How eliminating custom kernels and simplifying normalization unlocks production-scale performance for Differential Transformers.
- Production-Ready Inference: DIFF V2 eliminates the need for custom attention kernels, matching standard Transformer decoding speeds and fully utilizing FlashAttention.
- Enhanced Stability: By removing per-head RMSNorm and introducing token-specific λ, the model drastically reduces gradient spikes and activation outliers during large-scale pretraining.
- Superior Performance: Empirical results on dense models and 30A3 MoE (Mixture of Experts) show notably lower language modeling loss compared to Gated Attention and standard Transformer baselines.
The original Differential Transformer (DIFF V1) introduced a promising concept: calculating attention scores by taking the difference between two separate attention maps. However, it came with engineering baggage—specifically, the need for custom kernels and slower decoding speeds due to memory-bound operations.
Differential Transformer V2 (DIFF V2), a revision designed for architectural elegance and production efficiency. While maintaining the core theoretical benefits of differential attention, V2 restructures the parameterization to ensure training stability on trillions of tokens and seamless integration with existing hardware optimization stacks.
Breaking the Speed Limit: Inference & Kernels
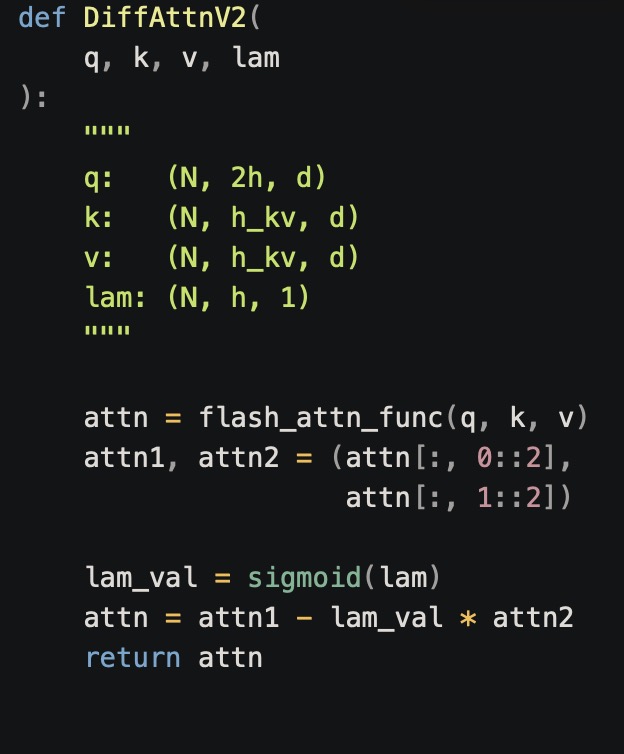
The most significant operational shift in DIFF V2 is the removal of the constraint that forced attention parameters to match the baseline Transformer exactly. In DIFF V1, this constraint often led to complex implementations.
DIFF V2 introduces additional parameters for the second query Q2, borrowed from other parts of the model (specifically saving on the output projection, WO). By doubling the number of query heads while keeping the number of key-value (KV) heads constant, DIFF V2 aligns perfectly with Grouped Query Attention (GQA).
This alignment means DIFF V2 can directly utilize FlashAttention without custom kernels. Since LLM decoding is typically memory-bound, this design allows DIFF V2 to match the decoding speed of a standard Transformer. In contrast, V1 required loading the value cache twice, reducing throughput.
Note on Efficiency: When using cutting-edge FlashAttention kernels on H-series and B-series GPUs, the throughput reduction introduced by DIFF V2 during pretraining is negligible.
Architectural Stability: The RMSNorm Problem
One of the critical findings during the development of V2 was the source of instability in large-scale pretraining. In V1, a per-head RMSNorm was applied after the differential attention.
This massive magnification led to exploding gradients and numerical instability. DIFF V2 removes this per-head RMSNorm. Additionally, it replaces the globally shared λ with a token-specific, head-wise projected λ. This eliminates the exponential re-parameterization required in V1 and results in a gradient norm scale comparable to standard Transformers.

Theoretical Motivation: Why Differentiate?
Why not simply let a standard Transformer learn to be differential? In theory, a standard Transformer with 2h heads could learn the differential operation by setting the output projection of one head to be the negative of another: WO2i=−WO2i+1.
- Optimization Difficulty: It is difficult for a model to learn two sets of parameters that converge to exact negatives of each other purely through optimization.
- Structural Efficiency: By explicitly constructing the differential operation before the output projection, DIFF V2 saves half of the WO parameters.
Since WQ and WO dominate the attention module’s parameter count, DIFF V2 saves approximately 25% of the attention-module parameters. These savings are reallocated to other parts of the model to boost capacity.
Empirical Results: Validating at Scale
Experiments were conducted on production-scale LLMs, including 1.3B dense models and a 30A3 MoE trained on trillions of tokens using large learning rates (6e−4 to 1e−3).
Key Observations:
- Lower Loss: DIFF V2 outperforms Gated Attention, which in turn outperforms standard Transformer variants (even those with extra FFN parameters to match parameter counts). In the 30A3 MoE setting (1T tokens), DIFF V2 achieved a loss gap of approximately 0.02 over Gated Attention.
- Reduced Outliers: The architecture exhibits reduced activation outlier magnitudes.
- Stability: Unlike the baseline Transformer, which becomes unstable at these large learning rates, DIFF V2 maintains reduced loss and gradient spikes.
Design Ablations: What Doesn’t Work
To confirm the design choices, several ablations were tested. These failures highlight the importance of the specific architectural choices in V2:
- Non-GQA Subtraction: Subtracting two heads that do not share the same Key and Value leads to significant training instability. The shared history is crucial.
- Removing λ: Subtracting attention maps directly (attn1−attn2) without the λ scaling factor results in an excessively small context RMS at initialization.
- Unbounded λ: Using a projected λ without a sigmoid operation leaves the context RMS unbounded, reducing stability.
Future Outlook
The differential mechanism’s ability to cancel out small attention values may help mitigate attention rounding errors, a common issue in long-context processing. Current experiments are ongoing to evaluate:
- Learning efficiency in mid- and post-training stages.
- Performance on downstream long-context benchmarks to see if DIFF V2 alleviates “context rot.”
By simplifying the parameterization and aligning with standard hardware kernels, DIFF V2 represents a mature step forward for differential attention, moving it from a theoretical curiosity to a viable candidate for the next generation of foundation models.