How Generative AI is Reshaping Information Access—and Leaving Traditional Sites in the Dust
- Wikipedia’s Plunge: The nonprofit encyclopedia sees an 8% drop in human visitors, blamed on AI tools like ChatGPT and Google’s AI Overviews delivering instant answers without clicks.
- Publishers’ Backlash: News outlets from MailOnline to Rolling Stone report massive traffic losses and even lawsuits, as AI scrapes content without fair referrals.
- Google’s Defense: The search giant claims users are “happier” and searching more, with AI summaries boosting deeper engagement and billions of daily clicks to sites.
In the rapidly evolving digital landscape, artificial intelligence is not just a tool—it’s a disruptor that’s fundamentally altering how we consume information. What was once a web of interconnected sites, with Wikipedia as a cornerstone of free knowledge, is now being streamlined by AI-generated summaries that promise quick answers at the expense of original sources. This shift has sparked a heated debate: Is AI making the internet more efficient and user-friendly, or is it quietly eroding the ecosystem that sustains quality content? At the heart of this tension is Wikipedia’s recent revelation of plummeting visitor numbers, a symptom of broader changes rippling through publishers and search engines alike.
Wikipedia’s Alarming Traffic Decline
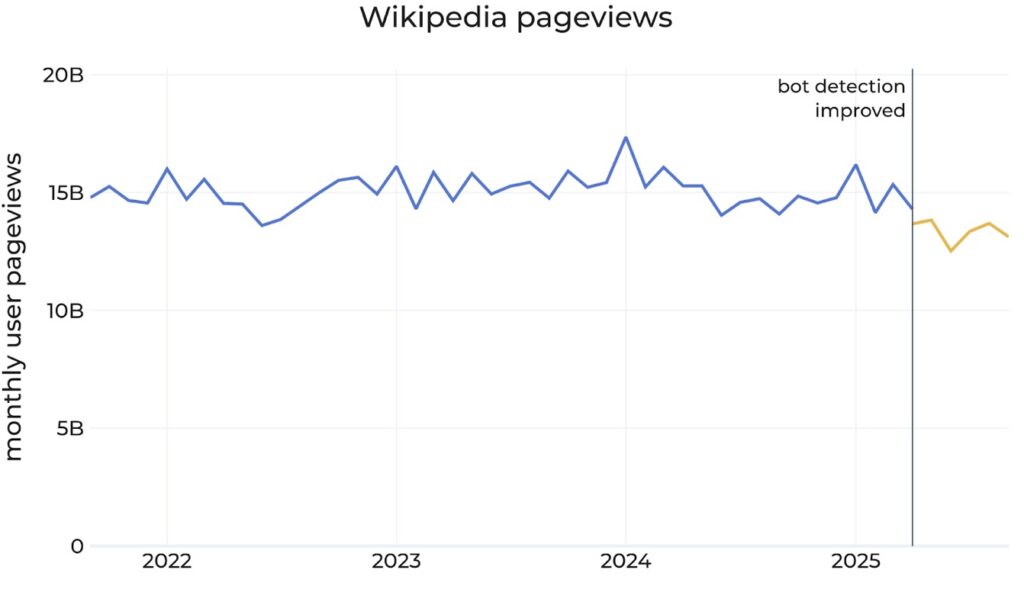
Wikipedia, the beloved nonprofit encyclopedia that’s long served as the go-to source for factual overviews, has become an unlikely casualty in the AI revolution. According to the Wikimedia Foundation, which operates the site, human traffic has declined by a staggering 8% year-on-year. This drop wasn’t immediately apparent; it only surfaced after the foundation refined its bot detection systems to better distinguish between automated scrapers and real users. In a candid blog post, Marshall Miller, a Wikimedia executive, explained that the revisions revealed a troubling trend: over the past few months, human pageviews have fallen roughly 8% compared to the same period in 2024. “We believe that these declines reflect the impact of generative AI and social media on how people seek information,” Miller wrote, pointing the finger squarely at search engines that now provide direct answers—often drawn from Wikipedia’s own content—rather than linking back to the source.
The Ripple Effect on Publishers and the Open Web
This isn’t an isolated incident for Wikipedia. The broader web publishing industry is reeling from similar blows. Generative AI tools, powered by large language models, are trained on vast troves of online content, including articles from news giants. When users query these systems, they receive synthesized responses that bypass the original sites entirely. Take DMG Media, the parent company of high-traffic outlets like MailOnline and Metro. In a July statement to the UK’s Competition and Markets Authority, the publisher reported that Google’s AI Overviews—a feature that generates AI-powered summaries atop search results—had slashed click-through rates by an eye-watering 89%. This means fewer readers arriving at their sites, translating to lost ad revenue and diminished visibility for journalists’ hard work. It’s a pattern echoed across the sector: AI is feasting on content without giving back the traffic that fuels creation.
The frustration has escalated to legal action. Penske Media Corporation, which owns Rolling Stone and a portfolio of entertainment and music publications, filed a lawsuit against Google last month. The suit alleges that AI-generated summaries of their articles are not only reducing traffic but also misrepresenting content in ways that harm their brand. Publishers argue that tech firms are essentially freeloaders, trawling the web for data to build profitable AI features while starving the very sources that make those features possible. From a broader perspective, this raises profound questions about the sustainability of the open web. If AI intermediaries become the default gateway to knowledge, who funds the human-driven research, editing, and verification that underpin reliable information? Wikipedia, funded largely through donations and reliant on volunteer editors, exemplifies the vulnerability of nonprofit models in this new era.
Google’s Counterarguments and the User Experience Debate
Enter Google, the behemoth at the center of the storm, which has pushed back vigorously against the criticism. In an August blog post, Liz Reid, head of Google Search, painted a rosy picture of AI’s integration into search. “Our data shows people are happier with the experience and are searching more than ever as they discover what Search can do,” she asserted. Google’s stance is that AI Overviews act as a helpful “lay of the land,” encouraging users to click through for deeper dives rather than replacing them. Reid emphasized that while overall traffic to websites remains “relatively stable,” the web’s vastness means shifts are inevitable—some sites lose out, while others gain. Crucially, she highlighted that Google still sends “billions of clicks to websites every day,” maintaining what the company calls a “strong value exchange” with the web. From Google’s vantage point, AI isn’t a thief; it’s an enhancer that democratizes access to information, making searches faster and more intuitive for billions of users worldwide.
Yet, this optimism clashes with the ground-level realities reported by affected sites. Critics, including Wikimedia and major publishers, contend that the “value exchange” is increasingly lopsided. AI tools like ChatGPT, which has exploded in popularity since its 2022 launch, and Google’s own Bard (now Gemini) are pulling users away from direct visits. A 2024 study by Similarweb, an analytics firm, corroborated this by noting a 15-20% dip in organic search traffic for encyclopedic and informational sites post-AI rollout. Broader implications extend beyond traffic: as AI hallucinates facts or summarizes inaccurately—drawing from potentially outdated or biased Wikipedia entries—the risk of misinformation rises. Wikipedia’s volunteer editors, already stretched thin, now face the added burden of combating AI-fueled distortions of their work.
Navigating the Future: Regulation, Coexistence, and the Soul of the Internet
The clash between AI innovators and content creators underscores a pivotal moment for the internet. Regulatory bodies like the UK’s Competition and Markets Authority are scrutinizing these dynamics, with calls for fairer compensation models, such as revenue-sharing from AI queries. The European Union’s AI Act, effective from 2024, mandates transparency in how AI systems use training data, potentially forcing tech giants to cite and link sources more robustly. Meanwhile, experiments like Wikipedia’s own AI integrations—such as chatbots for quick queries—suggest a path toward coexistence. For users, the “happier experience” Google touts may indeed streamline daily searches, but it comes at the cost of a richer, more exploratory web.