How the new “Speciale” variant surpasses GPT-5 and rivals Gemini-3.0-Pro by scaling reinforcement learning and mastering agentic tasks.
- Dual Launch: DeepSeek has officially released V3.2 (the successor to V3.2-Exp) for general use, alongside the API-exclusive “Speciale” variant designed to push the absolute boundaries of reasoning.
- Technical Triumphs: Through DeepSeek Sparse Attention (DSA) and a novel agentic task synthesis pipeline, the models achieve gold-medal status in the 2025 IMO and IOI competitions, with the Speciale variant outperforming GPT-5.
- A New Scaling Law: While competitors focus on pretraining scaling, DeepSeek-V3.2 proves that scaling Reinforcement Learning (RL) with large context is the key to solving post-training bottlenecks.
The landscape of artificial intelligence has shifted once again with the official launch of DeepSeek-V3.2 and its high-compute sibling, DeepSeek-V3.2-Speciale. Representing a year of rigorous optimization and “pushing limits,” these reasoning-first models are built specifically for agents, marking a departure from standard language modeling toward complex problem-solving. While DeepSeek-V3.2 is now live across App, Web, and API platforms as the official successor to V3.2-Exp, the spotlight is firmly on the API-only Speciale variant, which is rewriting the benchmarks for what open large language models (LLMs) can achieve.
The Trinity of Technical Breakthroughs
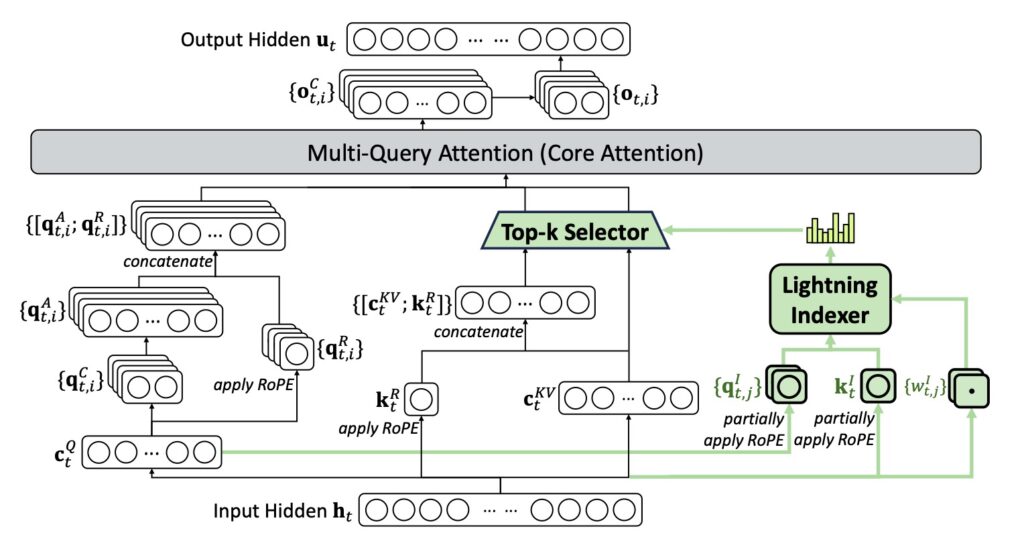
DeepSeek-V3.2 is not merely an iterative update; it is a model designed to harmonize high computational efficiency with superior agent performance. The architecture relies on three specific technical breakthroughs that allow it to punch significantly above its weight class.
First is the introduction of DeepSeek Sparse Attention (DSA). This efficient attention mechanism substantially reduces computational complexity, a critical factor when dealing with massive datasets. Crucially, DSA preserves model performance even in long-context scenarios, ensuring that efficiency does not come at the cost of accuracy.
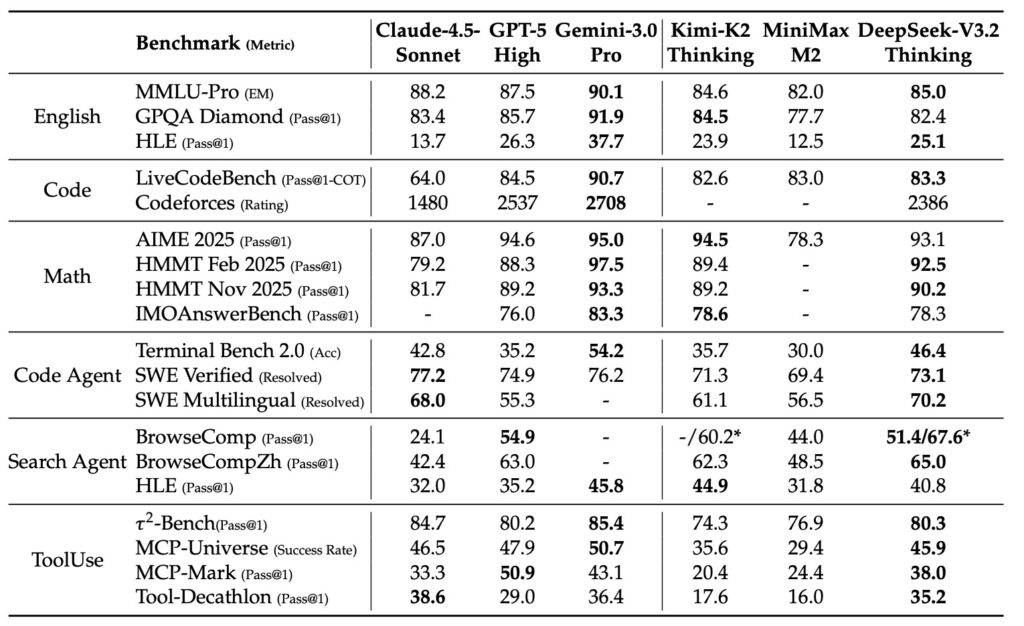
Second is a Scalable Reinforcement Learning Framework. By implementing a robust RL protocol and scaling post-training compute, the standard DeepSeek-V3.2 performs comparably to GPT-5. However, the high-compute variant, DeepSeek-V3.2-Speciale, goes further. It surpasses GPT-5 and exhibits reasoning proficiency on par with Gemini-3.0-Pro.
Finally, the team developed a Large-Scale Agentic Task Synthesis Pipeline. To integrate reasoning into tool-use scenarios, this pipeline systematically generates training data at scale. This methodology facilitates scalable agentic post-training, yielding substantial improvements in generalization and instruction-following robustness within complex, interactive environments.
Gold-Medal Performance: Cracking the Code
The proof of these innovations lies in the testing. DeepSeek-V3.2-Speciale has achieved gold-medal performance in both the 2025 International Mathematical Olympiad (IMO) and the International Olympiad in Informatics (IOI). These feats were accomplished under strict constraints: a maximum generation length of 128k, no internet access, and no external tools.
For the IOI evaluation, DeepSeek employed a sophisticated submission strategy aligned with official competition rules. The model generated 500 candidate solutions per problem. These underwent a multi-stage filtering pipeline where invalid submissions and refusals (identified by the V3.2-Exp model) were culled. From the remaining valid candidates, the system selected the 50 samples with the “longest thinking traces”—a metric used to identify the most thorough reasoning paths—for final submission. A similar, scaled-down methodology was applied to ICPC evaluations, generating 32 candidates per problem.
Proving a New Path Forward
Perhaps the most significant contribution of DeepSeek-V3.2 is philosophical rather than just technical. As the team notes, if Gemini-3 proved the value of continual scaling in pretraining, DeepSeek-V3.2-Speciale proves the value of scaling Reinforcement Learning with large context.
The development process has demonstrated that post-training bottlenecks are not solved simply by waiting for a better base model. Instead, they are overcome by refining methods and data. By spending a year pushing the V3 architecture to its absolute limits, DeepSeek has shown that a combination of sparse attention, aggressive RL scaling, and synthetic data pipelines can produce an agent capable of reasoning at the highest levels of human competition.