Unlocking precise control in AI image generation by bridging the gap between freehand sketching and complex multimodal instructions.
- Breaking the Language Barrier: DreamOmni3 moves beyond the limitations of text-only prompts, allowing users to control image editing and generation through intuitive scribbles, color-coded sketches, and doodles.
- The Joint Input Innovation: Unlike traditional models that use restrictive binary masks, this framework employs a “joint input scheme” that processes both the original and scribbled images simultaneously to maintain context and detail.
- Comprehensive Data Pipeline: The model is trained on a newly synthesized dataset derived from DreamOmni2, covering seven distinct tasks ranging from doodle editing to multimodal instruction-based generation.

The recent boom in unified generation and editing models has fundamentally changed digital art. We can now summon complex scenes with a simple sentence. However, anyone who has tried to fine-tune an AI image knows the frustration that follows: language often fails to describe spatial nuances. Text prompts struggle to capture “intended edit locations” or fine-grained visual details. Trying to describe exactly where to place a new object or how to modify a specific curve often results in a game of linguistic trial and error.
To bridge this gap between human intent and machine execution, researchers have introduced DreamOmni3. This new framework proposes a shift toward “scribble-based” editing and generation. By enabling a Graphical User Interface (GUI) where users can combine text, reference images, and freehand sketches, DreamOmni3 offers a level of flexibility that text alone simply cannot provide.
A New Approach: Scribble-Based Flexibility
The core philosophy of DreamOmni3 is that a brush stroke is worth a thousand words. The system is designed to tackle two primary challenges: the scarcity of high-quality training data for sketch-based interactions and the technical limitations of existing model frameworks.
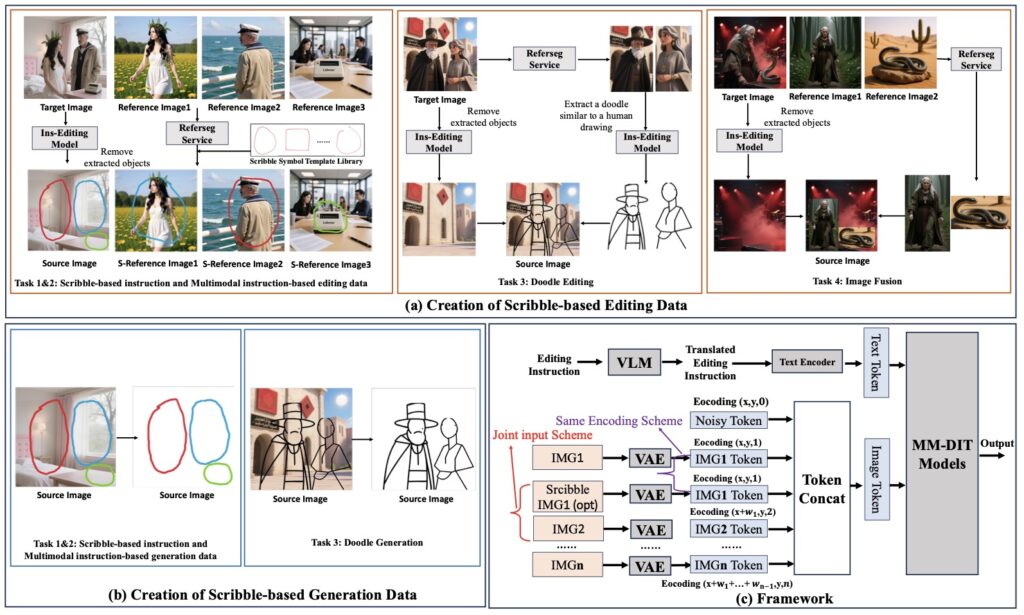
To solve the data problem, the team developed a robust data synthesis pipeline split into two categories: Editing and Generation. Building upon the DreamOmni2 dataset, the system extracts editable regions and overlays hand-drawn elements—such as boxes, circles, doodles, or cropped images—to create a rich training ground.
This pipeline defines specific tasks to ensure the model is versatile:
- Scribble-Based Editing: Includes four distinct sub-tasks: scribble combined with text instructions, scribble with multimodal instructions (text + image), image fusion, and doodle editing.
- Scribble-Based Generation: Focuses on three tasks: generating images from scribbles with text instructions, scribbles with multimodal instructions, and pure doodle generation.
Rethinking the Framework: The Joint Input Scheme
Perhaps the most significant technical leap in DreamOmni3 is how it handles the user’s input. Previous models often relied on “binary masks”—black and white overlays that tell the AI where to look. However, binary masks are insufficient for complex, real-world editing. They struggle when a user wants to perform multiple edits simultaneously or when different regions require different instructions.
DreamOmni3 abandons the binary mask in favor of a Joint Input Scheme.
In this approach, different masks are differentiated by brush color, allowing the system to distinguish between multiple edit zones easily. However, painting over an image can obscure the very details the AI needs to see to perform the edit. To solve this, DreamOmni3 feeds two images into the model simultaneously:
- The original, clean source image.
- The scribbled source image.
By applying the same index and position encodings to both images, the model achieves the best of both worlds. It can precisely localize the scribbled regions (telling it where to edit) while referencing the original image (telling it what was there) to maintain accurate correspondence. This ensures that the structural integrity of the image is preserved even while complex changes are being made.

Benchmarking the Future of Editing
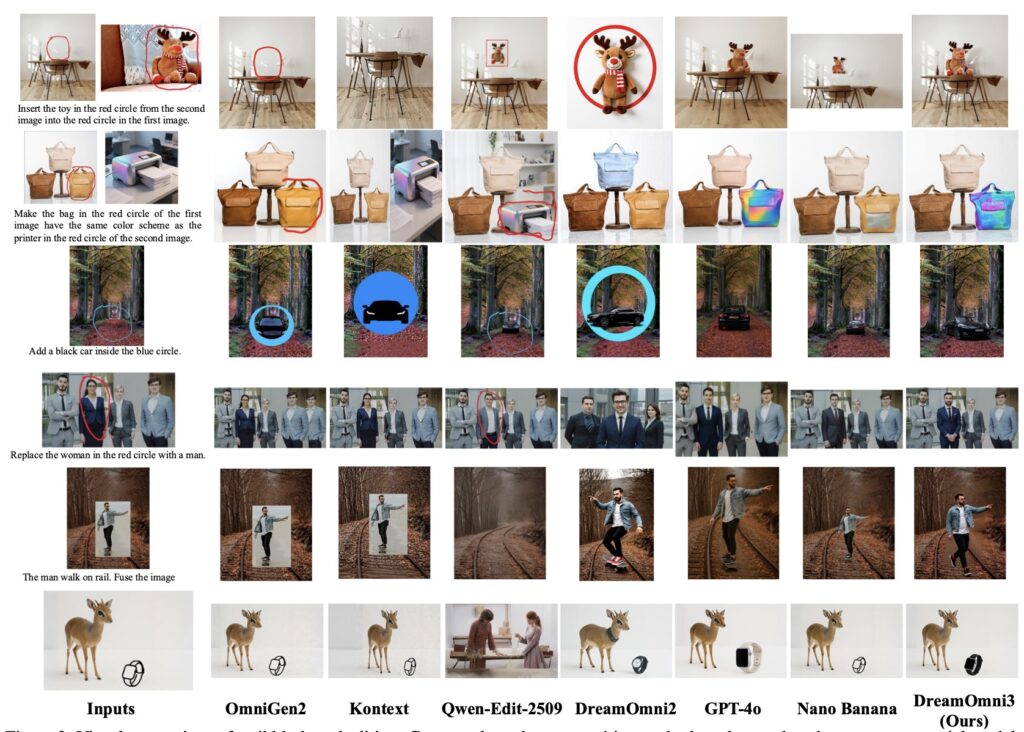
To prove the efficacy of this approach, the creators have established comprehensive benchmarks for all defined tasks, combining scribbles, text, and image instructions to rigorously test the model. Experimental results demonstrate that DreamOmni3 achieves outstanding performance, effectively interpreting the “messy” reality of human scribbles and turning them into polished visual data.
By releasing the models and code to the public, DreamOmni3 is poised to foster significant advancement in the field, moving us closer to a future where AI acts not just as a text-interpreter, but as a true collaborative design partner.