Introducing a new era of open-source multimodal models featuring native tool use, massive context windows, and real-world agentic capabilities.
- A Dual-Model Release: The GLM-4.6V series launches with two distinct versions: the powerful GLM-4.6V (106B) for high-performance cloud scenarios, and the lightweight GLM-4.6V-Flash (9B) optimized for local deployment and low latency.
- Native Function Calling: Unlike traditional models that rely on text conversion, GLM-4.6V integrates native multimodal tool calling, allowing images and complex documents to be passed directly as parameters and returned as executable results.
- Scale and Precision: With a 128k token context window, the model achieves state-of-the-art (SoTA) performance in visual reasoning, capable of analyzing hours of video or hundreds of document pages in a single pass.
The landscape of Artificial Intelligence is shifting from models that merely “see” to agents that can “act.” Today marks a significant milestone in this evolution with the official open-source release of the GLM-4.6V series. This latest iteration serves as a unified technical foundation for multimodal agents in real-world business scenarios, effectively closing the loop between perception, reasoning, and execution.
The Core Innovation: Native Multimodal Tool Use
For years, “tool use” in Large Language Models (LLMs) suffered from a bottleneck: text. Traditional pipelines required converting images, videos, or complex UI elements into textual descriptions before a model could process them. This intermediate step often resulted in significant information loss and increased system complexity.
GLM-4.6V dismantles this barrier with Native Function Calling. This capability allows the model to treat visual data as a first-class citizen:
- Multimodal Input: Screenshots, document pages, and images are passed directly as tool parameters. This bypasses the need for lossy textual conversion, simplifying the pipeline and preserving fidelity.
- Multimodal Output: The model visually comprehends the results returned by tools—be it rendered web screenshots, statistical charts, or retrieved product images—and seamlessly incorporates them into its reasoning chain.
This “closed loop” architecture empowers the model to handle complex tasks, such as visual web searches and rich-text content creation, with a level of autonomy previously unattainable.

Real-World Capabilities & Scenarios
GLM-4.6V is designed to solve complex, multi-step problems across various domains.
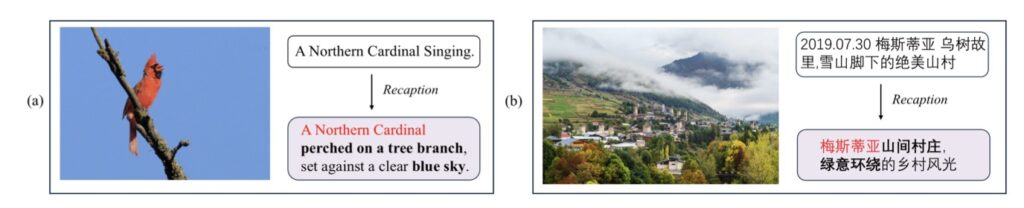
1. Rich-Text Content Understanding and Creation
The model excels at transforming raw inputs into polished, professional outputs. It can ingest papers, reports, or slides and autonomously generate structured, image-text interleaved articles.
- Visual Audit: It acts as an editor, performing “visual audits” on candidate images to filter out noise and assess quality.
- Autonomous Composition: During generation, it calls tools to crop key visuals from the source context, composing relevant text and visuals into articles ready for social media or knowledge bases.

2. Visual Web Search
GLM-4.6V moves beyond simple keyword queries to deliver an end-to-end search-and-analysis workflow.
- Intent & Planning: It identifies user intent and triggers appropriate tools (e.g., text-to-image or image-to-text search).
- Fusion: The model reviews mixed visual and textual search results, identifying the most relevant parts and fusing them to support its reasoning.
- Reporting: The final output is a structured, visually rich report derived from live online retrieval.
3. Frontend Replication & “Design to Code”
Optimized for developers, GLM-4.6V significantly shortens the development cycle.
- Pixel-Level Replication: Developers can upload a design file or screenshot, and the model identifies layouts, components, and color schemes to generate high-fidelity HTML/CSS/JS code.
- Interactive Editing: It supports a “Visual Feedback Loop.” A user can circle an area on a generated page and give natural language instructions like “Move this button left and make it dark blue,” and the model will locate and modify the specific code snippet.
4. Long-Context Understanding
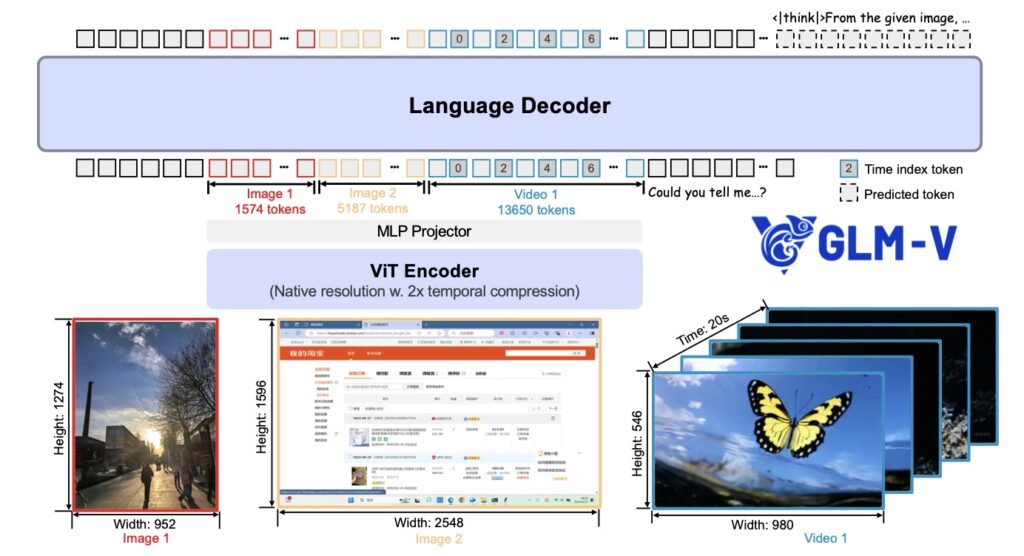
With a visual encoder aligned to a 128K context length, GLM-4.6V possesses a massive memory capacity. In practical terms, this allows for the processing of ~150 pages of complex documents, 200 slide pages, or a one-hour-long video in a single inference pass.
Case Study: Financial Analysis GLM-4.6V successfully processed financial reports from four different public companies simultaneously. It extracted core metrics across documents and synthesized a comparative analysis table without losing key details.
Under the Hood: Technical Architecture
The performance of GLM-4.6V is backed by rigorous architectural innovations and training methodologies.
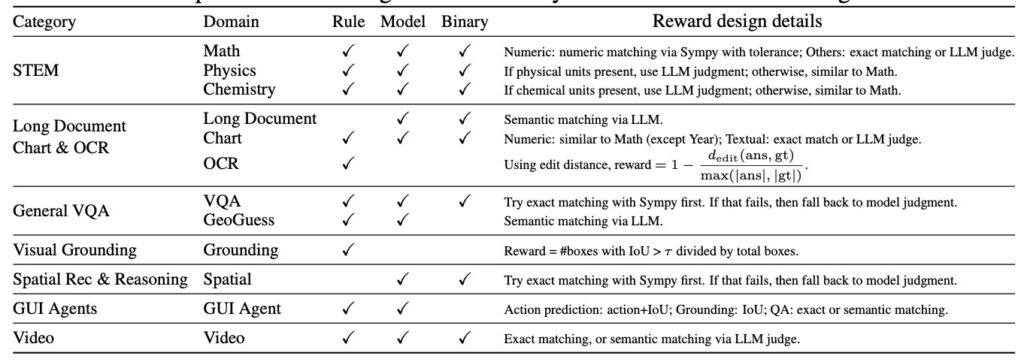
Agentic Data Synthesis & MCP Extension
To support these complex scenarios, the team utilized large-scale synthetic data for agentic training and extended the Model Context Protocol (MCP):
- URL-based Handling: Using URLs to identify multimodal content resolves limitations regarding file size and format.
- Interleaved Output: The model employs a “Draft → Image Selection → Final Polish” framework, ensuring that visuals inserted into text are relevant and readable.
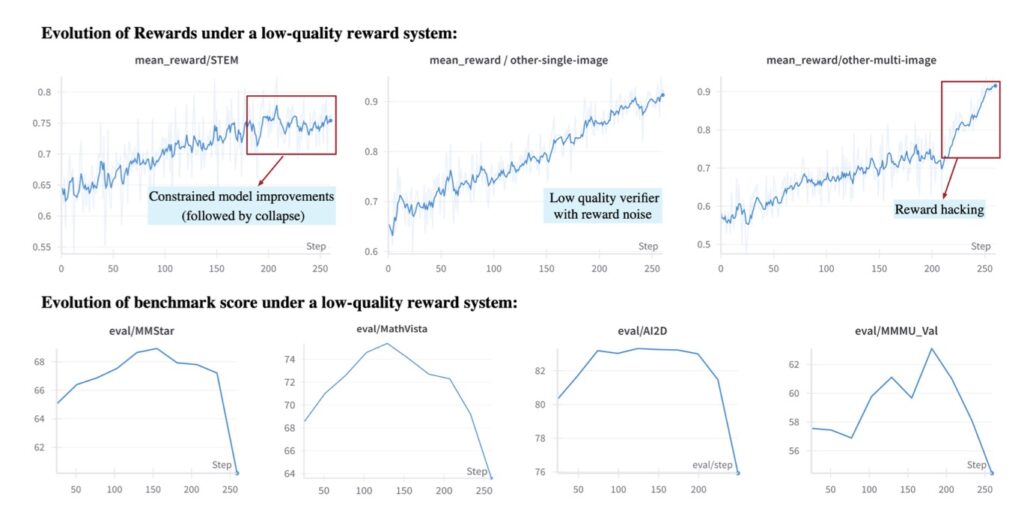
Reinforcement Learning (RL) for Agents
The training process incorporated tool invocation behaviors into the general RL objective. This aligns the model’s ability to plan tasks and adhere to formats within complex tool chains. Inspired by UI2Code^N, the model utilizes a visual feedback loop where it uses visual rendering results to self-correct its code or actions.
World Knowledge Enhancement
A billion-scale multimodal perception and world knowledge dataset was introduced during pre-training. This covers a multi-layered conceptual system, boosting accuracy in cross-modal QA tasks and ensuring the model understands the world as well as it sees it.
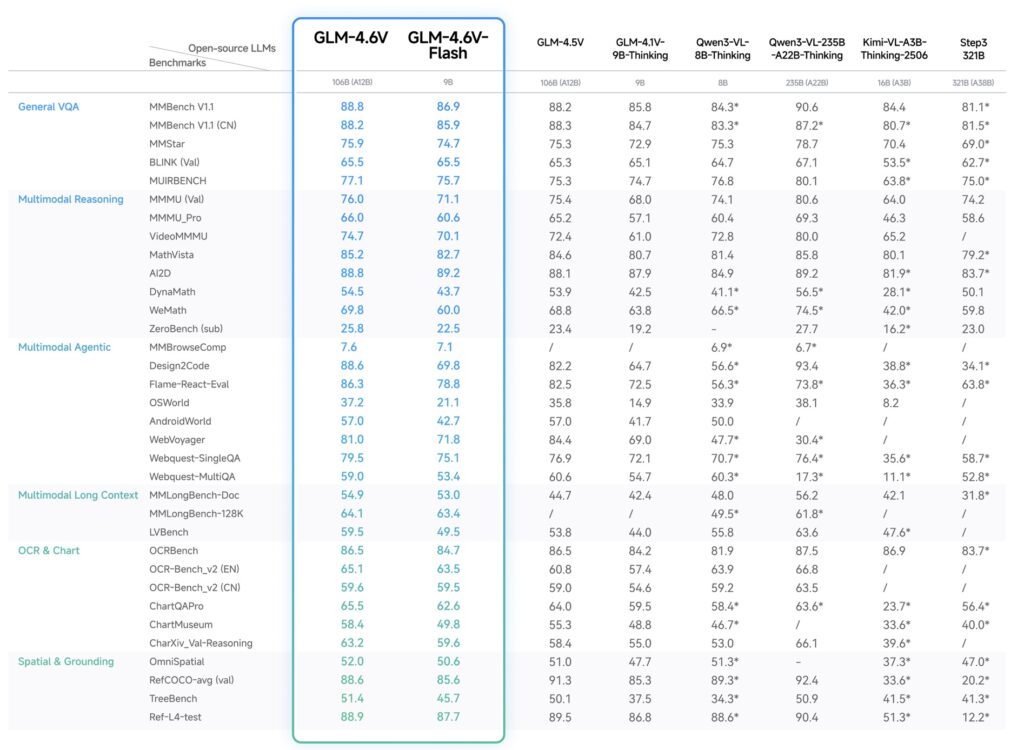
Performance and Availability
Evaluated on over 20 mainstream multimodal benchmarks—including MMBench, MathVista, and OCRBench—GLM-4.6V achieves SoTA performance among open-source models of comparable scale.
Get Started with GLM-4.6V:
- Cloud & App: Experience the model’s capabilities on the Z.ai platform (select GLM-4.6) or via the Zhipu Qingyan App.
- API Integration: Developers can integrate GLM-4.6V into applications using the OpenAI-compatible API.