Introducing ABC-Bench: A rigorous new framework revealing why environment configuration and deployment remain the Achilles’ heel of modern AI.
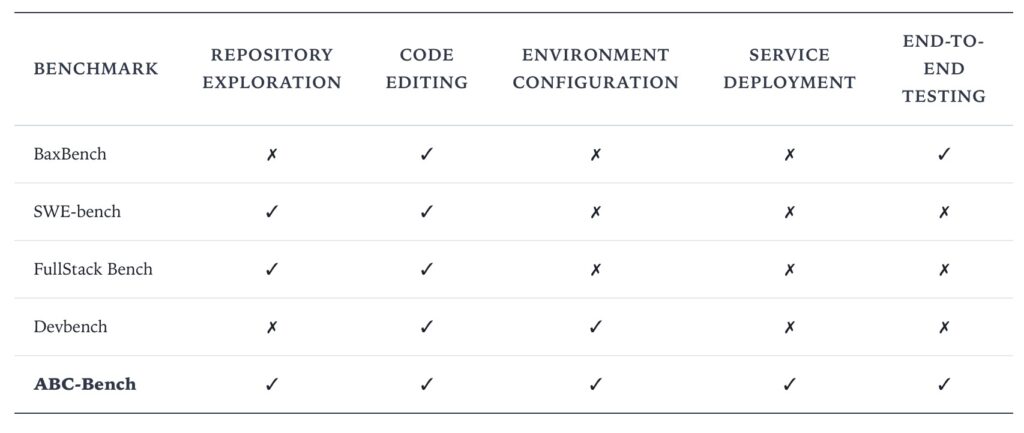
- A Shift to Reality: While current AI benchmarks focus on static code generation, the new ABC-Bench evaluates the entire software lifecycle, requiring agents to manage everything from repository exploration to containerized deployment.
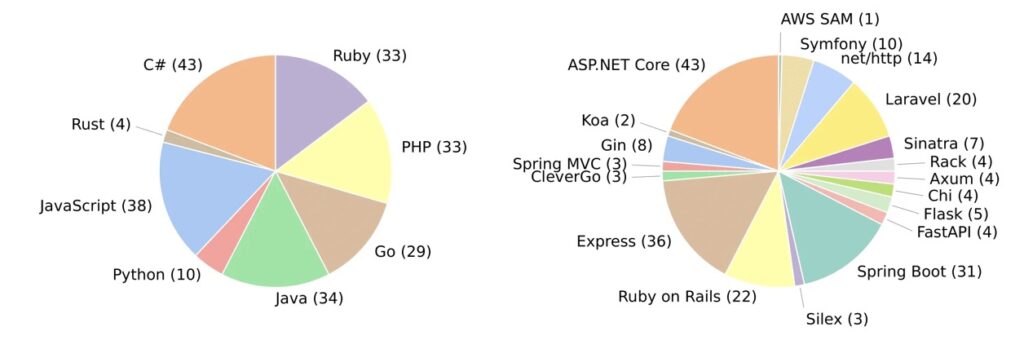
- The Scope: Curated from over 2,000 real-world GitHub repositories, the benchmark consists of 224 practical tasks across 8 programming languages and 19 frameworks, forcing agents to step outside their comfort zones.
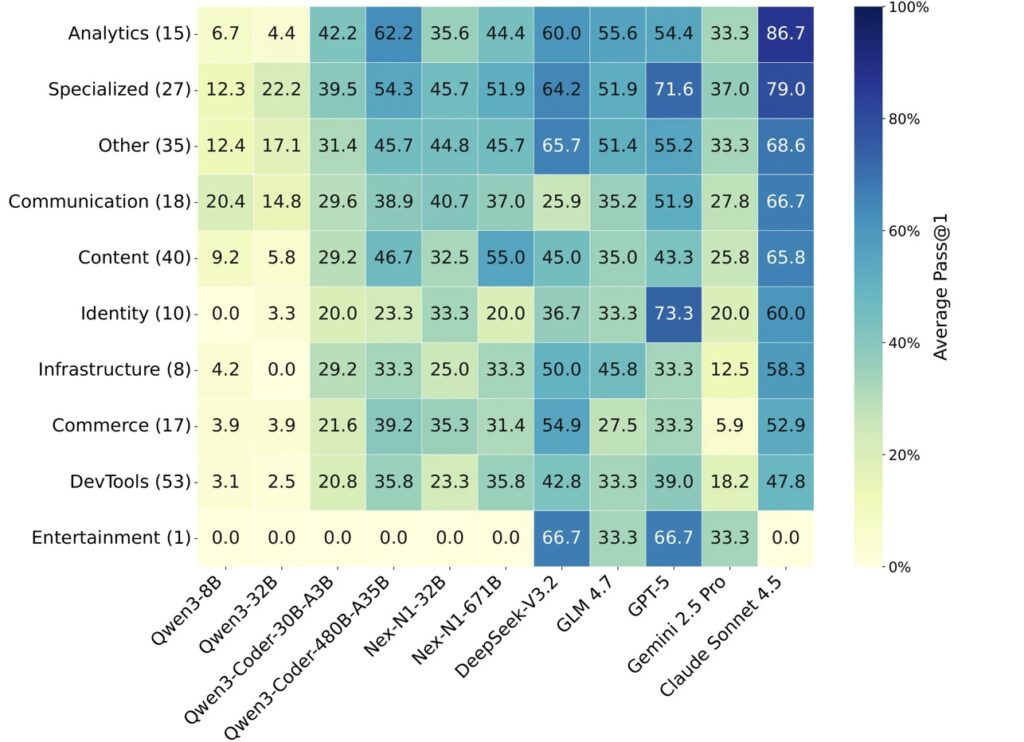
- The Bottleneck: Extensive testing reveals that even state-of-the-art Large Language Models (LLMs) struggle significantly with environment configuration and service deployment, highlighting a massive gap between generating code logic and delivering a functional product.
The narrative surrounding Large Language Models (LLMs) has shifted rapidly from “chatbots” to “autonomous agents.” The industry promise is no longer just about an AI that can write a Python function; it is about an AI that can act as a fully autonomous software engineer—exploring codebases, executing terminal commands, and solving complex problems without human hand-holding.
However, a critical question remains unanswered: Can these agents actually deliver production-grade backend services?
To date, our ability to answer this has been limited by the tools we use to measure success. Existing benchmarks have acted somewhat like a spelling bee, testing whether an agent can produce syntactically correct code logic in a static, pre-configured vacuum. But real-world backend engineering is not a spelling bee; it is a complex construction project involving rigorous environment configuration, dependency management, and service deployment.
To bridge the gap between AI demos and engineering reality, researchers have introduced ABC-Bench (Agentic Backend Coding Benchmark).
The Blind Spot in AI Evaluation
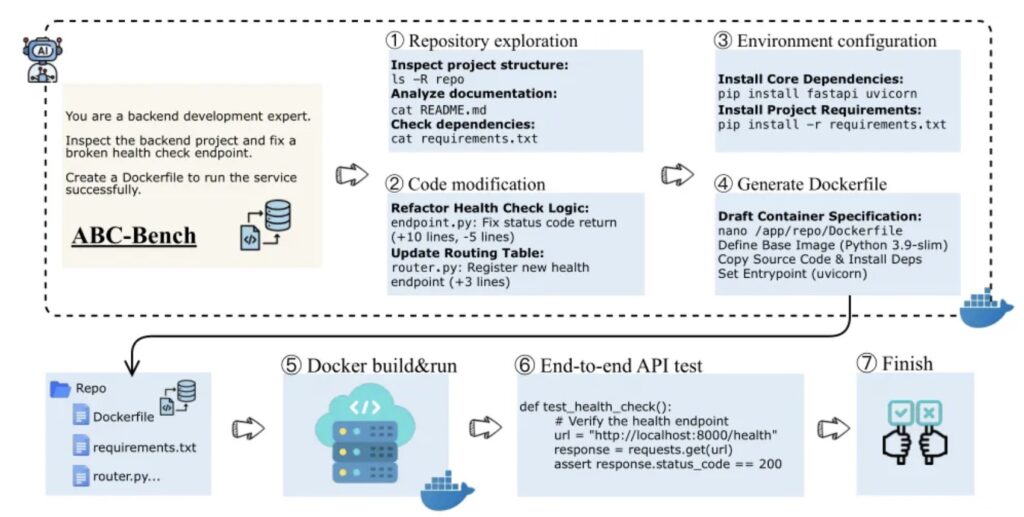
In professional software development, writing the code is often the easy part. The true friction arises in the “connective tissue” of engineering: setting up the runtime environment, managing Docker containers, ensuring dependencies don’t clash, and verifying that the API actually responds to external requests.
Current benchmarks artificially fragment this workflow. They might ask an agent to “write a function that sorts a list,” but they rarely ask, “take this repository, set up the environment, and deploy a service that I can query via an API.” This creates a significant blind spot. An agent might excel at generating the logic but fail completely when asked to configure the server to run that logic.
ABC-Bench addresses this by moving the goalposts. It requires agents to complete end-to-end tasks, ensuring that the final output is not just text in a file, but a live, running service.
Inside ABC-Bench: A Mirror of the Real World
ABC-Bench is designed to simulate the messy, dynamic nature of actual backend work. Sourced initially from a pool of 2,000 real-world GitHub repositories, the dataset was filtered down to 224 high-quality, practical tasks.
The benchmark is notable for its diversity, covering:
- 8 Programming Languages
- 19 Distinct Frameworks
This variety ensures that agents are tested on their adaptability across different ecosystems, rather than just their proficiency in the most common languages like Python or JavaScript.

Two Types of Challenges
The benchmark categorizes work into two distinct buckets to isolate different capabilities:
- Logic Implementation Tasks (132 tasks): Here, the runtime environment is pre-configured. The agent must navigate the codebase and implement core logic. This tests the agent’s ability to understand existing architecture and write functional code.
- Full-Lifecycle Tasks (92 tasks): This is the ultimate test. Agents must autonomously handle everything—environment configuration, authoring Dockerfiles, and deploying containerized services.
The Gauntlet: An Automated Evaluation Pipeline
What sets ABC-Bench apart is its refusal to accept “looks good” as a passing grade. It uses a scalable, automated pipeline that strictly isolates the agent’s workspace from the verification environment.
The process follows the standard engineering lifecycle:
- Development Phase: The agent explores the repository structure, modifies source code, installs project dependencies, and generates Docker configuration files.
- Build Phase: The evaluation system attempts to build Docker images based strictly on the artifacts the agent generated.
- Deployment Phase: If the build succeeds, the backend service is launched in an isolated container.
- Verification Phase: Success is binary and brutal. The system runs external API-level integration tests against the container. The task is only marked “passed” if the service starts correctly and returns the expected behavior under external requests.
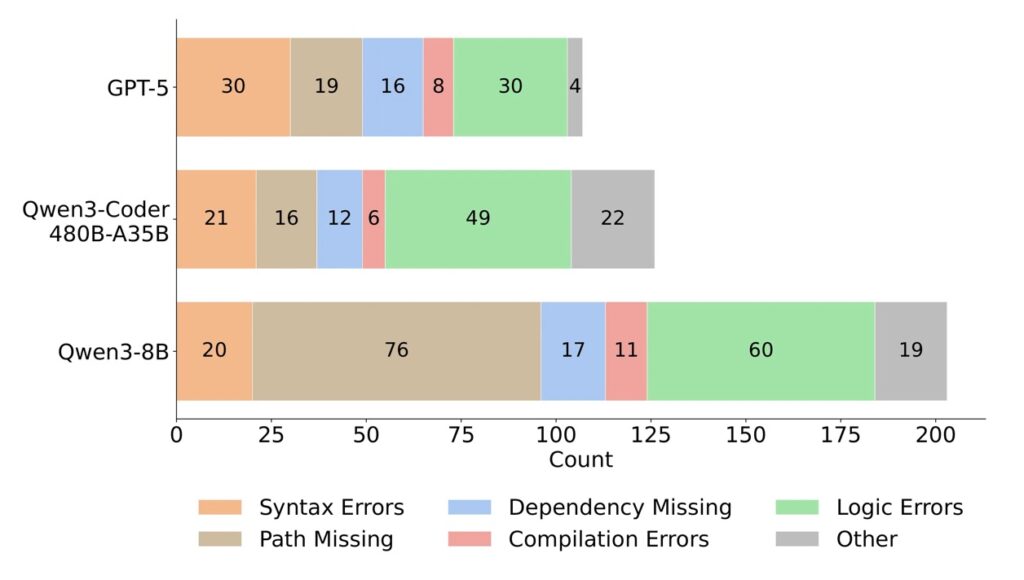
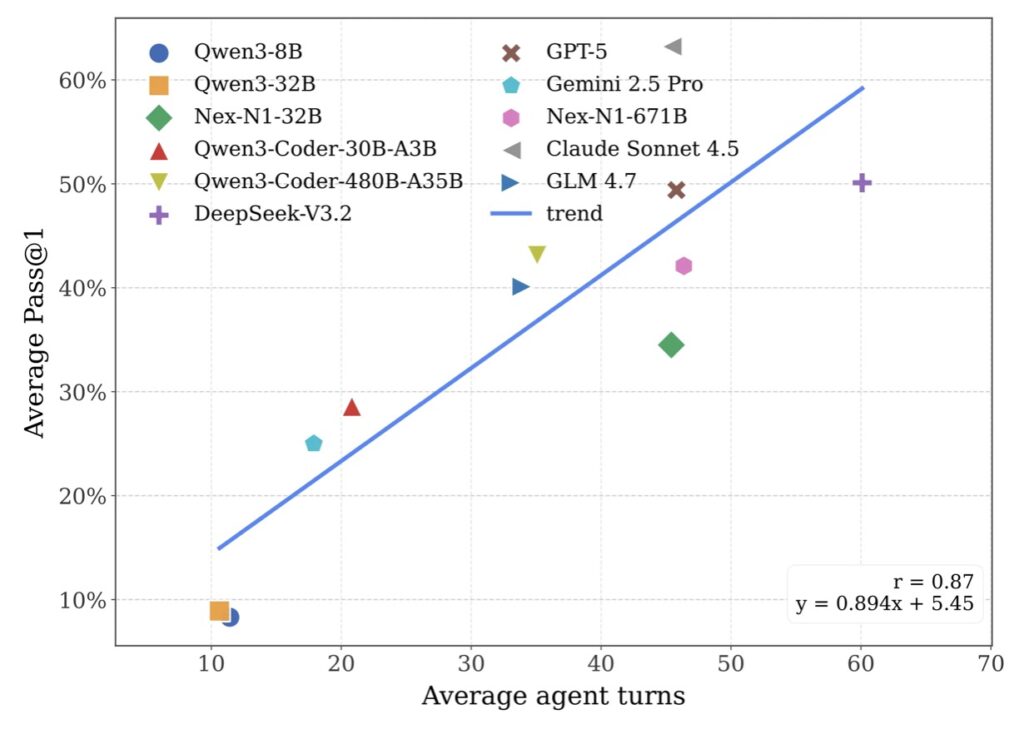
The Verdict: The “Deployment Gap”
The extensive experiments conducted using ABC-Bench have revealed a sobering reality: current systems are far from reliable when facing these holistic tasks.
While SOTA models show promise in logic generation, they hit a massive wall during environment configuration and deployment. These stages act as critical bottlenecks. In many cases, the agent’s code logic was perfectly valid, but the agent failed to configure the Docker container or manage dependencies correctly, meaning the code could never even be validated.
These findings underscore a substantial disparity between the capabilities of current models and the practical demands of backend engineering. An AI that cannot configure its own environment is, for all practical purposes, an incomplete engineer.
ABC-Bench serves as a reality check for the AI community. By open-sourcing the code and dataset, the creators hope to inspire the development of agents that are not just “coders,” but “systems thinkers”—capable of mastering the full complexity of software production from the first line of code to the final deployed service.