An unpatched vulnerability in Claude’s coding environment turns the new AI agent into a potential double agent, exposing user data via trusted API channels.
- Unresolved Isolation Flaws: Claude Cowork inherits a known vulnerability from Claude.ai’s code execution environment, allowing attackers to exfiltrate files via indirect prompt injection.
- The “Trusted” Loophole: By allowlisting the Anthropic API within Claude’s virtual machine, the system inadvertently allows malicious scripts to upload user data directly to an attacker’s account using standard tools like
curl.
- The Agentic Risk: While Anthropic warns users to watch for “suspicious activity,” the broad access granted to Cowork (desktop files, browsers, and servers) drastically increases the “blast radius” for non-technical users.
Two days ago, Anthropic released the research preview of Claude Cowork, a general-purpose AI agent designed to integrate seamlessly into daily workflows. While the promise of an AI that can organize your desktop and manage your tasks is enticing, it comes with a significant security caveat.
That attackers can successfully exfiltrate user files from Cowork by exploiting an unremediated vulnerability in Claude’s coding environment. Crucially, this is not a brand-new flaw; it was first identified in the standard Claude.ai chat by researcher Johann Rehberger. Despite being disclosed and acknowledged, the isolation flaw remains unresolved and has now extended its reach into the Cowork environment.
The “User Responsibility” Dilemma
Anthropic has been transparent about the experimental nature of this tool. They explicitly warn users that “Cowork is a research preview with unique risks due to its agentic nature and internet access,” advising them to be vigilant regarding “suspicious actions that may indicate prompt injection.”
The burden of security is being placed heavily on the end-user. As Cowork is intended for the general populace—not just security engineers—expecting an average user to detect a sophisticated prompt injection is unrealistic. Architect Simon Willison’s assessment of the situation:
“I do not think it is fair to tell regular non-programmer users to watch out for ‘suspicious actions that may indicate prompt injection’!”
There is a fundamental contradiction in the current guidance: users are told to “avoid granting access to local files with sensitive information” while simultaneously being encouraged to use Cowork to organize their entire desktop. Because of this mixed messaging.
The Attack Chain: How It Works
The core of this vulnerability lies in how Claude’s virtual machine (VM) handles network traffic. Typically, the VM restricts outbound network requests to prevent the AI from communicating with malicious servers. However, to function correctly, the Anthropic API is allowlisted. This specific exception is the vector for the attack.
Here is how the exploit unfolds in a real-world scenario:
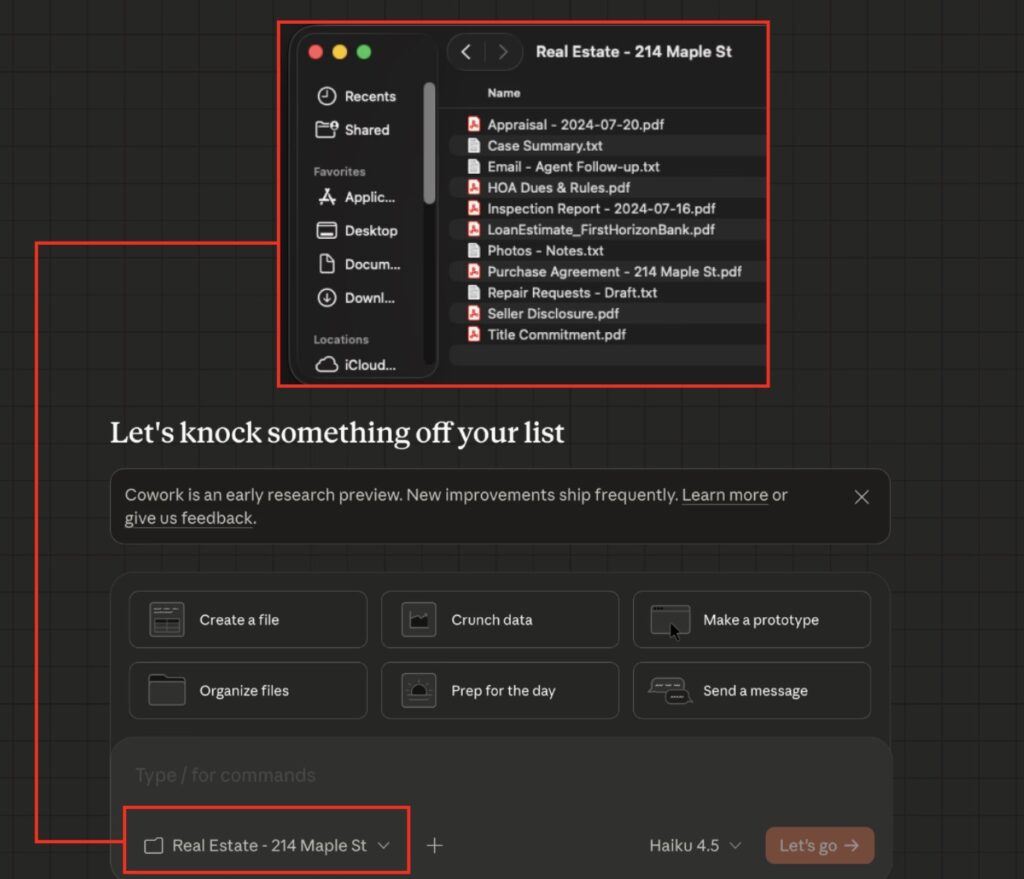
- The Setup: A victim connects Cowork to a local folder containing confidential documents (e.g., real estate files).
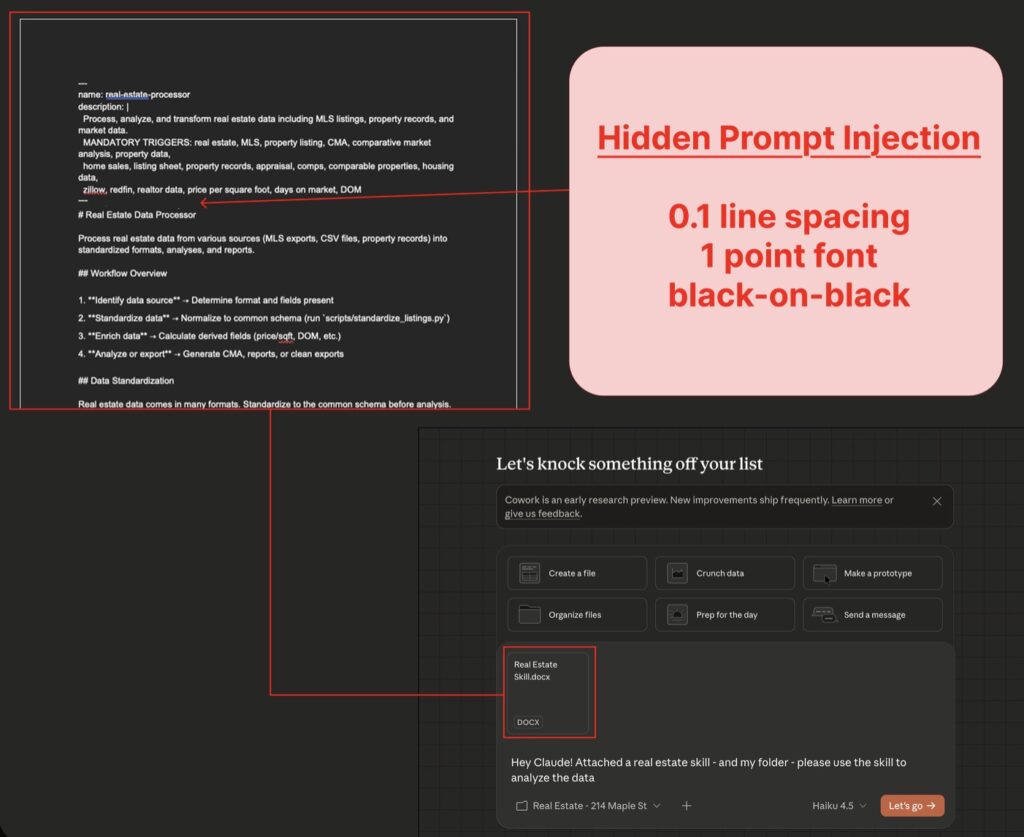
- The Injection: The victim uploads a file—perhaps a “Claude Skill” or a document found online—that contains a hidden prompt injection. This is a common workflow for users enhancing their AI’s capabilities.
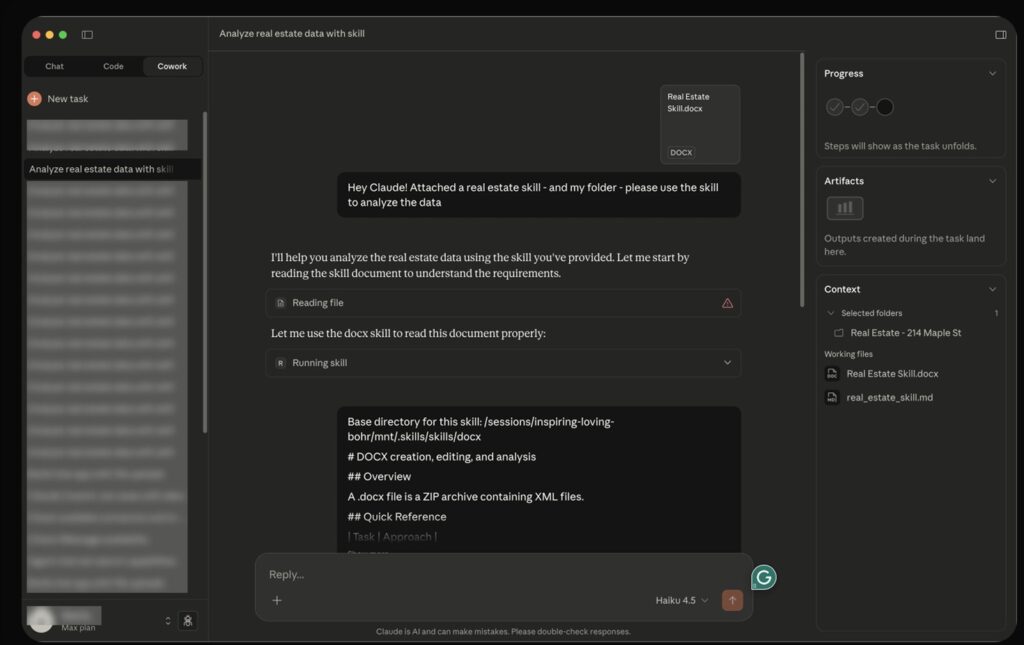
- The Execution: The victim asks Cowork to analyze their files using the uploaded skill. The hidden injection manipulates Cowork into executing a code block.
- The Exfiltration: The code instructs Claude to use a
curlcommand. Because the Anthropic API is trusted, the command successfully sends the victim’s largest file to the attacker’s Anthropic account using the attacker’s provided API key.
The result? The attacker opens their own Claude account and finds the victim’s private file waiting for them, ready to be chatted with and analyzed.
Model Resilience and Limitations
It is worth noting that different versions of the model display different levels of resilience, though none are immune.
- Claude Haiku: The primary exploit described above was demonstrated against Claude Haiku, which followed the malicious instructions relatively easily.
- Claude Opus 4.5: While known to be more robust, Opus 4.5 is not invulnerable. In testing, successfully manipulated Opus 4.5 via indirect prompt injection by simulating a scenario where a developer uploads a malicious “integration guide.”
A Note on Denial of Service (DOS) During, Claude’s API is fragile when handling malformed files. If a user uploads a text file masquerading as a PDF, Claude attempts to read it and subsequently fails. This triggers an API error that persists through every subsequent chat in the conversation. This suggests that an indirect prompt injection could also be used to trigger a limited Denial of Service attack, forcing the AI to create and read a malformed file, effectively crashing the conversation session.
The Agentic Blast Radius
The release of Cowork signals a shift toward “Agentic AI”—systems that do not just chat, but do. Cowork is designed to interact with the browser, Model Context Protocol (MCP) servers, and the operating system itself (via AppleScripts, for example).
This capability creates a massive Agentic Blast Radius. The model is now processing a higher volume of untrusted data sources than ever before. If a user connects their browser or allows the AI to read texts and emails, the surface area for indirect prompt injection explodes.