A new 3B parameter model uses a novel “analyze-then-parse” approach to master complex layouts with pixel-level precision.
- Universal Understanding: Dolphin-v2 is a lightweight (3B parameter) model released under the MIT license that parses PDFs, scans, and photos with pixel-level precision, recognizing 21 distinct content types including text, code, tables, and formulas.
- Novel Architecture: Utilizing a unique “analyze-then-parse” paradigm, the model first identifies layout elements and then uses heterogeneous anchor prompting to parse content in parallel, solving efficiency bottlenecks found in traditional models.
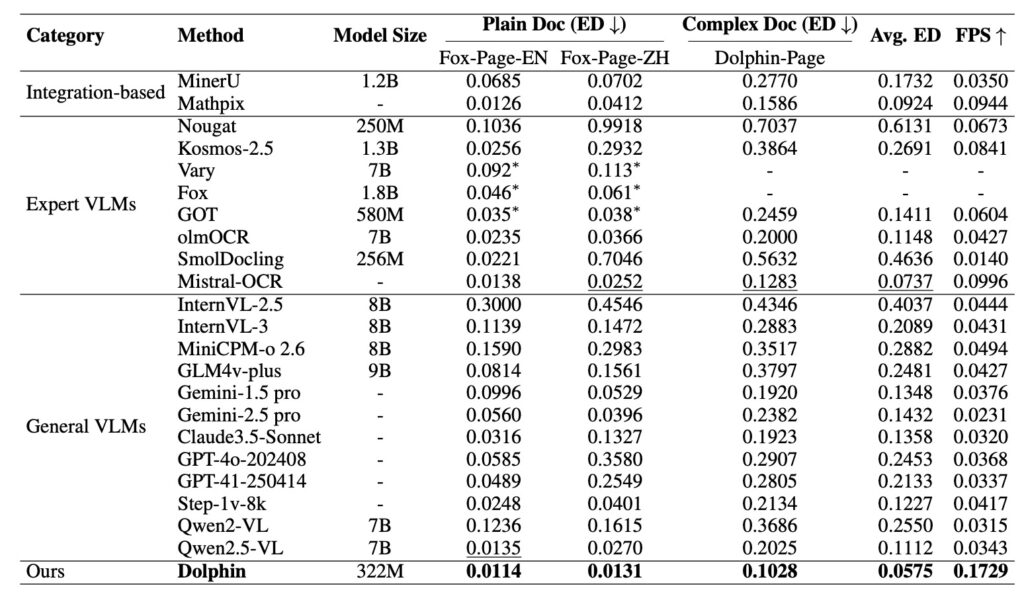
- Proven Performance: Trained on a massive dataset of 30 million samples, Dolphin achieves state-of-the-art results on complex English and Chinese documents, though it currently faces limitations with vertical text and handwriting.
For years, the digitization of documents has faced a stubborn bottleneck: the complexity of layout. While reading a text file is simple for AI, parsing a PDF, a scanned invoice, or a photo of a textbook page is notoriously difficult. These documents are not just strings of words; they are complexly intertwined elements where paragraphs flow around images, mathematical formulas sit inside text blocks, and tables disrupt the reading flow. Current approaches have struggled here, often relying on a messy assembly of specialized “expert” models or slow autoregressive generators that lose track of the page structure. To solve this, ByteDanceOSS has released Dolphin-v2, a groundbreaking model that reimagines how machines see and understand documents.

The “Analyze-then-Parse” Paradigm
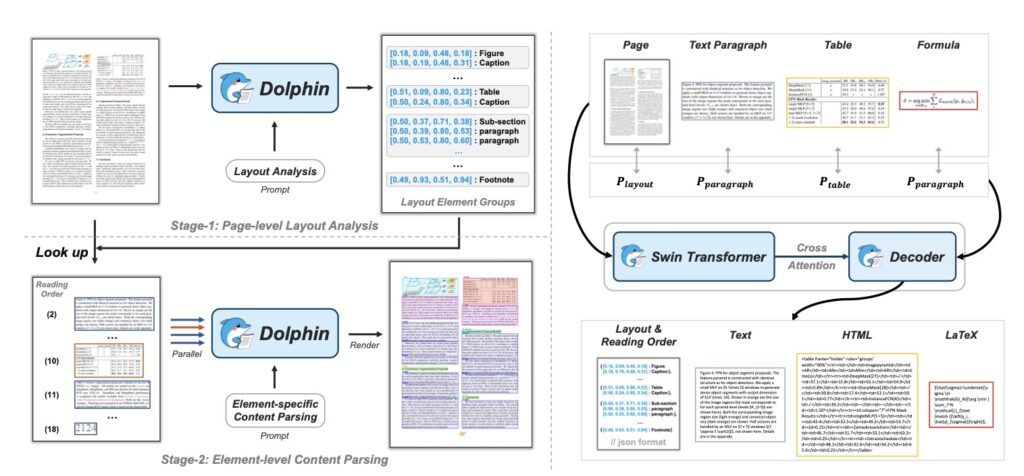
The core innovation behind Dolphin is its move away from trying to read everything linearly from start to finish. Instead, it employs a novel “analyze-then-parse” paradigm. This two-stage design is what allows Dolphin to balance high efficiency with high accuracy.
In the first stage, Dolphin acts as a layout analyst. It scans the document to generate a sequence of layout elements arranged in a logical reading order. Once the model understands where everything is, it moves to the second stage. Here, it utilizes heterogeneous anchor prompting. The layout elements identified in stage one serve as “anchors.” These anchors are coupled with task-specific prompts and fed back into the system, allowing Dolphin to parse the actual content—the text, numbers, and code—in parallel. By decoupling the layout analysis from the content generation, Dolphin avoids the integration overhead and structural degradation that plague other models.
Capabilities and Precision
The technical specifications of Dolphin-v2 are designed for broad accessibility and high performance. It is a 3B parameter model, making it surprisingly lightweight and efficient compared to massive large language models (LLMs). Despite its smaller size, it boasts pixel-level precision via absolute coordinate prediction. This means it doesn’t just read the text; it knows exactly where that text sits on the massive canvas of a page.
This precision allows Dolphin to distinguish between 21 different types of content, ranging from standard text paragraphs to complex tables, software code, mathematical formulas, and figures. Whether the input is a pristine digital PDF or a noisy photograph of a document, Dolphin is engineered to parse it. This versatility is powered by a massive training effort; the team constructed a large-scale dataset comprising over 30 million samples, covering multi-granularity parsing tasks to ensure the model is robust across different domains.

Performance and Limitations
Through comprehensive evaluations on both prevalent benchmarks and self-constructed tests, Dolphin has demonstrated state-of-the-art performance. It particularly excels in handling complex documents rich in formatting, such as research papers or financial reports containing interleaved tables and formulas. The model handles both English and Chinese documents with high proficiency, making it a powerful tool for global applications. Furthermore, its MIT license ensures that developers and researchers can freely integrate this technology into their own workflows, democratizing access to high-end document parsing.

However, even with its advanced architecture, Dolphin has room for growth. The authors note that the model currently struggles with non-standard layouts, specifically vertical text often found in ancient manuscripts. While it is strong in English and Chinese, its broader multilingual capacity needs expansion, though it has shown signs of emergent capabilities in other languages. Additionally, while the parallel parsing of elements is efficient, the team sees potential for further optimization by parallelizing the processing of individual text lines and table cells. Finally, handwriting recognition remains an area requiring further enhancement.
Despite these limitations, Dolphin represents a significant leap forward. By treating document parsing as a structured, two-step logic problem rather than a simple reading task, ByteDance has created a tool that finally helps computers understand documents as well as humans do.
