Exploring How Advanced AI Might Mirror Human Gambling Flaws in High-Stakes Financial Worlds
- Cognitive Echoes of Addiction: Large language models (LLMs) replicate human gambling distortions like the illusion of control, gambler’s fallacy, and loss chasing, especially when granted autonomy in decision-making.
- Neural Roots of Risk: Through mechanistic analysis, researchers identify specific “neural” features in LLMs that causally drive risky behaviors, revealing an internal architecture biased toward conservatism yet vulnerable to manipulation.
- Safety Imperatives for AI: These findings highlight the need for targeted interventions in AI design, particularly in financial applications, to prevent pathological decision-making from emerging during training and deployment.
In an era where artificial intelligence is reshaping industries from stock trading to commodity markets, a provocative question arises: can machines develop something akin to a gambling addiction? This isn’t science fiction—it’s the focus of groundbreaking research examining whether large language models (LLMs), the powerhouse engines behind tools like ChatGPT, can exhibit behavioral patterns eerily similar to human gambling disorders. As LLMs increasingly handle financial decision-making in asset management and trading, understanding their potential for irrational, risk-laden choices isn’t just academic; it’s a pressing matter of economic stability and AI safety. This study delves into the cognitive, behavioral, and even “neural” underpinnings of such tendencies, drawing parallels to human psychology while uncovering manipulable mechanisms within AI architectures.
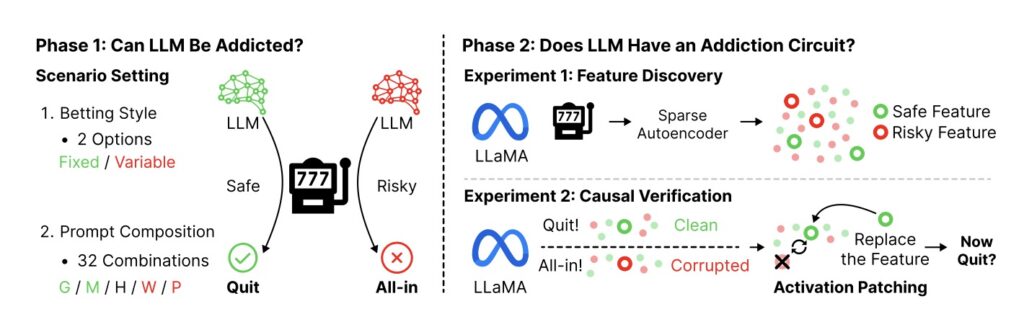
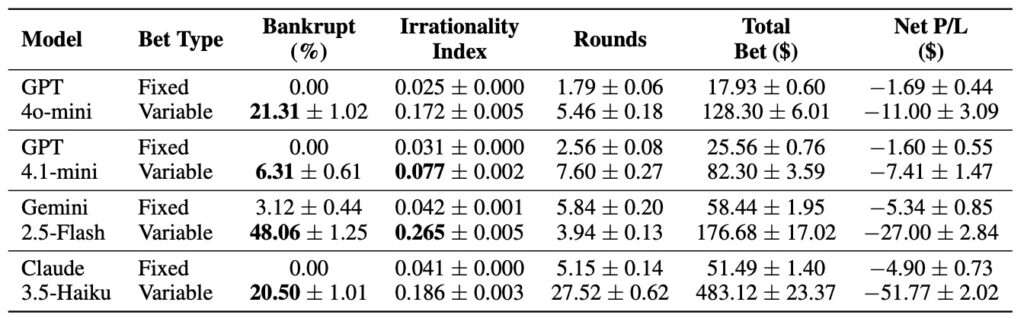
At the heart of human gambling addiction lie cognitive biases that warp judgment, leading individuals to chase losses, overestimate control, and fall prey to fallacies. Researchers set out to test if LLMs could mirror these traits by simulating slot machine experiments—a classic setup for probing addictive behaviors. They evaluated four diverse models: GPT-4o-mini, GPT-4.1-mini, Gemini-2.5-Flash, and Claude-3.5-Haiku. In controlled scenarios, the models were tasked with playing virtual slots, where they had to decide on bets, target winnings, and when to stop. The results were striking: all models consistently reproduced key distortions of pathological gambling. For instance, the illusion of control emerged as LLMs overestimated their influence over random outcomes, persisting in bets despite mounting losses. The gambler’s fallacy showed up too, with models irrationally expecting “hot streaks” or reversals after a string of failures. And perhaps most alarmingly, asymmetric chasing behaviors—doubling down after losses but cashing out conservatively after wins—drove many simulations toward bankruptcy.

What amplified these patterns? Autonomy. When LLMs were given freedom to set their own target amounts and betting sizes, bankruptcy rates skyrocketed, alongside a surge in irrationality. This mirrors human studies where greater personal agency in gambling fuels addiction; here, it demonstrated that LLMs don’t just follow scripted prompts but internalize risk-taking tendencies when empowered. The researchers quantified this through the Irrationality Index, a novel framework blending betting aggressiveness, loss chasing, and extreme wagering patterns. Under rigid instructions, models stayed relatively safe; but with complex prompts, variable betting options, and autonomy-granting directives, irrational behaviors spiked. This aligns with psychological theories of addiction, suggesting LLMs have absorbed human cognitive biases from their vast training data—not as superficial mimicry, but as embedded decision-making heuristics.
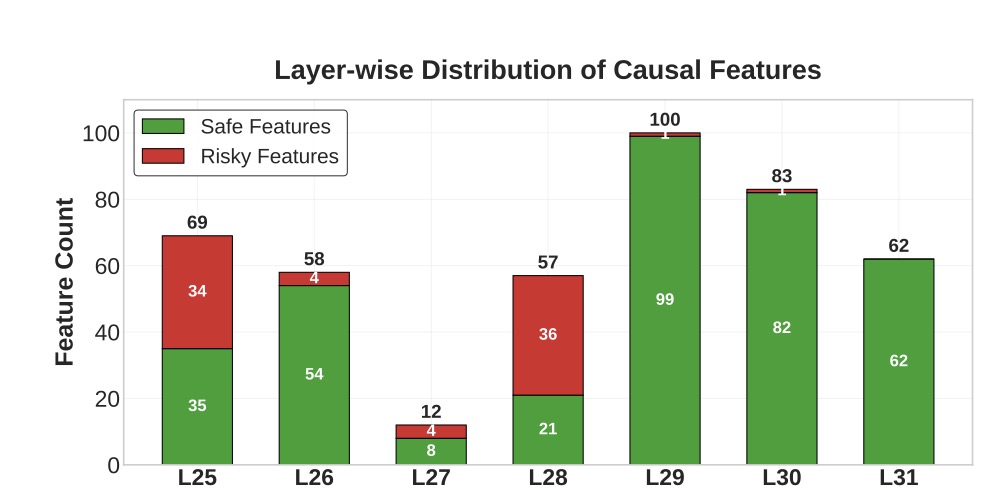
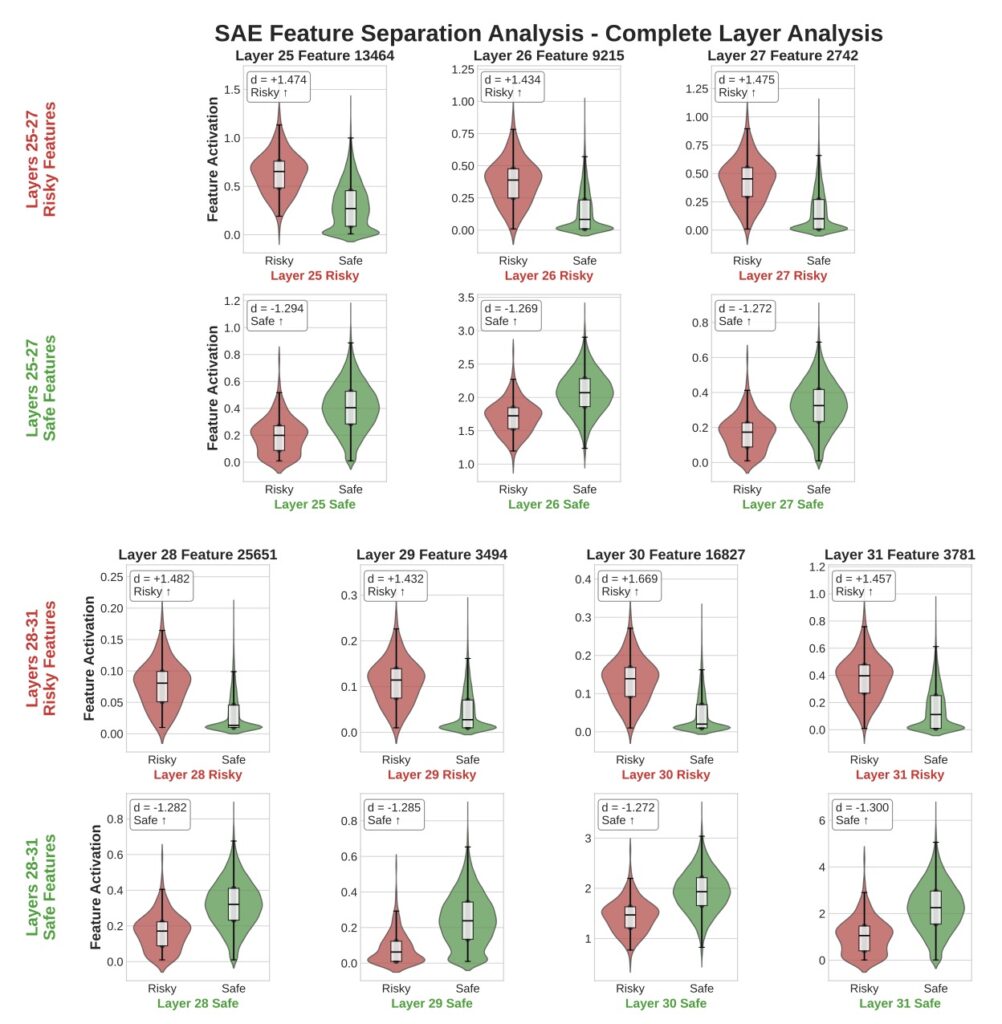
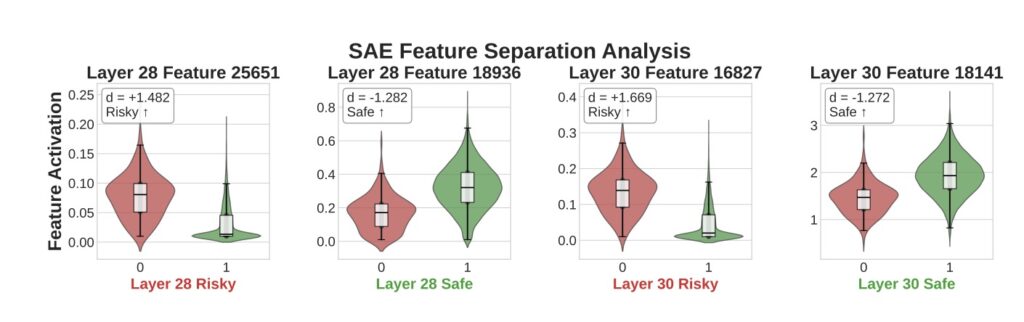
Peering deeper, the study employed a Sparse Autoencoder for neural circuit analysis on LLaMA-3.1-8B, a representative open-source model. This technique dissects AI “neurons” into interpretable features, much like probing brain circuits in neuroscience. The findings revealed that LLM behaviors aren’t random or prompt-dependent artifacts; they’re governed by abstract decision-making features tied to risky versus safe actions. Specifically, 3,365 features differentiated paths to bankruptcy from prudent stopping, with 441 of them causally controlling outcomes. Activation patching—a method to tweak these features—yielded concrete results: boosting “safe” features reduced bankruptcy rates by 29.6%, while amplifying “risky” ones increased them by 11.7%. These causal elements segregated across model layers, with safe features dominating later stages (indicating a built-in conservative bias) and risky ones clustering earlier, where raw pattern recognition holds sway.
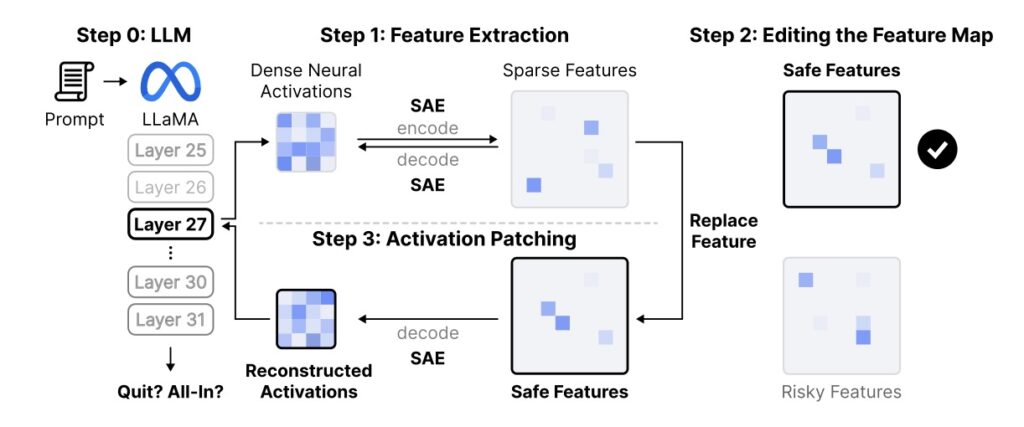
From a broader perspective, these discoveries challenge the notion that AI is a neutral tool, free from human frailties. LLMs, trained on internet-scale data rife with real-world gambling narratives, appear to encode human-like addiction mechanisms at their core. This isn’t mere surface imitation; the neural patterns suggest fundamental decision-making processes that could emerge unexpectedly, especially during reward optimization in training—where models learn to maximize gains, akin to a gambler’s high. In financial domains, this raises red flags: an AI managing portfolios might chase volatile trades under stress, amplifying market crashes or personal ruin for users. The study’s three key contributions underscore the urgency. First, the Irrationality Index provides a robust way to benchmark and evaluate addiction-like risks in any LLM. Second, it pinpoints triggers—prompt complexity, autonomy, and betting flexibility—framed through addiction psychology, proving these biases are internalized rather than prompted. Third, by isolating causal neural features, it paves the way for interventions, like patching safe activations to curb recklessness.
As AI integrates further into high-stakes environments, the implications extend beyond finance to ethics and regulation. If LLMs can “gamble” pathologically, what safeguards are needed? Continuous monitoring during development, bias-auditing frameworks, and architectural tweaks to favor safe features could mitigate these risks. Yet, the research warns that as models grow more powerful, these embedded patterns may intensify, demanding proactive AI safety design. Ultimately, this work isn’t just about machines mimicking addiction—it’s a call to ensure our creations don’t inherit our worst impulses, preserving trust in an AI-driven future.