Code Model Training with Reinforcement Learning and Automated Test-Case Generation
- Unlocking RL Potential in Code Models: ACECODER addresses the untapped potential of reinforcement learning (RL) in coder models by introducing automated large-scale test-case synthesis.
- Innovative Training Pipeline: A novel pipeline generates extensive (question, test-case) pairs, enabling the training of reward models and coder models with significant performance improvements.
- Pioneering Results and Future Directions: ACECODER demonstrates substantial gains in coding benchmarks, paving the way for future advancements in RL-based coder training.
The field of AI-driven coding has seen remarkable progress, with supervised fine-tuning (SFT) leading the charge in training coder models. However, the potential of reinforcement learning (RL) in this domain remains largely unexplored. The primary challenge? A lack of reliable reward data and models tailored to the complexities of code generation. Enter ACECODER, a groundbreaking approach that leverages automated test-case synthesis to unlock the power of RL for coder models. This article delves into the methodology, results, and implications of this innovative work.
RL in Code Models
While RL has shown promise in other domains, its application in coding has been hindered by the absence of robust reward mechanisms. Unlike traditional tasks, where rewards can be easily defined, coding requires nuanced evaluation metrics that account for correctness, efficiency, and functionality. Without reliable reward data, RL struggles to compete with SFT, which relies on vast amounts of labeled data. ACECODER tackles this issue head-on by automating the generation of test cases, creating a scalable and verifiable reward system for coder models.
Automating Test-Case Synthesis
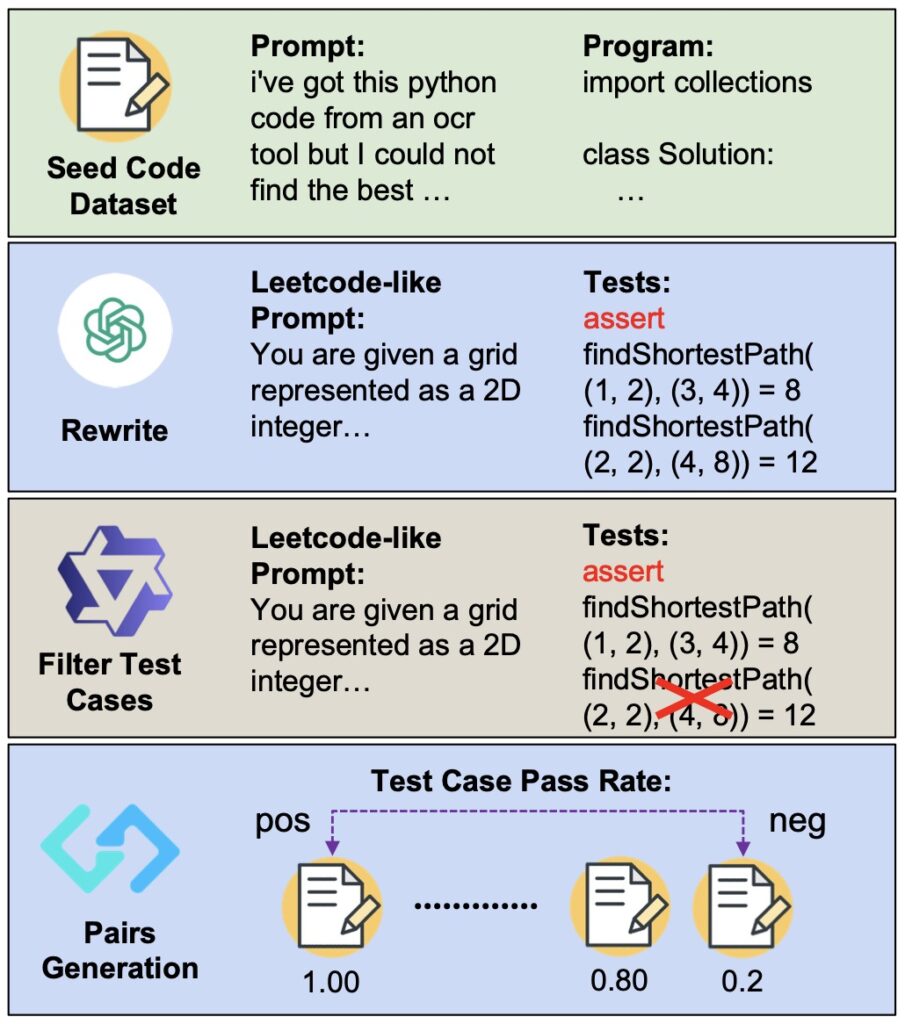
At the heart of ACECODER lies a sophisticated pipeline designed to generate extensive (question, test-case) pairs from existing code data. This process involves:
- Large-Scale Test-Case Generation: By synthesizing diverse and comprehensive test cases, the pipeline ensures robust evaluation of code outputs.
- Reward Model Training: Using the generated test cases, preference pairs are constructed based on pass rates over sampled programs. These pairs are then used to train reward models with the Bradley-Terry loss function.
- Reinforcement Learning Integration: The reward models, combined with test-case pass rates, enable RL training that consistently improves coder model performance across multiple benchmarks.
This automated approach not only addresses the lack of reward data but also ensures high-quality, verifiable code data for training.
A Leap Forward in Coder Model Performance
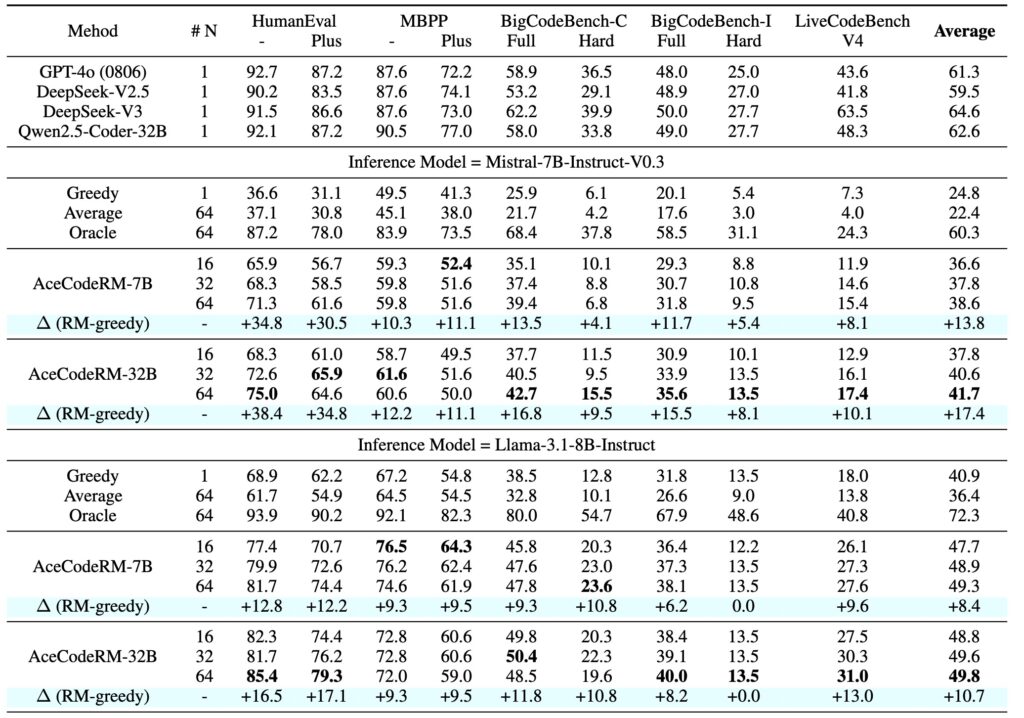
ACECODER’s impact is evident in its results. By applying the pipeline to models like Llama-3.1-8B-Ins and Qwen2.5-Coder-7B-Ins, the team achieved:
- Significant Performance Gains: A 10-point improvement for Llama-3.1-8B-Ins and a 5-point improvement for Qwen2.5-Coder-7B-Ins through best-of-32 sampling. Remarkably, the 7B model’s performance was on par with the 236B DeepSeek-V2.5.
- Enhanced RL Training: Starting from Qwen2.5-Coder-base, RL training improved HumanEval-plus scores by over 25% and MBPP-plus scores by 6% in just 80 optimization steps.
- Broad Benchmark Success: Consistent improvements were observed across HumanEval, MBPP, BigCodeBench, and LiveCodeBench (V4), showcasing the versatility of the approach.
These results highlight the transformative potential of RL in coder models, even when starting from smaller, less advanced models.
Implications and Future Directions
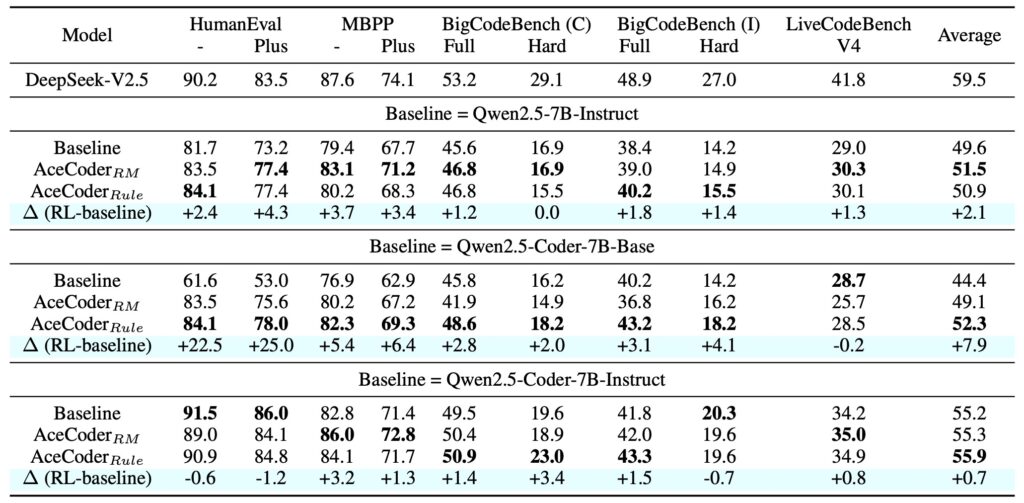
ACECODER’s success underscores the importance of automated test-case synthesis in advancing RL-based coder training. By providing a scalable and verifiable reward system, the approach bridges the gap between SFT and RL, unlocking new possibilities for code model development. However, the work also reveals areas for improvement:
- Reward Model Robustness: While the pipeline delivers impressive results, the RL training improvements are less pronounced compared to best-of-N experiments. Future research should focus on enhancing reward model training to achieve greater robustness and reliability.
- Scalability and Generalization: Expanding the pipeline to handle more diverse coding tasks and languages could further enhance its impact.
ACECODER represents a significant step forward in the evolution of coder models. By addressing the challenges of RL in the code domain through automated test-case synthesis, it demonstrates the untapped potential of reinforcement learning. The results speak for themselves: substantial performance gains, scalable methodologies, and a roadmap for future advancements. As the first work to automate large-scale test-case synthesis for coder models, ACECODER sets a new standard for innovation in AI-driven coding.