New Apple AI Models Outperform Competitors Mistral and Hugging Face
- Apple releases DCLM models on Hugging Face, featuring 7 billion and 1.4 billion parameter variants.
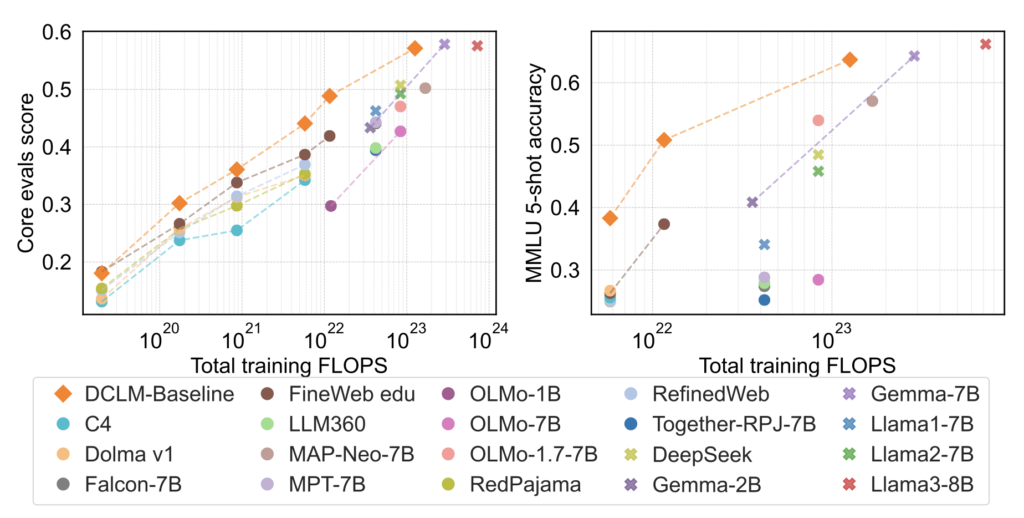
- The 7B model surpasses Mistral-7B and rivals leading open-source models in benchmark performance.
- Models emphasize the importance of high-quality data curation, trained using advanced filtering techniques.
Apple has made a significant entry into the open-source AI landscape with the release of its DataComp for Language Models (DCLM) on Hugging Face. This new family of models includes two core versions, one with 7 billion parameters and a smaller variant with 1.4 billion parameters. These models are part of a broader effort by Apple to enhance the efficiency and performance of AI through meticulous data curation.
The Power of Data Curation
The DataComp project is a collaborative initiative involving researchers from Apple, the University of Washington, Tel Aviv University, and the Toyota Institute of Research. The primary goal of this project is to design high-quality datasets specifically for training AI models in the multimodal domain. The approach centers on using a standardized framework that includes fixed model architectures, training code, hyperparameters, and evaluation metrics to conduct various experiments. These experiments aim to identify the best data curation strategies for training highly performant models.
One of the key findings from this research is the effectiveness of model-based filtering. This technique involves using machine learning models to automatically filter and select high-quality data from larger datasets. The curated dataset, named DCLM-Baseline, was utilized to train the new DCLM decoder-only transformer English language models.
Model Performance and Benchmarks
The 7B model, trained on 2.5 trillion tokens using pretraining recipes from the OpenLM framework, features a 2K context window and achieves 63.7% accuracy on the MMLU benchmark. This performance represents a 6.6 percentage point improvement over the previous state-of-the-art MAP-Neo model, while also requiring 40% less compute for training. The model’s performance is comparable to other leading open models with open weights but closed data, such as Mistral-7B-v0.3, Llama3 8B, Google’s Gemma, and Microsoft’s Phi-3.
Further improvements were observed when the context length of the model was extended to 8K through an additional 100 billion tokens of training on the same dataset using the Dataset Decomposition technique. However, the MMLU performance remained consistent.
The smaller 1.4B model, co-trained with Toyota Research Institute on 2.6 trillion tokens, also delivers impressive results. It scored 41.9% on the 5-shot MMLU test, outperforming other models in its category, including Hugging Face’s SmolLM, Qwen-1.5B, and Phi-1.5B.
Accessibility and Licensing
Apple has made these models truly open-source by releasing the model weights, training code, and pretraining dataset. The larger 7B model is available under Apple’s Sample Code License, while the smaller 1.4B model is released under the Apache 2.0 license, which allows for commercial use, distribution, and modification. Additionally, there is an instruction-tuned version of the 7B model available in the Hugging Face library.
Implications for the AI Industry
The release of these models highlights the critical role of high-quality data curation in training effective AI systems. The DataComp project demonstrates that with carefully curated datasets, models can achieve superior performance while requiring less computational power. This approach not only makes AI development more efficient but also sets a new standard for data quality in the industry.
The DCLM models are not intended for Apple devices and may exhibit biases or produce harmful responses due to the nature of the training data. However, they represent an early but significant step towards understanding and leveraging data curation for building high-performance AI models.
Apple’s release of the DCLM models marks a notable advancement in the open-source AI community. By outperforming established models from Mistral and Hugging Face, these models underscore the importance of high-quality data curation and efficient training techniques. For data scientists and AI researchers, the DCLM models offer valuable insights and tools for further exploration and development in the field of artificial intelligence.