How Image Diffusion Models Are Now Powering Scalable, High-Fidelity 3D Gaussian Splat Generation
- 2D to 3D Leap: DiffSplat repurposes massive image diffusion models to generate 3D Gaussian splats, combining 2D generative priors with 3D consistency.
- Speed and Scalability: A lightweight reconstruction model curates 3D datasets in under 0.1 seconds per instance, enabling rapid training.
- Versatile Applications: From text-to-3D generation to controllable asset creation, DiffSplat outperforms existing methods in quality and efficiency.
Creating 3D objects from text or a single image has long been a holy grail for industries like gaming, virtual reality, and digital art. Yet, traditional methods face two critical hurdles: limited high-quality 3D training data and inconsistencies in multi-view synthesis. While recent advances in diffusion models have improved 2D image generation, translating these gains to 3D has proven elusive. Enter DiffSplat, a groundbreaking framework that reimagines how 3D content is generated—by tapping into the vast knowledge of pretrained image diffusion models.
Merging 2D Priors with 3D Coherence
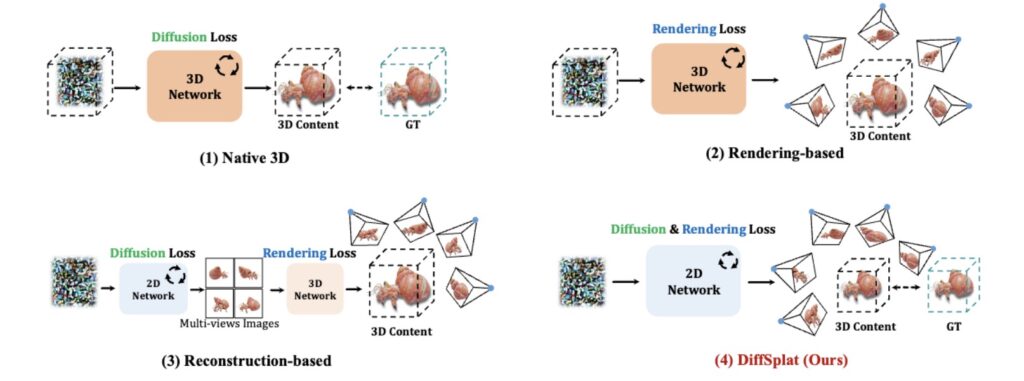
At its core, DiffSplat leverages 3D Gaussian Splatting (3DGS), a rendering technique known for balancing visual quality and computational efficiency. But instead of training from scratch on scarce 3D datasets, DiffSplat cleverly repurposes image diffusion models like Stable Diffusion and SDXL. Here’s how:
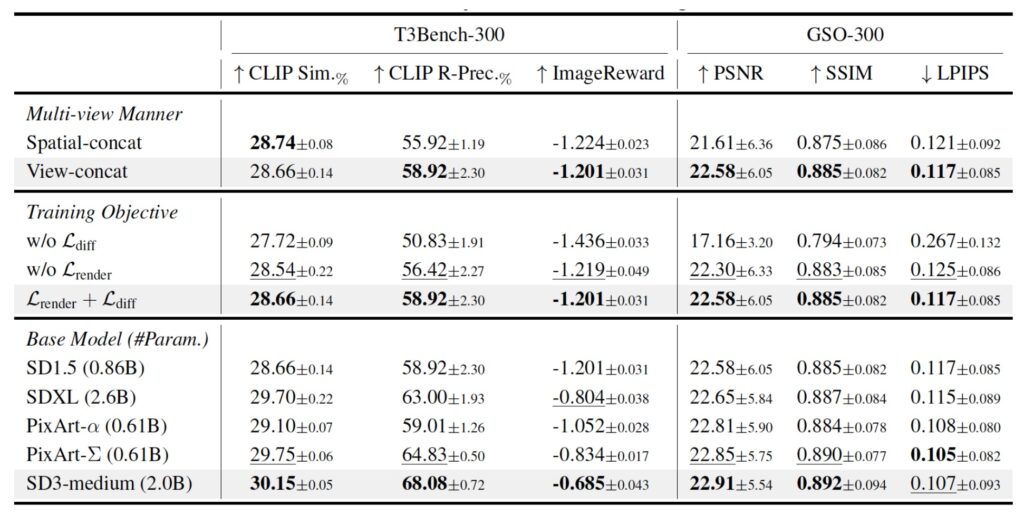
- Structured Splat Reconstruction:
A lightweight transformer-based model instantly converts multi-view 2D images into 3D Gaussian splat grids—parameterized by color, location, scale, rotation, and opacity. This process takes just 0.1 seconds per object, enabling scalable dataset creation. By incorporating geometric cues like coordinate and normal maps, the system achieves sharper reconstructions than previous methods. - Splat Latents:
To bridge 2D and 3D domains, DiffSplat fine-tunes the variational autoencoders (VAEs) of image diffusion models to compress splat grids into a shared latent space. These “splat latents” are treated as a unique visual style, allowing pretrained diffusion models to generate 3D properties directly. A novel rendering loss ensures geometric coherence across arbitrary viewpoints, addressing the “multi-view inconsistency” plaguing earlier approaches. - Training with Dual Objectives:
DiffSplat combines a standard diffusion loss (denoising splat latents) with a 3D-aware rendering loss. This dual objective ensures the model learns both the structure of Gaussian splats and their spatial relationships, resulting in outputs that are both visually rich and geometrically plausible.

Why DiffSplat Outperforms the Competition
Experiments across text- and image-conditioned tasks reveal DiffSplat’s superiority:
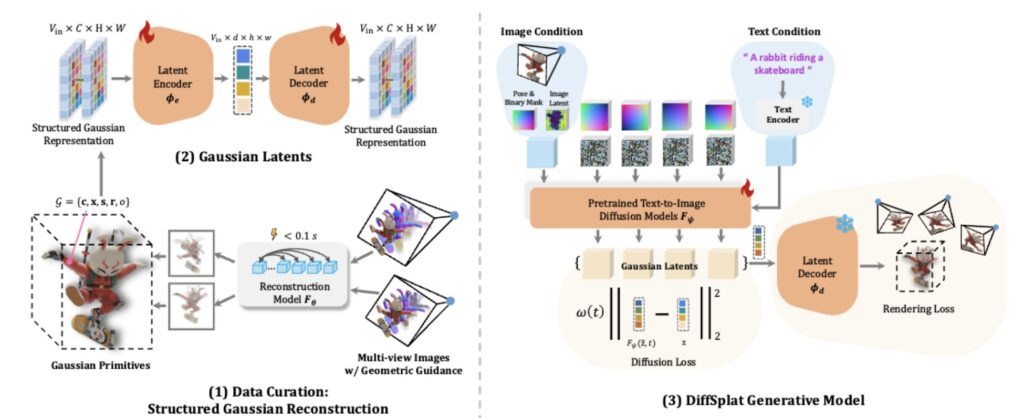
- Text-to-3D: On the T3Bench benchmark, DiffSplat achieves a 30.95% CLIP similarity score for single-object generation, outperforming native 3D models like GVGEN and reconstruction-based methods like LGM. Complex prompts (e.g., “a dog made of salad”) are rendered with striking detail, thanks to the model’s ability to leverage 2D diffusion priors.
- Image-to-3D: When reconstructing 3D objects from single images, DiffSplat achieves a PSNR of 22.91 on the GSO dataset—nearly 3 points higher than triplane-based NeRF models. Its outputs exhibit fewer artifacts and better texture fidelity.
- Controllable Generation: By integrating tools like ControlNet, DiffSplat enables conditional 3D creation using depth maps, edge detection, or normal maps. For example, inputting a Canny edge sketch of a teacup alongside the text “porcelain with gold trim” yields a photorealistic 3D model.
Efficiency and Adaptability
DiffSplat’s architecture minimizes computational overhead. Training takes just 3 days on 8 A100 GPUs—a fraction of the time required by competitors like DMV3D (7 days on 128 GPUs). Key innovations include:
- View-Concat vs. Spatial-Concat: Multi-view splat latents are processed either as video-like sequences (view-concat) or tiled grids (spatial-concat). The former excels in image-conditioned tasks due to dense attention between input and output latents.
- Compatibility with Base Models: DiffSplat works seamlessly with popular diffusion frameworks like SD1.5, SDXL, and SD3. Larger models like PixArt-Σ further boost performance, achieving a 31.08 PSNR in auto-encoding tasks.
While DiffSplat marks a leap forward, challenges remain. Converting Gaussian splats to high-quality meshes is still unsolved, and physical material properties (e.g., reflectivity) are not yet modeled. Future work could integrate real-world video datasets to enhance scalability or adopt personalization techniques from the image domain.
A New Era for 3D Content Creation
DiffSplat redefines what’s possible in 3D generation by marrying the scalability of 2D diffusion models with the precision of Gaussian splatting. Its ability to generate complex, consistent 3D assets in seconds—not hours—opens doors for creators across industries. As the AI community continues to innovate, frameworks like DiffSplat will play a pivotal role in democratizing high-quality 3D content, one splat at a time.