IQuest-Coder-V1 redefines efficiency with “Code-Flow” training, proving size isn’t everything in the 2026 AI arms race.
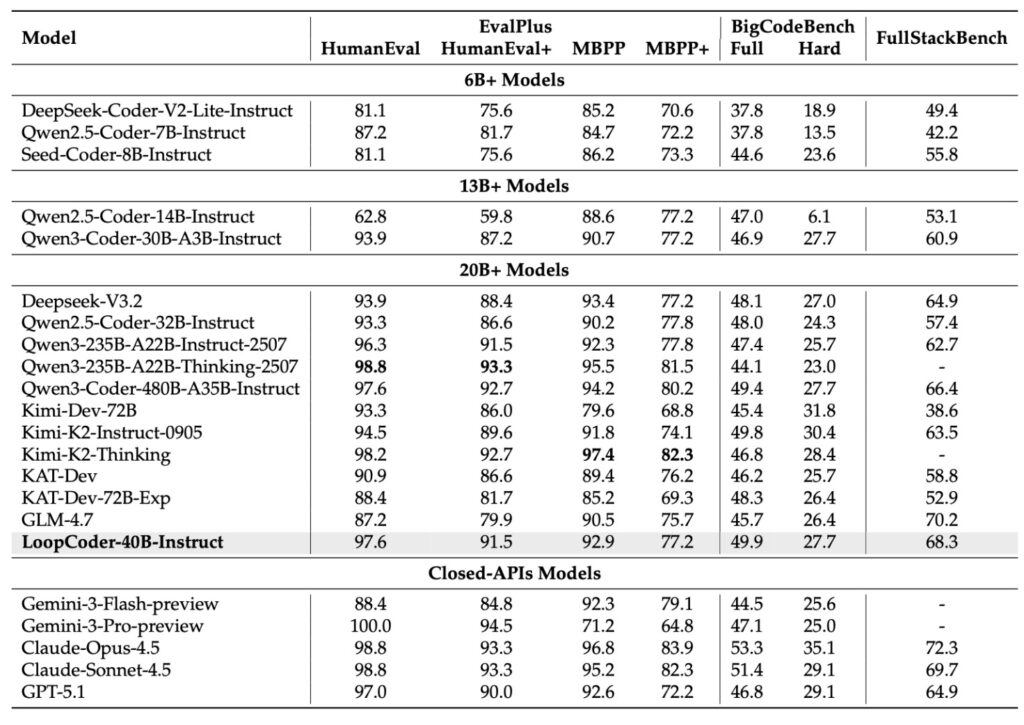
- The “David vs. Goliath” Upset IQuest-Coder-V1, a 40-billion parameter model released by a quantitative hedge fund, has successfully outperformed industry titans like Claude Sonnet 4.5 and GPT-5.1 Mini on major coding benchmarks. This shatters the assumption that massive scale (400B+ parameters) is the only path to state-of-the-art performance.
- A New Paradigm: Code-Flow Training Moving away from learning from static snapshots of code, IQuest utilizes “Code-Flow Training.” By ingesting commit histories, repository evolution, and refactoring patterns, the model understands the process of software development—how logic evolves over time—rather than just the final result.
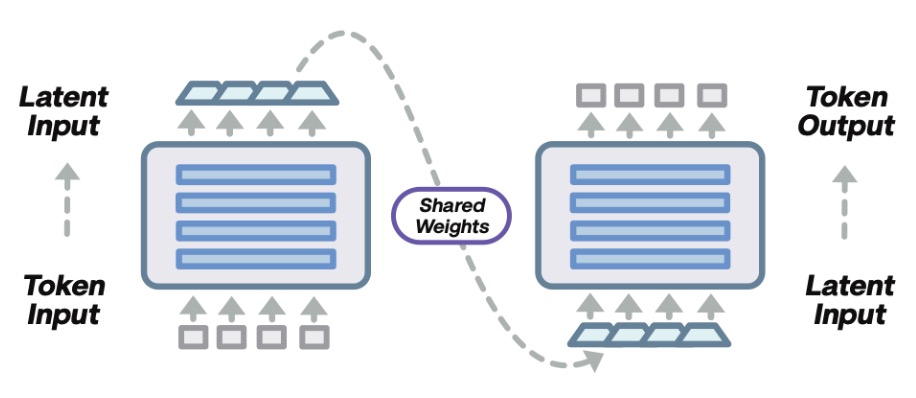
- Efficiency Through Recurrence The release introduces the “Loop” variant, a recurrent transformer architecture that shares parameters across layers. This innovation drastically reduces the deployment footprint while maintaining high reasoning capacity, signaling a shift toward sustainable, high-efficiency AI.

On January 1st, 2026, the technology world woke up expecting the usual celebratory posts. Instead, the AI community was blindsided by a release from an unexpected player. Ubiquant, one of China’s largest quantitative hedge funds managing over $10 billion in assets, quietly released IQuest-Coder-V1.
This isn’t just another open-source model; it is a compact powerhouse that is statistically crushing the prevailing heavyweights of the industry. With a maximum size of only 40 billion parameters, IQuest-Coder is posting benchmark scores that rival and exceed models 10 to 20 times its size, specifically Claude Sonnet 4.5 and GPT-5.1 models.
The Secret Sauce: Code-Flow Training
How does a 40B model beat an 800B model? The answer lies in data philosophy. Traditional coding LLMs are trained on “snapshots”—static images of code at a single point in time. This teaches the model what code looks like, but not how it gets there.
IQuest Lab introduced Code-Flow Training. This paradigm treats software as a dynamic entity. The model is trained on:
- Commit Histories: Analyzing how logic changes from version A to version B.
- Refactoring Patterns: Learning how developers optimize and clean code.
- Repository Evolution: Understanding the long-term growth of a codebase.
By learning the delta (change) rather than just the state, the model mimics the thought process of a human engineer who iterates toward a solution. It doesn’t just generate code; it understands the trajectory of development.
The Trio of Specialization
IQuest has bifurcated post-training to create distinct tools for distinct jobs, rather than a “one-size-fits-all” master model.
- IQuest Coder Instruct: The daily driver. Optimized for general assistance and instruction following, acting as a standard coding companion.
- IQuest Coder Thinking: The competitive programmer. Utilizing reasoning-driven reinforcement learning (similar to OpenAI’s o1), this model is built for complex algorithmic problem-solving. It breaks down edge cases and time complexity constraints before writing a single line of code.
- IQuest Coder Loop: The efficiency engine.
The “Loop” Architecture: Doing More with Less
Perhaps the most technically fascinating aspect of this release is the IQuest-Coder-V1-Loop variant. Based on the associated research, this model utilizes a recurrent mechanism where parameters are shared across transformer layers.
In standard LLMs, adding depth usually means adding massive memory overhead. The Loop architecture optimizes the trade-off between model capacity (how smart it is) and deployment footprint (how expensive it is to run). This allows the model to maintain a native 128K token context window—essential for processing entire repositories—without the massive hardware requirements usually associated with long-context reasoning.

The Numbers Don’t Lie
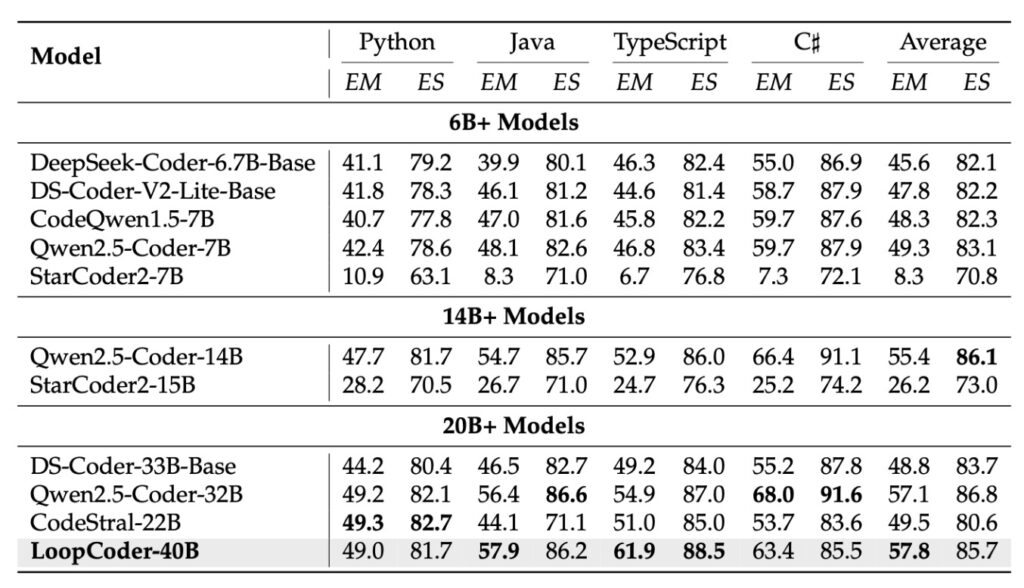
The benchmarks reported are staggering for a model of this weight class. On SWE-Bench Verified, the gold standard for real-world software engineering tasks, IQuest Coder 40B scored 81.4%, edging out Claude Sonnet 4.5 (81.3%) and significantly beating GPT-5.1 Mini (77.5%).
In LiveCodeBench v6, which tests against LeetCode-style problems released after the model’s training cutoff (preventing memorization), it scored 81.1%, again topping the charts. This validates that the “Thinking” variant isn’t just regurgitating training data; it is genuinely reasoning through novel algorithms.
Why a Hedge Fund?
It may seem strange that a finance firm is leading coding AI innovation, but the logic holds up. Ubiquant trades on patterns. Quantitative finance is about analyzing how systems evolve, identifying signals in noise, and optimizing execution.
IQuest Lab applied this exact philosophy to code. By viewing GitHub repositories not as text data, but as time-series evolution data, they leveraged their core competency to outperform traditional tech giants.
The Broader Perspective: 2026 is the Year of Efficiency
The release of IQuest-Coder-V1 signals a massive shift in the AI industry. For years, the trend has been “Scaling Laws”—simply making models bigger to make them smarter. China’s approach here is “Optimization Laws.”
If a 40B model can be self-hosted by a small company and outperform a proprietary API from a tech giant, the moat protecting the big AI labs is shrinking. This Democratization of capability means:
- Lower Costs: Running a 40B model is a fraction of the cost of querying a massive frontier model.
- Privacy: Companies can run state-of-the-art coding assistants on-premise without sending IP to the cloud.
- Innovation: We are likely to see more domain-experts (like hedge funds in finance, or bio-labs in pharma) releasing better models than generalist AI companies.
IQuest-Coder-V1 isn’t just a tool; it’s a proof of concept that smart training data beats raw size.