Bridging Biology and Bytes: How a New Model is Redefining Speech Processing with Cochlear Magic
- Mimicking Nature’s Blueprint: AuriStream introduces a two-stage framework inspired by the human auditory system, transforming raw audio into efficient cochlear tokens and using autoregressive modeling to learn versatile speech representations.
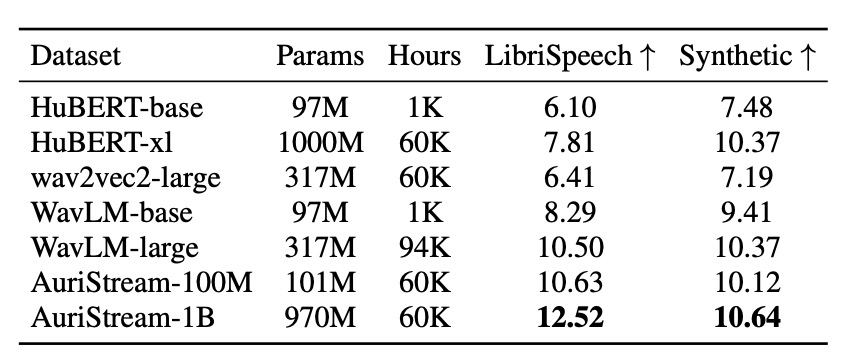
- Powerhouse Performance and Insights: The model excels in phoneme and word decoding, achieves state-of-the-art lexical semantics, and competes on diverse SUPERB speech tasks, while offering unique audio generation and visualization capabilities that peek inside its “mind.”
- Pushing Boundaries with Promise and Pitfalls: By generating fluent speech continuations and contributing to NeuroAI, AuriStream advances human-like AI, though limitations like English-only training highlight paths for future, more naturalistic enhancements.
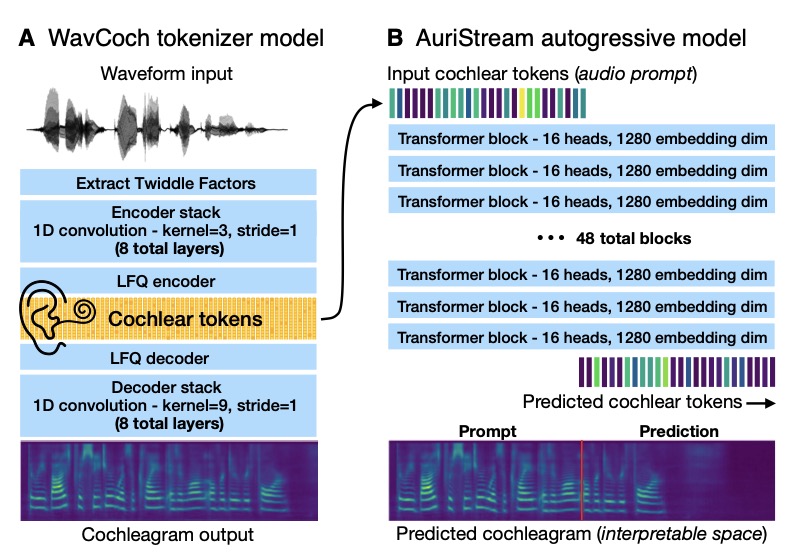
In the ever-evolving world of artificial intelligence, few challenges are as captivating as teaching machines to understand and replicate human speech. Humans effortlessly navigate noisy conversations, discern emotions, and separate voices in a crowd—all thanks to the intricate dance between our ears and brain. Yet, replicating this in AI has long been a puzzle. Enter AuriStream, a groundbreaking, biologically inspired model that’s stepping up to the plate. Drawing from the human auditory processing hierarchy, AuriStream doesn’t just process speech; it learns from it in a way that feels almost organic, promising to bridge the gap between biological prowess and digital innovation.
At its core, AuriStream operates through a clever two-stage framework. The first stage takes raw audio and converts it into a time-frequency representation modeled after the human cochlea—the spiral-shaped wonder in our inner ear that breaks down sounds into frequencies. From this, it extracts discrete “cochlear tokens,” a highly efficient encoding that boils down to about 200 tokens per second of audio. This isn’t just efficient; it’s a game-changer, fitting neatly into the context window of standard Transformer models without overwhelming computational demands. The second stage then applies an autoregressive sequence model over these tokens, predicting what comes next in a sequence much like how we anticipate words in a conversation. This setup allows AuriStream to learn meaningful representations of phonemes (the building blocks of speech sounds) and words, while delivering state-of-the-art results in lexical semantics—the understanding of word meanings and relationships.
What sets AuriStream apart from predecessors like HuBERT or wav2vec2 isn’t just its learning prowess; it’s its ability to generate speech. Trained via a self-supervised autoregressive prediction objective, the model can produce continuations of audio inputs. Imagine feeding it the first three seconds of a spoken sentence from the LibriSpeech dataset—it predicts the next three seconds, which can be visualized in a spectrogram-like cochleagram space and even decoded back into listenable audio using a vocoder. This isn’t mere mimicry; it’s insightful. Researchers can literally “see” the model’s predictions unfolding in time-frequency visuals, peeling back the black box of AI to reveal how it interprets and extends speech. In tests, AuriStream has shown competitive performance across diverse downstream tasks in the SUPERB benchmark, from recognizing words in noise to interpreting emotional tones, proving its versatility as a representational backbone for various audio challenges.
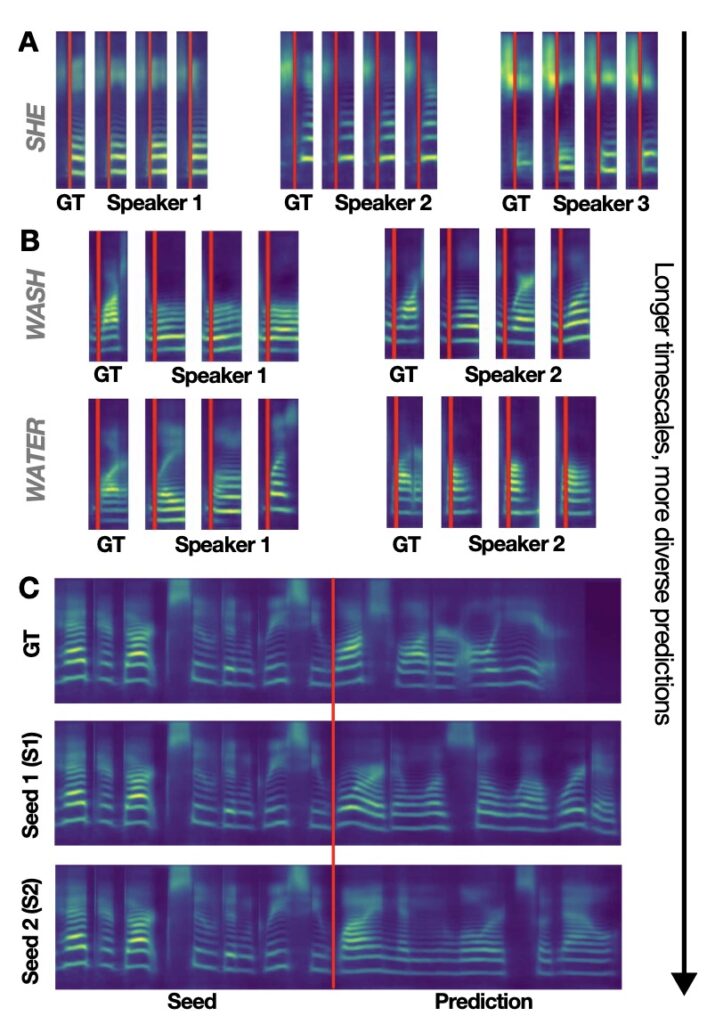
Delving deeper, AuriStream’s innovation shines in its “Transformation Imitation” approach. Unlike neural codec methods that auto-encode audio (reconstructing it from itself), AuriStream learns to transform one representation into another through a discrete quantization bottleneck. This biologically inspired twist makes it scalable and efficient, leveraging the power of autoregressive modeling without the baggage of less efficient token systems. Examples of its generations are telling: Prompted with unseen audio clips, AuriStream crafts fluent sentence continuations across random seeds, often matching ground truth remarkably well. Visualizations of these predictions in cochleagram space highlight the model’s strengths, showing how it captures rhythmic and tonal nuances that make speech feel alive.
Of course, no innovation is without its quirks. AuriStream exhibits fascinating failure modes that offer glimpses into its inner workings. It might insert plausible-sounding nonwords mid-sentence, creating quirky but coherent gibberish, or occasionally produce a slurred, nonsensical sound that derails the entire output. These aren’t just bugs; they’re insights into how the model handles uncertainty, much like a human fumbling words under pressure. Broader limitations temper the excitement: The model was trained solely on English read speech from the LibriLight dataset, which restricts its applicability to non-English languages and reduces its ecological validity—after all, real-world speech is messy, spontaneous, and multilingual. Extending it to more naturalistic, developmentally plausible data, such as conversational recordings or child-directed speech, is a tantalizing future direction that could make it even more human-like.
Looking at the bigger picture, AuriStream isn’t just another speech model; it’s a beacon for the emerging field of NeuroAI. This interdisciplinary arena seeks to link artificial models’ representations and computations to actual brain activity, fostering AI that’s not only smarter but more aligned with biological intelligence. By emulating the cochlea’s efficiency and enabling interpretable generations, AuriStream takes a critical step toward machines that “hear” the world as we do. It’s a reminder that the best tech often borrows from nature, potentially revolutionizing applications from voice assistants to hearing aids. As researchers build on this foundation, addressing its constraints and expanding its scope, AuriStream could pave the way for AI that doesn’t just process speech—it truly understands and creates it, echoing the remarkable abilities we’ve long taken for granted in ourselves.