ByteDance’s Cutting-Edge VLA Model Promises Smarter, More Adaptable Machines for Real-World Tasks
- Breakthrough in Generalization: GR-3 excels at handling novel objects, environments, and abstract instructions, making it a game-changer for robots that need to adapt quickly without extensive retraining.
- Efficient Training and Robust Performance: By combining web-scale data with minimal human input and advanced imitation learning, GR-3 masters long-horizon, dexterous tasks like bi-manual manipulation and mobile navigation, outperforming existing baselines.
- Future-Proofing Robotics: Paired with the versatile ByteMini robot, GR-3 represents a step toward intelligent machines that assist humans in daily life, with plans to scale up and integrate reinforcement learning to overcome current limitations.

In the ever-evolving world of robotics, the dream of creating machines that can seamlessly assist humans in everyday tasks has long captivated researchers and innovators. From folding laundry to navigating cluttered kitchens, these generalist robots must tackle the chaos of the real world—diverse environments, unexpected objects, and complex instructions. Enter GR-3, ByteDance Seed’s latest advancement in vision-language-action (VLA) models, which is pushing the boundaries of what’s possible. Building on decades of robotics research, GR-3 addresses key challenges like generalization, efficiency, and reliability, offering a glimpse into a future where robots become reliable household companions.

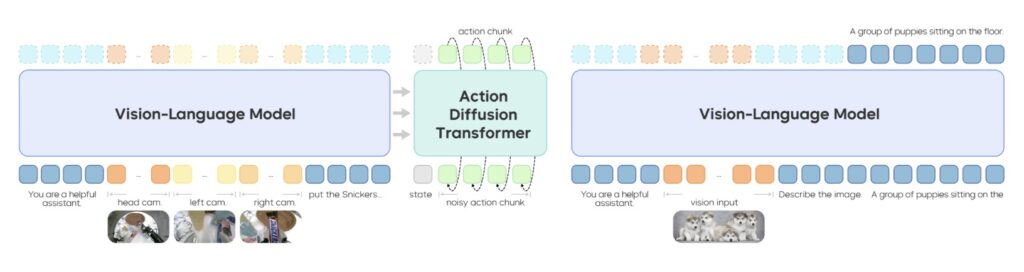
At its core, GR-3 is a large-scale VLA model that integrates visual perception, language understanding, and action prediction. This allows it to interpret natural language instructions and execute tasks with remarkable precision. What sets GR-3 apart is its exceptional ability to generalize to entirely new scenarios. Imagine a robot encountering an unfamiliar gadget in a never-before-seen room—GR-3 can adapt on the fly, handling abstract concepts that require reasoning, such as “organize the tools by size and function.” This isn’t just theoretical; extensive real-world experiments demonstrate GR-3 surpassing the state-of-the-art baseline method, known as π0, across a variety of challenging tasks. By drawing from foundational work in robotics, GR-3 builds on advances in VLA models and pre-trained vision-language models (VLMs), creating a system that’s not only smart but also versatile.

One of the most exciting aspects of GR-3 is its training recipe, which makes adaptation both rapid and cost-effective. The model is co-trained with massive web-scale vision-language data, providing a broad knowledge base that mimics human-like understanding. For fine-tuning, it leverages minimal human trajectory data collected via VR devices—think of a person demonstrating a task in virtual reality, which the model then imitates efficiently. This is complemented by effective imitation learning from robot-generated trajectories, ensuring the policy is robust even in complex situations. As a result, GR-3 shines in long-horizon tasks that demand dexterity, such as bi-manual manipulation (using two arms simultaneously) or mobile movement across spaces. These capabilities are crucial for daily assistance, where errors can compound over extended sequences, like preparing a meal from start to finish.
To bring GR-3 to life, ByteDance introduces ByteMini, a bi-manual mobile robot designed for flexibility and reliability. This hardware marvel integrates seamlessly with GR-3, enabling it to tackle a wide array of tasks—from manipulating deformable objects like cloth to navigating dynamic environments. Real-world tests highlight ByteMini’s prowess when powered by GR-3, showing robust performance in scenarios that stump traditional robots. This combination underscores a broader shift in robotics: moving beyond rigid, task-specific machines to adaptable generalists that can learn from sparse data and reason through novel challenges.
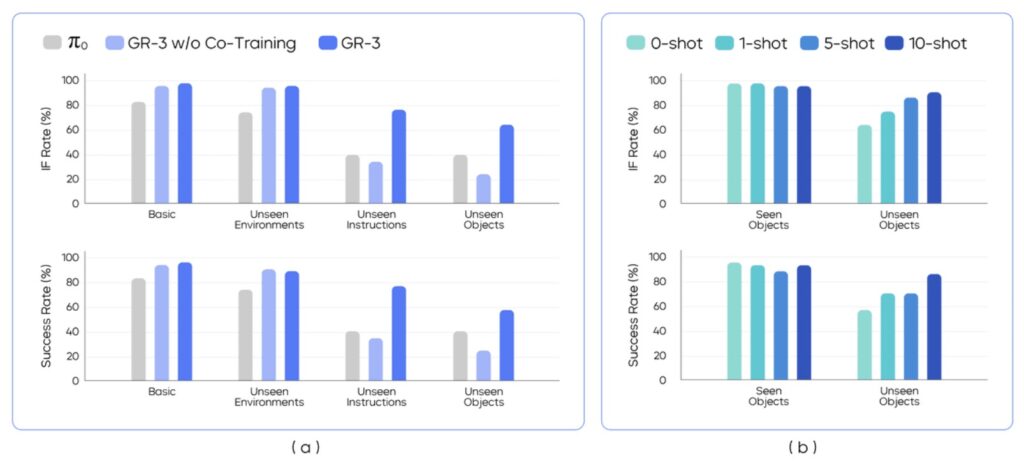
Despite its strengths, GR-3 isn’t without hurdles, reflecting the ongoing complexities in robotics. It occasionally falters with unseen instructions involving novel concepts or objects, and grasping items with unfamiliar shapes can be tricky. These limitations stem from the inherent challenges of imitation learning, where the model might get stuck in unexpected states without a way to recover. Looking ahead, the team plans to scale up the model and training data to boost performance in novel scenarios. More ambitiously, incorporating reinforcement learning (RL) could enhance robustness, allowing GR-3 to optimize beyond mere imitation and self-correct during dexterous tasks. These future directions align with the field’s long-standing goals, addressing issues like out-of-distribution instructions and the need for large demonstration datasets.
Ultimately, GR-3 stands as a pivotal step toward intelligent robots that enhance human life. By mastering complex instructions, generalizing effectively, learning from minimal data, and executing long-horizon tasks with reliability, it paves the way for practical applications in homes, workplaces, and beyond. As robotics research continues to evolve, innovations like GR-3 and ByteMini bring us closer to a world where machines aren’t just tools but intuitive partners, ready to assist with the diverse demands of daily living. With ongoing improvements, the era of truly generalist robots may be just around the corner.