A new open-source foundation model bridges the gap between sight and sound, delivering state-of-the-art audiovisual generation with unprecedented efficiency.
- Unified Audiovisual Synthesis: LTX-2 moves beyond silent video generation by introducing an asymmetric dual-stream transformer that creates high-quality video and synchronized audio simultaneously.
- State-of-the-Art Efficiency: By utilizing a 14B-parameter video stream coupled with a 5B-parameter audio stream, the model delivers results comparable to proprietary systems at a fraction of the computational cost.
- Ethical & Creative Impact: While the model democratizes content creation and accessibility—particularly for low-resource languages—it emphasizes the necessity of responsible use to mitigate risks associated with deepfakes and bias.
For years, the field of generative AI has been trapped in a modern “silent film” era. While recent text-to-video diffusion models have learned to conjure compelling, photorealistic sequences from simple text prompts, they have largely remained mute. These models miss the crunch of footsteps, the rustle of wind, and the emotional inflection of a human voice—cues that are essential for true immersion.
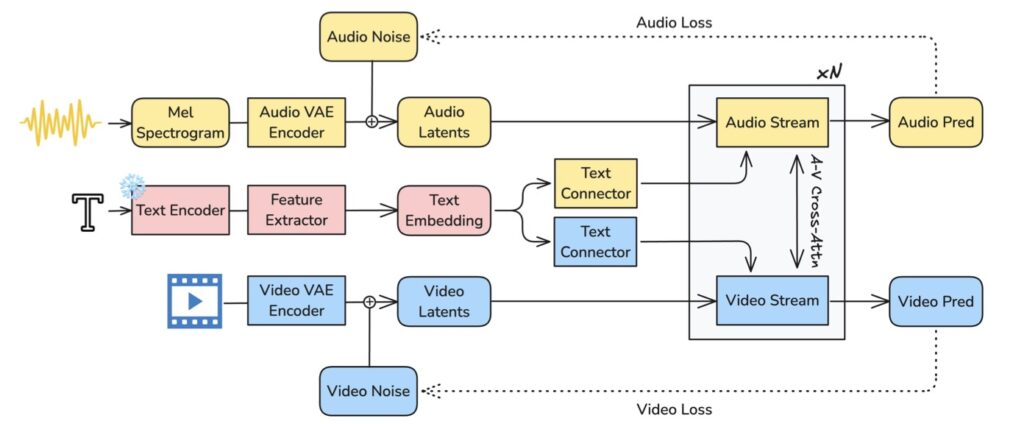
Enter LTX-2, a groundbreaking open-source foundational model designed to shatter this silence. Unlike previous attempts that treat audio as an afterthought, LTX-2 generates high-quality, temporally synchronized audiovisual content in a single, unified process. By weaving together sight and sound, LTX-2 captures the semantic, emotional, and atmospheric elements that turn a moving image into a story.
Under the Hood: An Asymmetric Dual-Stream Architecture
The brilliance of LTX-2 lies in its architectural efficiency. The model employs an asymmetric dual-stream transformer, recognizing that generating video requires more computational “muscle” than generating audio. The system features:
- A 14B-parameter video stream for complex visual rendering.
- A 5B-parameter audio stream for high-fidelity sound generation.
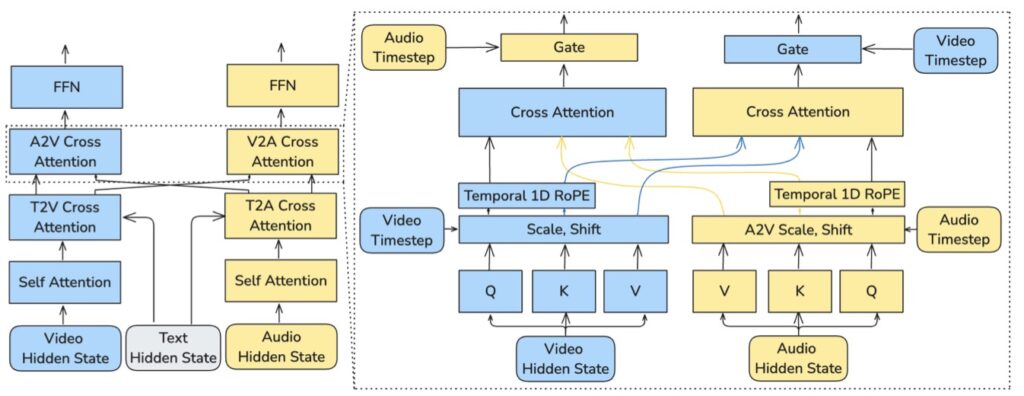
These two streams are not isolated; they are tightly coupled through bidirectional audio-video cross-attention layers. This allows the audio to “watch” the video and vice versa, ensuring perfect sync. To manage the flow of time, the model utilizes temporal positional embeddings and a cross-modality AdaLN (Adaptive Layer Normalization) mechanism, which enables shared timestep conditioning.
This design allows LTX-2 to allocate capacity where it is needed most. By avoiding the duplication of visual backbones and using a modality-aware classifier-free guidance (modality-CFG) mechanism, the model achieves improved alignment and controllability. The result is a system that is not only smart but incredibly fast—setting a new benchmark for speed among open-source models.
Beyond Speech: A Symphony of Foley and Atmosphere
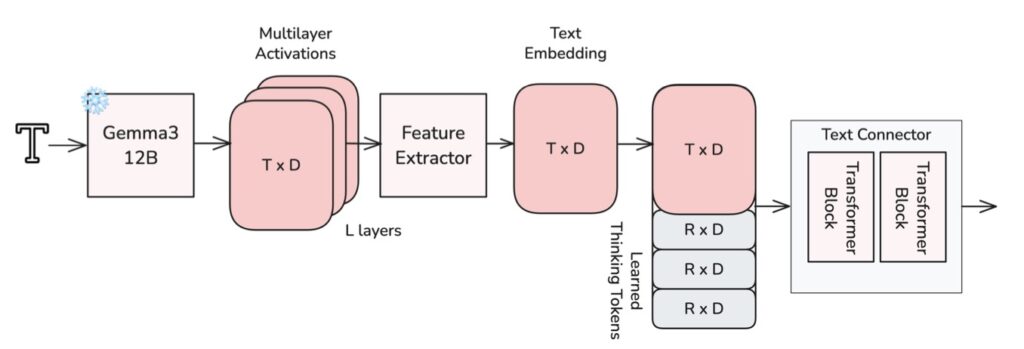
While many models focus strictly on talking heads, LTX-2 takes a broader approach to soundscapes. It utilizes a multilingual text encoder to understand complex prompts, enabling it to generate rich, coherent audio tracks that strictly adhere to the style and environment of the scene.
The model is capable of generating natural background elements and “foley” sounds—the everyday sound effects that ground a scene in reality. Whether it is the ambient noise of a busy street or the specific emotional tone of a character’s voice, LTX-2 ensures the audio follows the narrative flow. In evaluations, LTX-2 achieved state-of-the-art audiovisual quality and prompt adherence, proving that open-source systems can rival expensive proprietary models.

Democratizing Creativity and Accessibility
The implications of LTX-2 extend far beyond technical benchmarks. Text-to-audio+video (T2AV) generation opens new avenues for communication, creativity, and education.
- For Creators: Storytellers and educators can now produce expressive audiovisual material without the need for specialized recording equipment or large production teams.
- For Accessibility: The ability to generate synchronized visuals and audio is a game-changer for accessibility. This includes creating inclusive media for visually impaired audiences or producing content for low-resource languages that are often ignored by major media studios.
- Global Reach: The technology holds particular promise for dubbing and localizing educational content, breaking down linguistic and cultural boundaries to make knowledge more universally available.
Navigating the Ethical Landscape
With great generative power comes significant responsibility. The creators of LTX-2 are transparent about the societal challenges introduced by realistic synthetic media. The potential for misuse—specifically the creation of deceptive “deepfakes” or manipulative content—is a serious concern.
Furthermore, AI models are mirrors of the data they consume. LTX-2 may reflect biases present in its training set, which can manifest in both visual representation and auditory stereotypes. The release of LTX-2 emphasizes that while the model is designed for research and creative expression, responsible use is paramount. This includes clear disclosure of synthetic origins and strict adherence to safety guidelines. Future development must prioritize bias mitigation, authenticity verification, and traceability to ensure these tools remain a force for positive societal impact.
LTX-2 represents a pivotal moment in generative AI. By publicly releasing the model weights and code, the team behind LTX-2 has provided a practical foundation for scalable, accessible audiovisual synthesis. It stands as the fastest model of its kind, offering state-of-the-art quality while fostering further research into cross-modal alignment. As developers and artists begin to explore the capabilities of LTX-2, we move one step closer to a digital world where AI creates not just with eyes, but with ears as well.