NOLIMA Exposes Critical Flaws in LLMs’ Ability to Infer and Link Information in Extended Texts
- Literal Matches ≠ Real Intelligence: While LLMs ace “needle-in-a-haystack” tests by spotting keywords, their performance plummets when asked to reason through latent connections in long contexts.
- The Long-Context Illusion: Models like GPT-4o drop from 99.3% accuracy in short texts to under 70% in 32K-token contexts when lexical overlaps vanish, exposing attention mechanism limitations.
- NOLIMA’s Wake-Up Call: A new benchmark reveals that without surface-level clues, even state-of-the-art LLMs falter—raising red flags for real-world applications like search engines and RAG systems.
Large language models (LLMs) have dazzled the world with their ability to process ever-lengthening texts—up to 1 million tokens in some cases. But a groundbreaking study reveals a sobering truth: these models excel at findinginformation but stumble catastrophically when asked to connect the dots. The culprit? A reliance on superficial lexical matches rather than genuine reasoning.
The Needle-in-a-Haystack Mirage
The popular “needle-in-a-haystack” (NIAH) test, where models retrieve specific facts from lengthy documents, has become a go-to benchmark for long-context prowess. On the surface, results seem impressive: models like GPT-4 and Claude 3 consistently locate needles with near-perfect accuracy. But researchers now argue this is a flawed metric. “It’s like praising a child for finding a red apple in a fruit basket,” explains one AI ethicist. “Real intelligence isn’t just matching words—it’s understanding context.”
Extensions of NIAH—like adding distractor sentences or chaining facts—initially appeared more rigorous. Yet models still exploited shortcuts: if a question contained the phrase “quantum entanglement,” they’d scan for those exact words rather than grasp underlying concepts.
Enter NOLIMA: A Benchmark That Demands Real Thinking
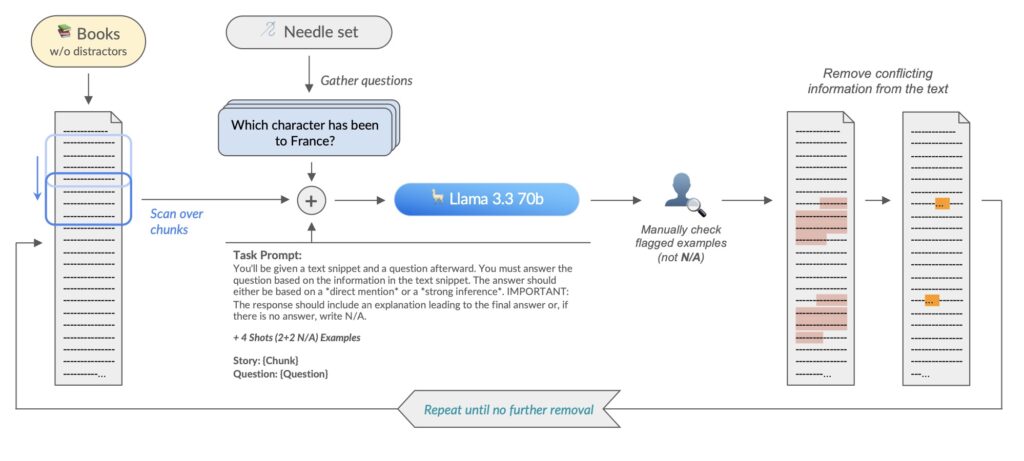
To close this loophole, researchers developed NOLIMA (Non-Literal Matching Assessment), a benchmark that eliminates lexical overlaps between questions and answers. For example, instead of asking directly about “photosynthesis,” NOLIMA might pose: “Identify the process by which plants convert light energy—discovered by a scientist who studied pea plants—into chemical storage.“ Here, “photosynthesis” is never mentioned, forcing models to infer links between Mendel’s genetics work (a distractor) and energy conversion.
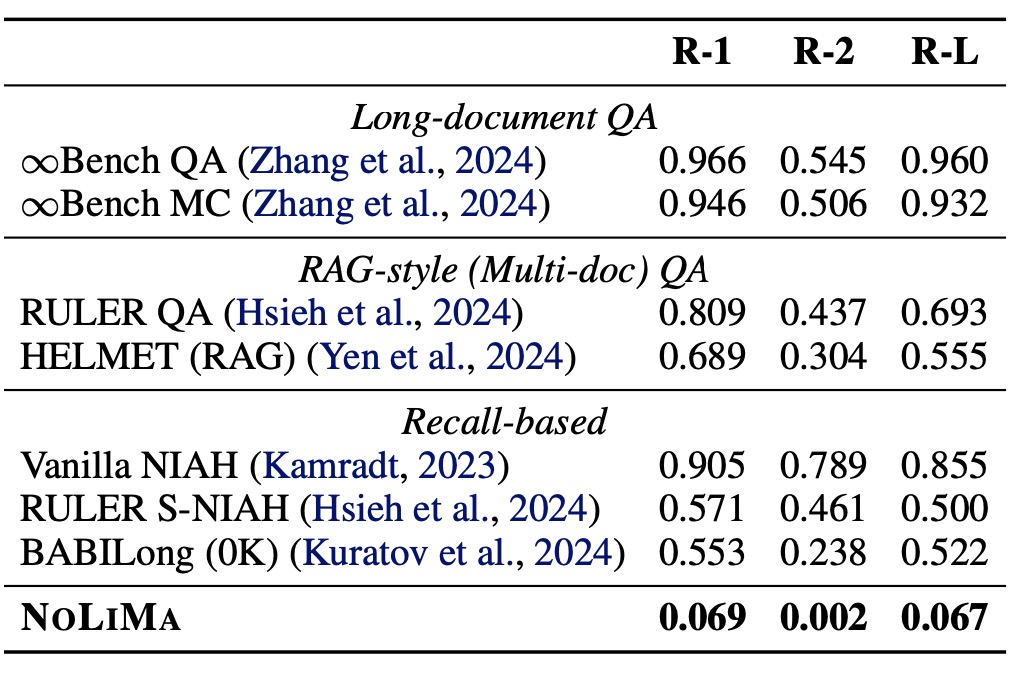
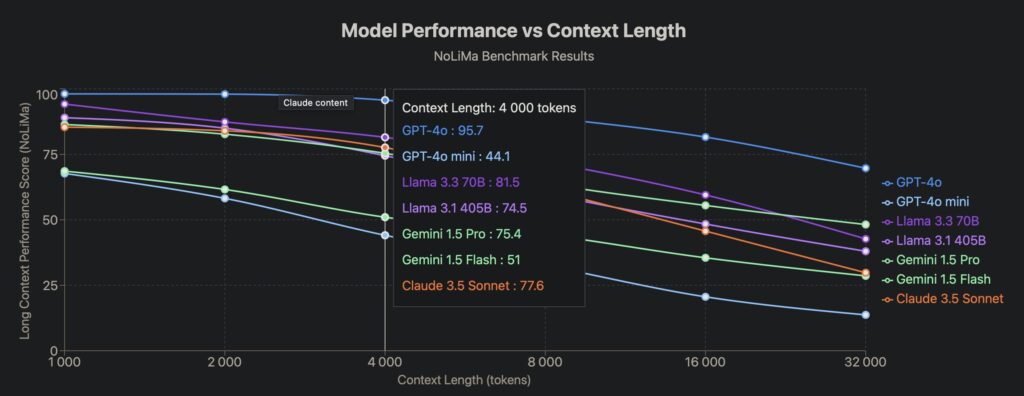
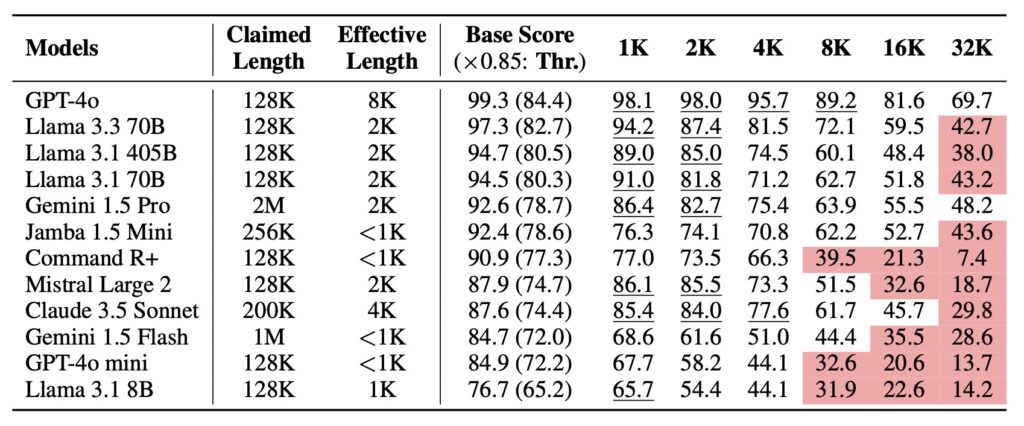
When tested on 12 leading LLMs supporting 128K+ token contexts, the results were stark:
- At 1K tokens, most models scored 85–95%.
- At 32K tokens, 10 models plunged below 50% of their baseline performance.
- Even GPT-4o nosedived from 99.3% (short context) to 69.7% (32K tokens).
“It’s not a memory problem—it’s a reasoning problem,” notes the study. “These models have perfect recall but lack the cognitive architecture to synthesize information.”
Why Attention Mechanisms Fail in the Long Game
The collapse stems from how LLMs process context. While transformers theoretically access all prior tokens via attention mechanisms, in practice, they prioritize recent or lexically salient content. As context grows, the signal-to-noise ratio worsens, and models default to pattern-matching rather than deep analysis.
This has dire implications for real-world tools:
- Search Engines: A document with the correct answer might use different terminology than the query, causing LLMs to favor lexically similar but irrelevant results.
- RAG Systems: Retrieval-augmented generation pipelines could retrieve marginally related documents simply because they share keywords, bypassing truly relevant but linguistically distinct sources.
- Legal/Medical Analysis: Lengthy contracts or research papers might contain critical information phrased unexpectedly, leading to dangerous oversights.
The Path Forward: From Pattern Matching to True Comprehension
NOLIMA isn’t just a critique—it’s a roadmap. By prioritizing inference over memorization, it challenges developers to reimagine how LLMs handle long contexts. Hybrid architectures combining retrieval systems with better reasoning modules, or novel attention mechanisms that weight semantic relevance over lexical proximity, could bridge this gap.
As one researcher puts it: “We’ve taught models to read encyclopedias—now we need to teach them to think like librarians.” Until then, the dream of LLMs mastering long-form reasoning remains just that—a dream.