AI Applications with Speed, Cost-Efficiency, and Multimodal Intelligence
- Introducing Nova: Amazon’s Nova family of multimodal AI models, launched at re:Invent, includes text, image, and video generation capabilities optimized for speed and affordability.
- Expanding Boundaries: Nova models like Canvas and Reel bring generative AI to visual and video content, offering industry-leading price-performance and creative versatility.
- Future Innovation: Amazon plans to release speech-to-speech and “any-to-any” modality models by 2025, aiming to redefine multimodal AI applications.
Amazon Web Services (AWS) is propelling artificial intelligence into a new era with its groundbreaking Nova family of multimodal AI models. Announced at AWS’s re:Invent conference, Nova delivers state-of-the-art performance across text, image, and video generation tasks. Designed to empower enterprise customers, Nova combines industry-leading speed, cost-efficiency, and flexibility to tackle complex AI workflows, ranging from document analysis to creative content generation.
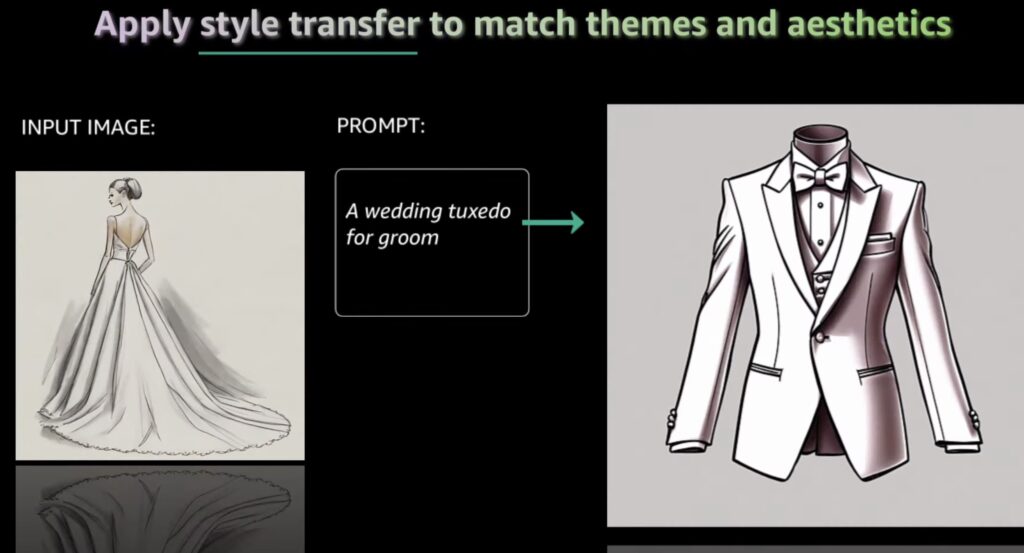
With Nova, Amazon positions itself as a frontrunner in the generative AI market, offering robust alternatives to competitors like OpenAI and Google while expanding the capabilities available on AWS Bedrock, its AI development platform.
The Nova Family: Models for Every Need
The Nova lineup features four text-generating models—Micro, Lite, Pro, and Premier—tailored for diverse applications, alongside two creative models, Canvas and Reel:
Micro: A text-only model optimized for ultra-fast responses with minimal latency. Its compact context window processes up to 128,000 tokens, suitable for real-time applications.
Lite: A multimodal model that processes text, image, and video inputs at lightning speed, balancing cost and performance.
Pro: Offers advanced accuracy and efficiency for a broad range of tasks, excelling at multimodal document and video analysis.
Premier: The most powerful model, designed to train custom AI solutions for complex reasoning and tailored enterprise use cases.
Canvas and Reel elevate Nova’s creative potential. Canvas generates studio-quality images with customizable layouts, while Reel creates six-second videos from text prompts, with longer video capabilities expected soon.
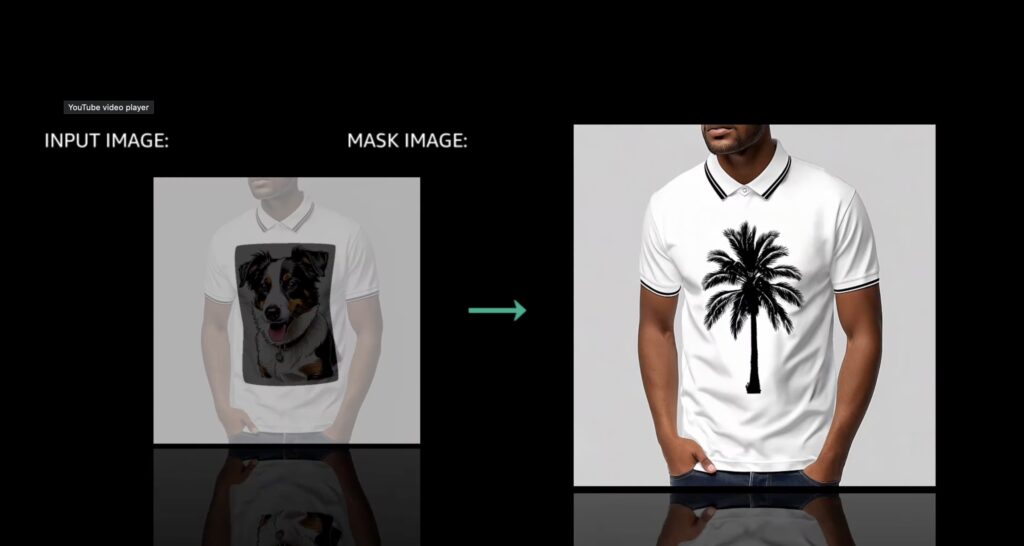
Why Nova Stands Out
Nova’s competitive edge lies in its blend of performance, versatility, and affordability:
- Speed and Cost-Efficiency: Nova models are at least 75% less expensive than comparable models in their class and deliver industry-leading speed. For instance, Nova Micro outputs 210 tokens per second, outperforming rivals like Meta’s LLaMa and Google’s Gemini in benchmark tests.
- Multimodal Flexibility: With support for text, images, and video inputs, Lite and Pro models unlock new possibilities for cross-functional applications. A context window expansion to over 2 million tokens by 2025 will further enhance Nova’s capabilities.
- Creative Power: Nova Canvas and Reel stand out as next-generation tools for image and video creation, outperforming counterparts like DALL-E 3 and Runway Gen-3 in quality and usability.
Applications Across Industries
Nova models are already transforming workflows across diverse sectors:
- Marketing and Media: Nova Canvas and Reel accelerate content creation for advertising and campaigns, cutting development time from weeks to days.
- E-Commerce: Tools like Canvas and Reel empower businesses to generate tailored product visuals and promotional videos.
- Enterprise AI: Models like Pro and Premier enable companies like Palantir to optimize decision-making and automate complex processes.
- Creative Platforms: Shutterstock and Musixmatch are using Nova models to enhance content offerings for creators, delivering personalized and high-quality visuals and videos.
Looking Ahead: A Multimodal Future
Amazon is charting an ambitious course for Nova’s evolution. In early 2025, AWS will debut a speech-to-speech model capable of interpreting verbal and non-verbal cues, promising lifelike conversational AI. By mid-2025, an “any-to-any” multimodal model will enable seamless input and output across text, speech, images, and video, opening doors to applications in translation, content editing, and advanced AI assistants.
A Bold Step for AI
With Nova, Amazon solidifies its position at the forefront of generative AI innovation. By combining speed, affordability, and cutting-edge multimodal capabilities, Nova is not just a technological achievement but a blueprint for the future of AI applications. Whether in enterprise, marketing, or creative domains, Nova models promise to redefine what’s possible in AI-driven workflows, setting a new standard for performance and accessibility.