Why treating every word equally is holding AI back, and how “thinking in concepts” unlocks new reasoning power.
- The Efficiency Gap: Standard Large Language Models (LLMs) treat every word with equal importance, wasting massive computational resources on predictable filler text while under-investing in complex reasoning.
- The Concept Shift: The proposed Dynamic Large Concept Models (DLCM) framework shifts processing from individual tokens to “concepts”—variable-length semantic units—allowing the model to reason in a compressed, higher-level space.
- Smarter Scaling: By utilizing novel compression-aware scaling laws and a decoupled μP parametrization, DLCMs achieve a +2.69% improvement on reasoning benchmarks by reallocating compute where it matters most, without increasing the total computational budget.

In the current landscape of Artificial Intelligence, Large Language Models (LLMs) have become the gold standard for natural language understanding and generation. From GPT-4 to open-source variations, nearly all state-of-the-art models share a fundamental architectural dogma: uniformity.
Regardless of the content, standard LLMs apply identical depth and computation to every single token in a sequence. Whether the model is processing a simple article like “the cat sat on the mat” or a complex derivation in quantum mechanics, it expends the same amount of “brain power” on every sub-word unit.
This approach ignores a basic reality of natural language: information density is highly non-uniform. Language consists of long spans of predictable, low-entropy text interspersed with sparse, critical transitions where new ideas are introduced. By adhering to a token-uniform regime, modern models suffer from a systematic misallocation of capacity. They waste resources on the easy parts and under-allocate computation to the semantically critical moments where reasoning actually happens.

Enter the Dynamic Large Concept Model (DLCM)
To address this inefficiency, researchers have introduced Dynamic Large Concept Models (DLCM). This hierarchical framework challenges the status quo by shifting the focus from rigid tokens to adaptive “concepts.”
Instead of forcing reasoning to happen at the token level, DLCM learns semantic boundaries directly from latent representations. It groups tokens into variable-length concepts, effectively compressing the input into a “concept space.” This allows the model to perform reasoning on these higher-level abstractions rather than getting bogged down in the syntax of every individual word.
Crucially, DLCM discovers these concepts end-to-end. It does not rely on predefined linguistic rules (like “nouns” or “phrases”); instead, it dynamically determines the most efficient way to group information based on the context.
The Physics of Compressed Reasoning
Shifting to a hierarchical architecture fundamentally changes how models scale. To navigate this new terrain, the development of DLCM required the creation of the first compression-aware scaling law.
In traditional models, scaling is usually a matter of adding parameters or data. However, DLCM requires disentangling three distinct factors:
- Token-level capacity: The ability to process raw text.
- Concept-level reasoning capacity: The ability to manipulate abstract ideas.
- Compression ratio: How densely information is packed.

This new scaling law enables a principled allocation of compute under fixed FLOPs (floating-point operations per second). It ensures that the model isn’t just “larger,” but that it is spending its energy efficiently between reading text and thinking about it.
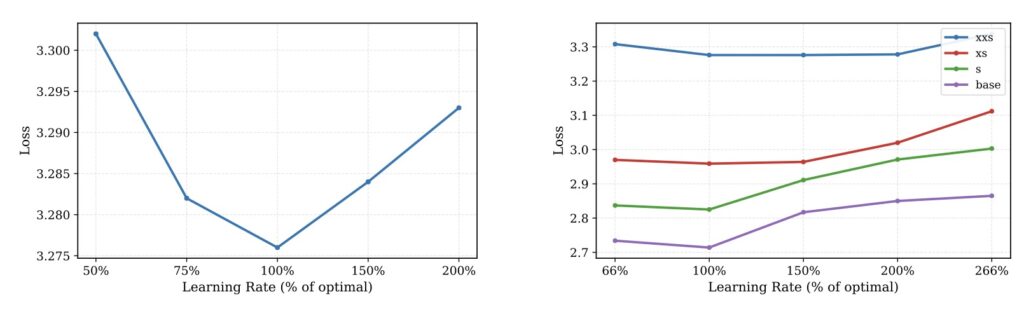
To ensure this heterogeneous architecture could be trained stably, the framework utilizes a decoupled μP parametrization. This technique allows for zero-shot hyperparameter transfer across different model widths and compression regimes, solving the stability issues that often plague complex, multi-level neural networks.
Doing More with the Same
The theoretical innovations of DLCM translate into concrete performance gains. In practical settings, specifically with a compression ratio of R=4 (meaning the model groups an average of four tokens into a single concept), the results are compelling.
By compressing the input, DLCM is able to reallocate roughly one-third of its inference compute into a higher-capacity reasoning backbone. The model isn’t working harder; it is working smarter.
When tested against 12 zero-shot benchmarks under matched inference FLOPs, DLCM achieved a +2.69% average improvement. This demonstrates a favorable accuracy–efficiency trade-off, proving that the model is effectively utilizing the “saved” compute from predictable tokens to perform deeper reasoning on complex concepts.
The Future of Adaptive AI
The success of Dynamic Large Concept Models suggests a pivotal shift in the trajectory of AI development. It indicates that scaling is not merely about making models bigger; it is about reconsidering where computation is performed.
By moving from token-level processing to concept-level latent reasoning, we open the door to systems that mimic human thought processes more closely—skimming the mundane to focus deeply on the profound. DLCMs offer a promising path toward future work on adaptive abstraction, planning, and multi-level reasoning, moving us closer to truly efficient and intelligent large-scale neural systems.