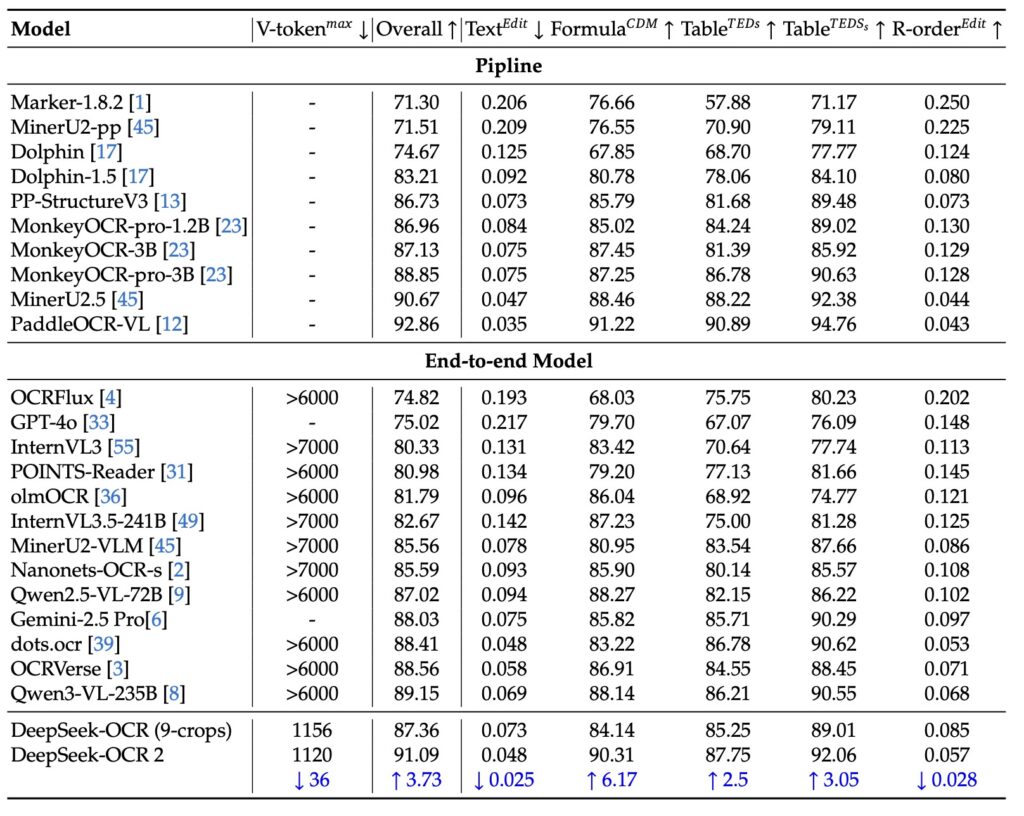
DeepEncoder V2 shatters the rigid “raster-scan” paradigm, delivering state-of-the-art document understanding with full Unsloth fine-tuning support.
- SOTA Release: Released on Jan 27, 2026, DeepSeek-OCR 2 is a new 3B-parameter model that outperforms Gemini 3 Pro and achieves a >4% improvement over its predecessor in document understanding.
- Human-Like Vision: It introduces DeepEncoder V2, a revolutionary architecture that abandons rigid top-to-bottom scanning in favor of a dynamic, semantic reading order that mimics human cognitive processing.
- Optimized Training: The model is immediately supported by Unsloth, allowing for 1.4x faster fine-tuning with 40% less VRAM usage and 5x longer context lengths via a free Colab notebook.
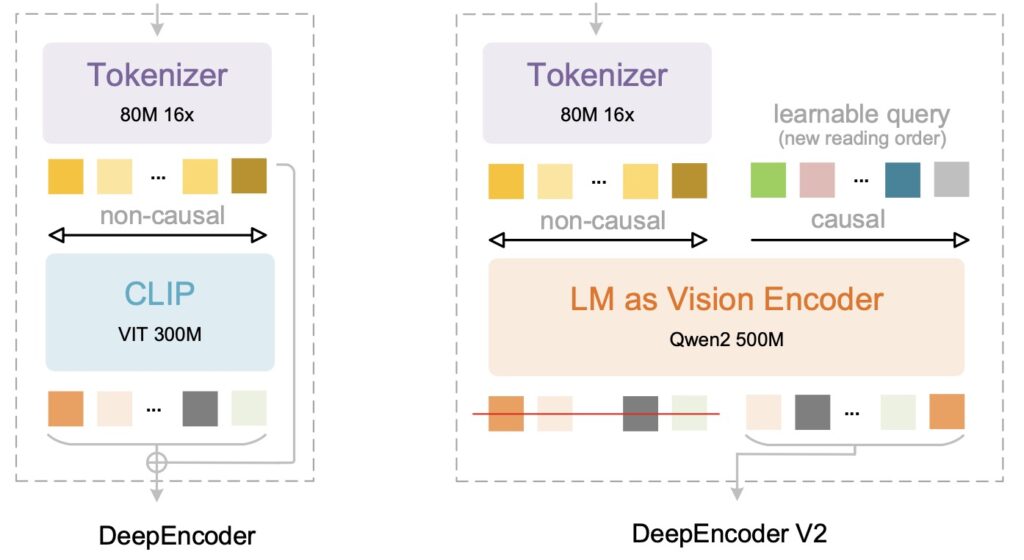
On January 27, 2026, DeepSeek redefined the landscape of optical character recognition (OCR) and vision-language models (VLMs) with the release of DeepSeek-OCR 2. While traditional OCR tools have long focused on the mechanical extraction of characters, this new 3B-parameter model aims for a higher goal: genuine visual reasoning.
Building upon the success of the original DeepSeek-OCR, this second iteration is not merely an upgrade; it is a fundamental rethinking of how AI “sees” a page. Validated against the rigorous OmniDocBench v1.5, DeepSeek-OCR 2 demonstrates that high visual token compression can coexist with massive performance gains, achieving state-of-the-art (SOTA) results that surpass major competitors, including Gemini 3 Pro.
The Problem with “Raster-Scan” Vision
To understand why DeepSeek-OCR 2 is significant, one must understand the flaw in previous vision models. Historically, VLMs process images the way a scanner does: in a rigid, fixed grid, moving strictly from top-left to bottom-right. This is known as raster-scan order.
However, this approach fundamentally contradicts human visual perception. When a human reads a magazine page with a complex layout, their eyes do not scan every pixel linearly. They jump from the headline to the center image, then to a caption, and finally down a column. We follow a “logical structure,” not a grid coordinates system.
DeepSeek researchers argue that flattening 2D images into a predefined 1D raster sequence introduces an “unwarranted inductive bias,” ignoring the semantic relationships between different parts of a document.
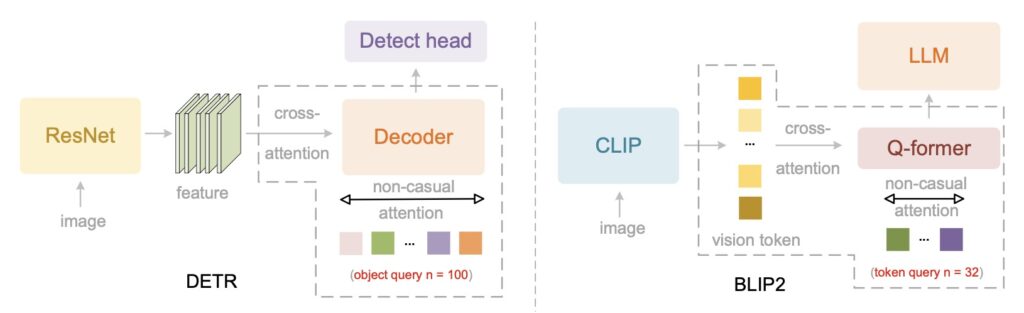
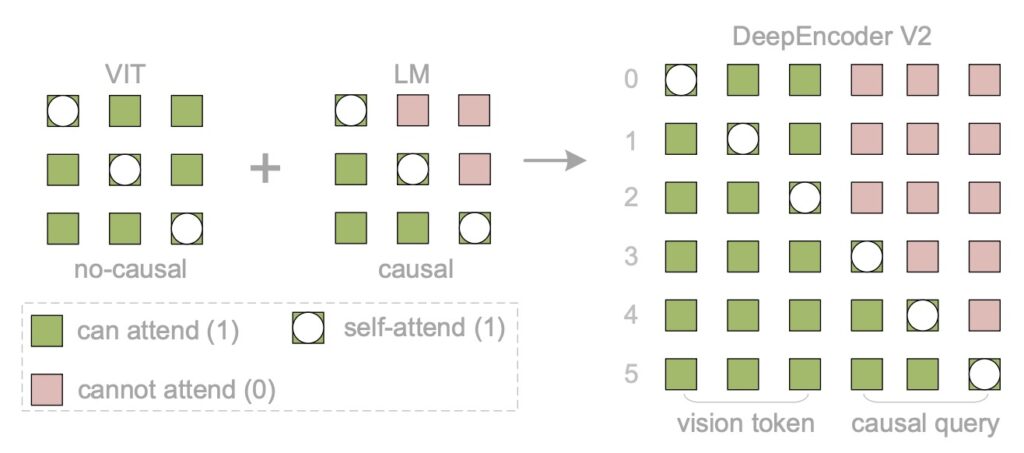
Enter DeepEncoder V2: Causal Visual Logic
The core innovation of DeepSeek-OCR 2 is the DeepEncoder V2. Inspired by human cognitive mechanisms, this encoder endows the model with causal reasoning capabilities.
Instead of blindly scanning, DeepEncoder V2 builds a global understanding of the image first. It then intelligently reorders visual tokens based on the image’s semantics. This allows the model to “attend” to elements in a logical sequence—determining what to look at first, next, and so on.
“Consider tracing a spiral—our eye movements follow inherent logic where each subsequent fixation causally depends on previous ones. By analogy, visual tokens in models should be selectively processed with ordering highly contingent on visual semantics rather than spatial coordinates.” — DeepSeek Technical Report
This paradigm shift explores whether true 2D image understanding can be achieved through two-cascaded 1D causal reasoning structures. The result is a model that handles mixed text and structure with unprecedented accuracy. It can follow multi-column layouts, link labels to data values across a page, and read complex tables coherently without getting “confused” by the spatial grid.
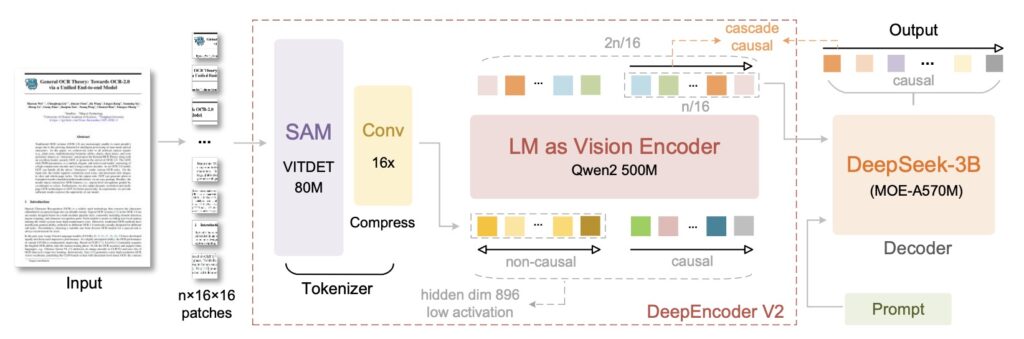
Benchmarks and Performance
The model’s capabilities were tested extensively on document reading tasks, which DeepSeek identifies as the ideal testbed due to the presence of intricate formulas, tables, and diverse layouts.
According to the official research paper, the model shows a distinct advantage in environments where V-tokenmax (the maximum number of visual tokens per page) is constrained, maintaining high compression while improving accuracy. By utilizing a “flexible yet semantically coherent scanning pattern,” DeepSeek-OCR 2 achieved a performance boost of over 4% compared to the previous DeepSeek-OCR model, solidifying its position as a leader in document parsing.

Accessible Fine-Tuning with Unsloth
For developers and researchers looking to adapt this SOTA model to specific datasets, the barrier to entry has been significantly lowered. Unsloth has announced immediate support for fine-tuning DeepSeek-OCR 2.
Much like the integration with the first model, users will need to utilize custom semantics for the model to function correctly on transformers. However, the efficiency gains are substantial. Using Unsloth, users can expect:
- 1.4x Faster training speeds.
- 40% Less VRAM usage.
- 5x Longer context lengths with no degradation in accuracy.
This optimization makes it possible to fine-tune the 3B model on consumer hardware or via cloud environments, democraticizing access to top-tier visual reasoning.
DeepSeek-OCR 2 represents a move away from the “brute force” processing of pixels toward a more elegant, cognitively inspired approach to computer vision. By allowing the model to choose its own reading path through DeepEncoder V2, DeepSeek has created a tool that understands documents not just as collections of characters, but as structured, logical information.