Revolutionizing AI Reasoning with Smarter Design, Not Bigger Scale
- Progressive Training Pipeline: Starting from the Pixtral-12B base, it employs depth upscaling, staged continual pre-training on text, vision, and synthetic data, and high-quality supervised fine-tuning—achieving gains without reinforcement learning or preference optimization.
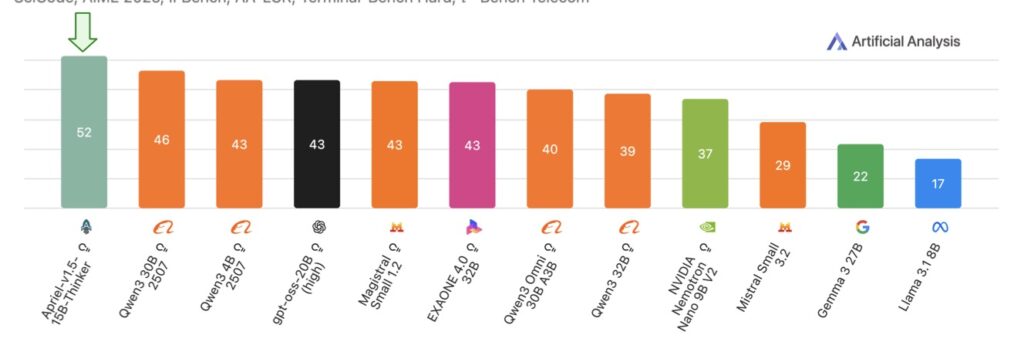
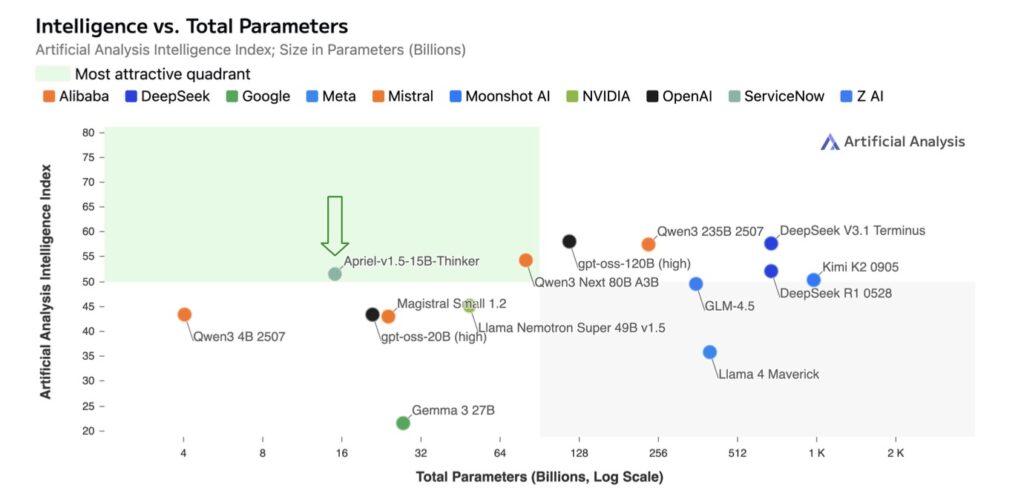
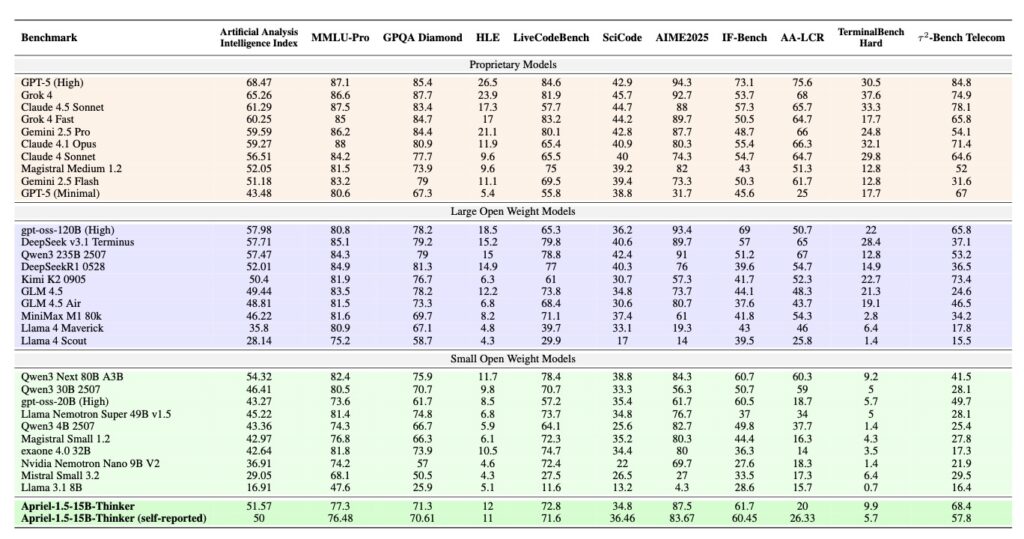
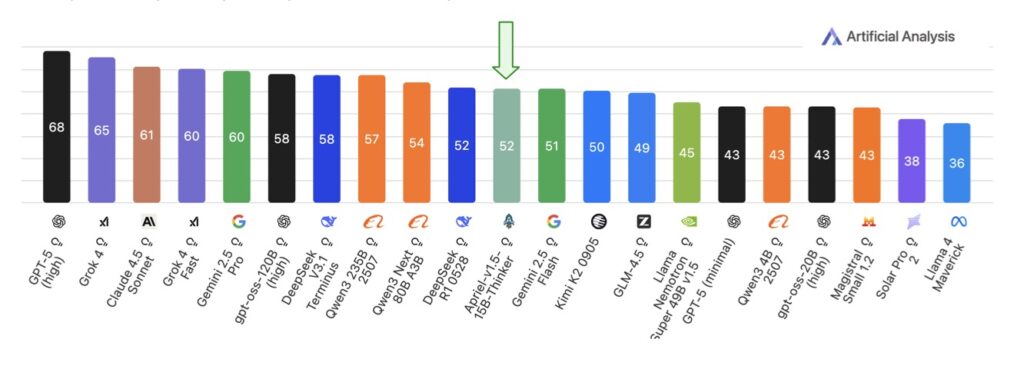
- Benchmark-Beating Efficiency: Scoring 52 on the Artificial Analysis Intelligence Index (matching DeepSeek-R1-0528), it excels in math, coding, science, and tool use, while staying within five points of top models like Gemini-2.5-Flash on image benchmarks—all runnable on a single GPU.
- Open-Source Accessibility: Released under the MIT license with full checkpoints, recipes, and evaluations, it empowers organizations with limited infrastructure to advance multimodal reasoning, paving the way for future enhancements in agentic and interactive AI.
The race for artificial intelligence supremacy has long been defined by scale: bigger models, more parameters, and colossal computational demands. Yet, in a groundbreaking shift, researchers behind Apriel-1.5-15B-Thinker demonstrate that mid-training ingenuity can bridge the gap to frontier-level capabilities without the need for endless expansion. This 15-billion-parameter open-weights multimodal reasoning model, built atop the Pixtral-12B foundation, reimagines AI development by prioritizing data quality, structured pipelines, and efficient scaling. At its core, Apriel-1.5-15B-Thinker isn’t just another model—it’s a testament to how strategic design can democratize advanced AI, allowing even resource-constrained teams to tackle complex reasoning tasks in text, vision, and beyond.
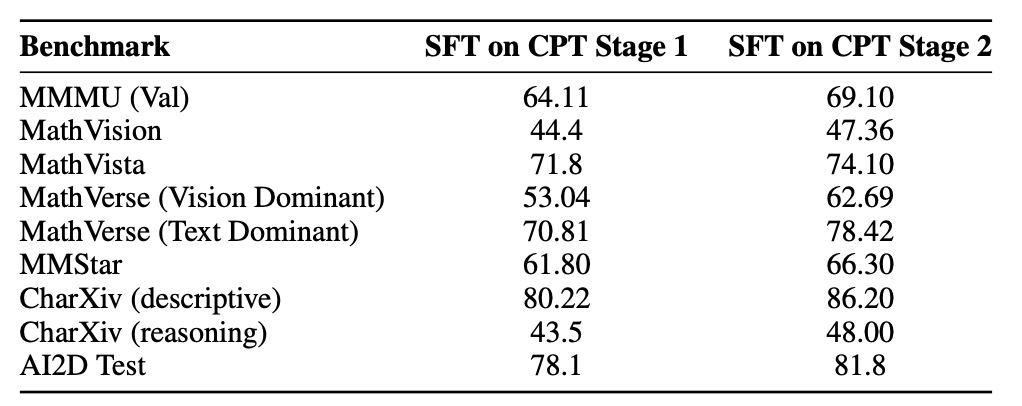
What makes this model truly revolutionary is its progressive three-stage methodology, which avoids the pitfalls of starting from scratch or relying on brute-force pretraining. The journey begins with depth upscaling, a clever technique that expands the model’s reasoning capacity by deepening its architecture without the exorbitant costs of full retraining. This foundational step sets the stage for enhanced comprehension, ensuring the model can handle intricate logical chains from the outset. From there, the team implements staged continual pre-training (CPT), a data-centric approach that builds capabilities layer by layer. Initially, it fosters foundational understanding in text and vision, drawing on diverse datasets to ground the model in real-world patterns. The real innovation shines in the second phase of CPT, where targeted synthetic data generation addresses key multimodal challenges: spatial structure for navigating visual layouts, compositional understanding for piecing together scene elements, and fine-grained perception for discerning subtle details. This isn’t random data dumping—it’s a deliberate curation that yields measurable improvements, such as a +9.65 boost on the MathVerse Vision-Dominant benchmark, highlighting how quality trumps quantity in unlocking visual reasoning prowess.
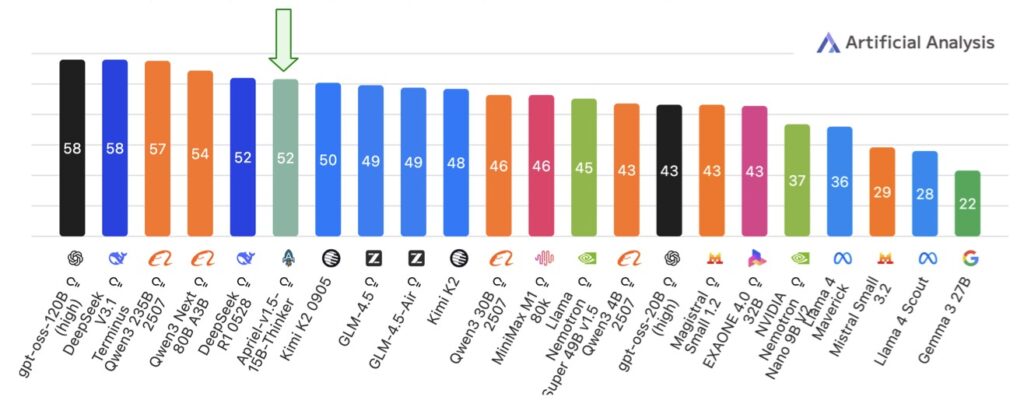
Building on this robust base, the third stage introduces high-quality text-only supervised fine-tuning (SFT) using curated instruction-response pairs enriched with explicit reasoning traces. Spanning domains like mathematics, coding, science, and tool use, these traces guide the model to “think” step-by-step, mimicking human-like deliberation without the complexity of reinforcement learning from human feedback (RLHF) or preference optimization. This isolation of the training recipe’s contributions is a key insight: Apriel-1.5-15B-Thinker achieves competitive results purely through its data-driven pipeline, underscoring the power of high-signal SFT to refine reasoning without additional bells and whistles. The outcome? A model that not only competes but often surpasses expectations in efficiency. On the Artificial Analysis Intelligence Index, it secures a score of 52—on par with the much larger DeepSeek-R1-0528—while demanding far fewer computational resources. In text-based arenas, it shines on rigorous tests like AIME for advanced math and GPQA for graduate-level questions, proving its mettle in pure reasoning.
Multimodal performance further cements Apriel-1.5-15B-Thinker’s edge, particularly impressive given its single-GPU deployment constraints. Across ten diverse image benchmarks, the model averages within five points of elite counterparts like Gemini-2.5-Flash and Claude Sonnet-3.7, handling tasks from object recognition to spatial inference with remarkable accuracy. This isn’t incidental; the targeted synthetic data in CPT directly bolsters visual reasoning, closing gaps that typically require models orders of magnitude larger. For organizations without access to sprawling data centers, this performance-efficiency trade-off is transformative. Imagine deploying frontier-level AI for real-time analysis in education, healthcare, or software development—all from a modest setup. By focusing on thoughtful mid-training design, the creators have made sophisticated multimodal reasoning viable for indie researchers, startups, and non-profits, challenging the narrative that only tech behemoths can innovate at the edge.
At its heart, Apriel-1.5-15B-Thinker’s success reveals a broader truth about AI’s future: scale alone isn’t the answer. This work isolates the impact of a deliberately structured pipeline—CPT for foundational and targeted growth, followed by large-scale SFT—yielding strong results across text and vision without RLHF or alignment tweaks. While the current emphasis leans toward text-based reasoning, the model’s solid multimodal foundation opens doors to expansive applications. Looking ahead, the team plans to deepen these capabilities, extending visual understanding comprehensively and bolstering agentic features for interactive workflows, such as autonomous tool integration or dynamic decision-making. Targeted alignment techniques may enter the mix where needed, but the guiding principles remain unchanged: strategic mid-training, efficient architectural scaling, and an unwavering commitment to high-quality, purpose-built data.
In releasing the full model checkpoint, training recipes, and evaluation protocols under the MIT license, the Apriel team isn’t just sharing code—they’re igniting a movement in open-source AI. This accessibility empowers the global research community to iterate, adapt, and build upon a blueprint that proves mid-training is, indeed, all you need to reach the frontier. As AI evolves, models like Apriel-1.5-15B-Thinker remind us that true progress lies not in size, but in smarter, more inclusive design.