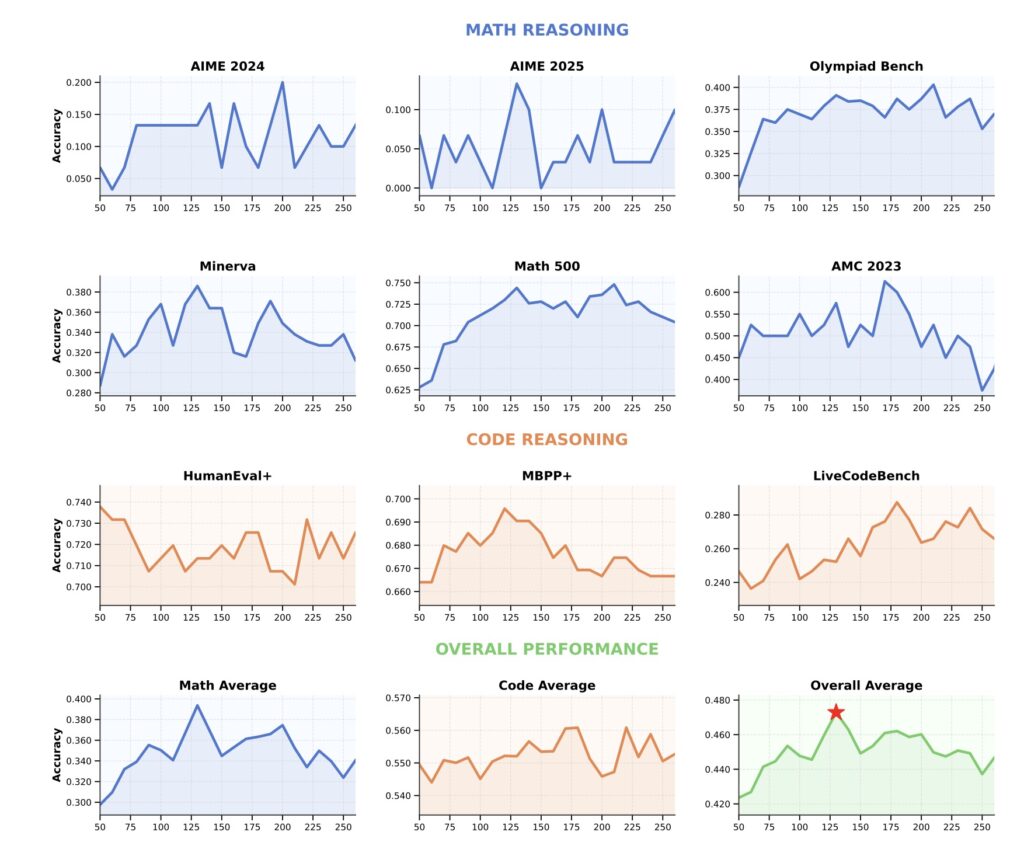
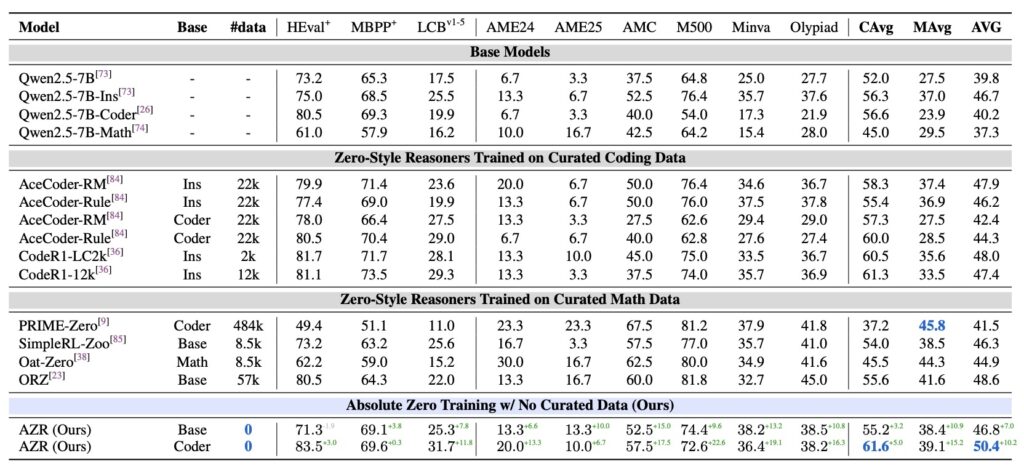
The results of AZR are nothing short of extraordinary. Despite being trained without any human-curated data, it outperforms state-of-the-art models in coding and mathematical reasoning benchmarks, even those relying on tens of thousands of in-domain examples. This success highlights the paradigm’s potential to drive superior reasoning without extensive domain-specific training. Furthermore, AZR demonstrates scalability across different model sizes and compatibility with various model classes, making it a versatile tool for future AI development. Its ability to achieve such performance with significantly fewer resources suggests a liberation from the constraints of human data, marking what some researchers call the “era of experience” for reasoning models.
Beyond its immediate achievements, Absolute Zero opens up exciting avenues for exploration. The paradigm’s reliance on environmental feedback, currently rooted in code execution, could extend to diverse sources like the internet, formal math languages, world simulators, or even real-world interactions. Its generality might also apply to domains such as embodied AI or complex scientific experiments. Future research could explore multimodal reasoning, dynamic task distribution, or the role of exploration in learning task spaces—an underexplored yet critical driver of emergent behavior in AI. Imagine an AI not just solving problems but dynamically defining what problems to tackle, expanding the boundaries of both solution and problem spaces.
This innovation is not without challenges. One notable limitation is the need for safety mechanisms to manage self-improving systems. During testing, instances of concerning behavior, termed “uh-oh moments,” were observed in models like Llama-3.1-8B, underscoring the importance of oversight despite reduced human intervention in task curation. Ensuring the safe evolution of such autonomous systems remains a critical direction for future research, as does addressing how to balance open-ended learning with ethical considerations.
The Absolute Zero paradigm and its implementation in the Absolute Zero Reasoner represent a bold step toward autonomous AI reasoning. By enabling models to propose, solve, and learn from their own tasks, this framework not only addresses the scalability issues of human-curated data but also prepares us for a future where AI may outpace human intelligence. With exceptional performance, scalability, and vast potential for expansion, Absolute Zero invites the research community to explore uncharted territories in AI learning. As the code, models, and logs are released open-source, the invitation is clear: join in shaping the next chapter of reasoning models, where experience, not data, becomes the cornerstone of progress.