A revolutionary approach to single and multi-subject text-to-image generation that retains fidelity and aligns seamlessly with textual input.
- Unified Approach: AnyStory introduces a unified method to generate high-fidelity personalized images for single and multiple subjects using advanced encoders and routing mechanisms.
- Advanced Techniques: Leveraging ReferenceNet and CLIP vision encoder, AnyStory ensures subject fidelity and seamless alignment with text descriptions.
- Future Potential: While limitations like background consistency and occasional “copy-paste” effects exist, the framework sets the stage for broader applications in personalized image generation.

Text-to-image generation has witnessed groundbreaking advancements with large-scale generative models, but challenges persist in achieving personalized and high-quality imagery, especially when dealing with multiple subjects. Alibaba’s AnyStory emerges as a game-changing solution, offering a unified framework that not only excels in single-subject personalization but also addresses the complexities of multiple-subject scenarios.
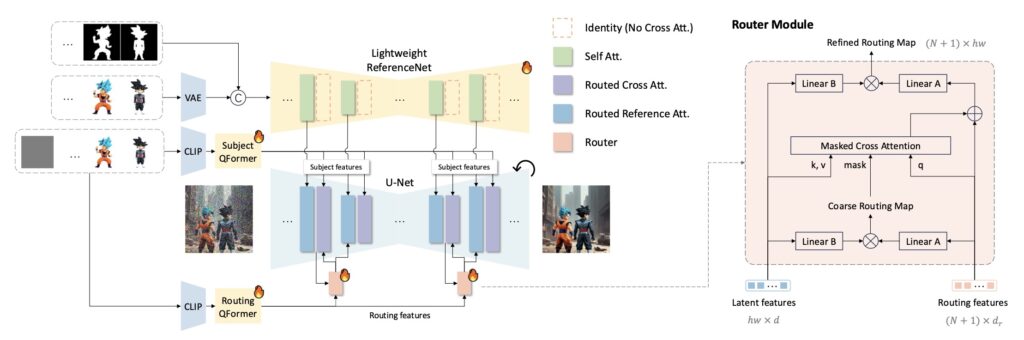
At its core, AnyStory leverages a novel “encode-then-route” architecture to retain subject details and seamlessly align with textual descriptions. This approach combines powerful encoders and routing mechanisms to inject subject-specific conditions into the generation process, making it a standout in the field.
How AnyStory Works
AnyStory’s innovation lies in its two-step personalization process:
- Encoding Step: The framework employs ReferenceNet, a universal image encoder, alongside the CLIP vision encoder to extract high-fidelity subject features. This ensures detailed and accurate subject representation, a key aspect of personalized image generation.
- Routing Step: A decoupled, instance-aware subject router is utilized to predict subject positions in the latent space and guide the injection of subject-specific conditions. This routing module excels at handling both single and multiple subject scenarios, ensuring flexibility and accuracy.

Experimental Excellence
Experiments conducted using AnyStory highlight its exceptional ability to retain intricate subject details, adhere to textual inputs, and manage multiple subjects in a single image. Unlike many existing models, AnyStory avoids trade-offs between subject fidelity and image quality, making it a robust choice for applications requiring high personalization.

However, AnyStory currently lacks the capability to generate personalized backgrounds, an area the developers aim to address in future iterations. The presence of occasional “copy-paste” effects in generated subjects also suggests room for refinement through data augmentation and enhanced generative models.

Looking Ahead
While AnyStory already sets a high bar for personalized text-to-image generation, its potential for growth is vast. Expanding its control capabilities to include background consistency and addressing current limitations could make AnyStory a comprehensive solution for sequential and dynamic image generation.

Alibaba’s commitment to innovation, as demonstrated by AnyStory, signifies a promising future where personalized imagery meets high-fidelity generative capabilities. This milestone marks not just a step forward for text-to-image technology but a leap toward making AI-driven content creation more accessible, customizable, and impactful.
