How Diffusion Transformers are bridging the gap between static images and dynamic video reality
- The Video Gap: While image face swapping has matured, video face swapping remains difficult due to the need for temporal stability, pose consistency, and attribute preservation.
- The DreamID-V Solution: This is the first framework to utilize a Diffusion Transformer (DiT) architecture, supported by a novel data pipeline (SyncID-Pipe) and specific training strategies to ensure high realism.
- Benchmarking Success: To prove its versatility, the authors introduced IDBench-V, a comprehensive benchmark where DreamID-V outperformed state-of-the-art methods in visual realism and identity consistency.
Face swapping technology has rapidly evolved from a niche curiosity to a powerful tool with significant potential in film production, creative design, and privacy protection. The goal is straightforward: generate media that combines the identity of a source face with the attributes—such as background, pose, expression, and lighting—of a target. While Image Face Swapping (IFS) has achieved remarkable success, translating this fidelity to video remains a formidable hurdle.

Video Face Swapping (VFS) is infinitely more complex than its static counterpart. It is not enough to simply swap a face frame by frame; the system must maintain temporal identity continuity. If the face flickers, or if the lighting shifts unnaturally between frames, the illusion breaks. Existing methods have struggled to balance “identity similarity” (looking like the person) with “attribute preservation” (keeping the original video’s vibe) while ensuring the result is temporally smooth.
Introducing DreamID-V and SyncID-Pipe
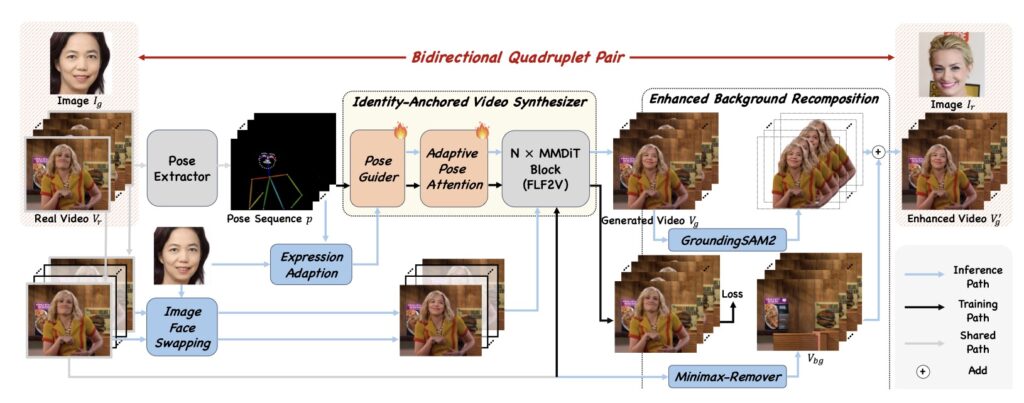
To address these limitations, researchers have proposed DreamID-V, a comprehensive framework designed to seamlessly transfer the superiority of image swapping models into the video domain. This is the first framework for VFS based on the Diffusion Transformer (DiT), a cutting-edge architecture known for generating high-quality media.

The foundation of this system is a novel data pipeline called SyncID-Pipe. One of the biggest issues in training these models is the lack of perfect “paired” data. SyncID-Pipe solves this by pre-training an Identity-Anchored Video Synthesizer. By combining this with existing IFS models, the system constructs bidirectional ID quadruplets. This complex arrangement provides explicit supervision, giving the model the exact data it needs to understand how a face should look and move in different contexts.
Architectural Innovations and Training Strategy
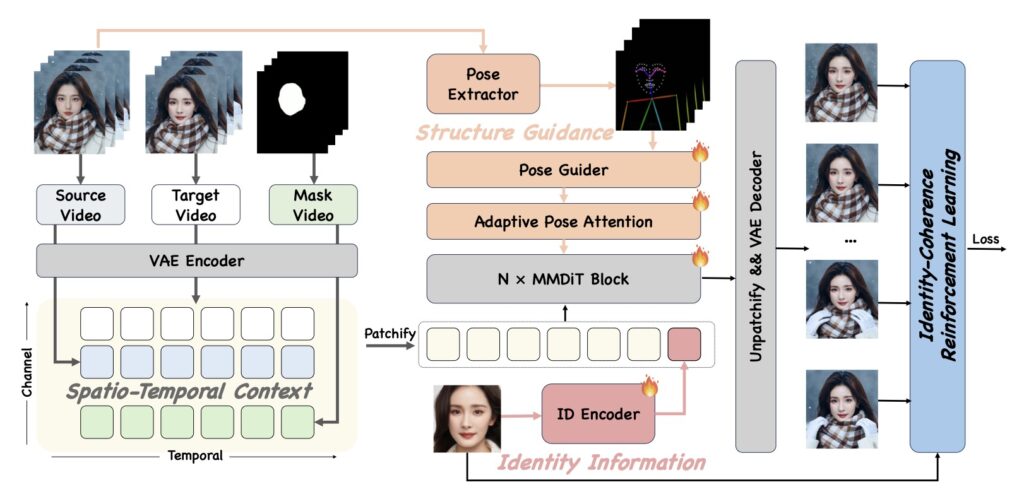
DreamID-V is not just about better data; it introduces a sophisticated architecture to handle the swap. The model employs a core Modality-Aware Conditioning module. This allows the system to discriminatively inject multi-modal conditions—essentially effectively managing the different inputs (source identity vs. target video attributes) to ensure neither is lost in the process.
To further enhance visual realism, the researchers implemented two advanced training strategies:
- Synthetic-to-Real Curriculum: The model learns in stages, starting with synthetic data and progressively tackling the complexities of real-world video.
- Identity-Coherence Reinforcement Learning: This strategy “rewards” the model for keeping the identity consistent over time, explicitly tackling the issue of jitter and identity drift in challenging scenarios.
Setting a New Standard with IDBench-V
A major bottleneck in advancing VFS technology has been the issue of limited benchmarks to test against. To prove the efficacy of their new model, the researchers introduced IDBench-V. This is a comprehensive benchmark encompassing diverse scenes, lighting conditions, and angles.
Extensive experiments on IDBench-V demonstrate that DreamID-V outperforms state-of-the-art methods. It exhibits exceptional versatility and can be seamlessly adapted to various swap-related tasks. By solving the issues of temporal inconsistency and attribute loss, DreamID-V represents a systematic solution for high-fidelity video face swapping, narrowing the gap between artificial generation and reality.