Revolutionizing Video Diffusion with Efficiency and Speed
- Sliding Tile Attention (STA) drastically reduces the computational cost of video generation in Diffusion Transformers (DiTs) by focusing on localized 3D windows instead of full attention.
- STA accelerates attention computation by up to 17× compared to state-of-the-art methods, cutting end-to-end latency from 945 seconds to as low as 268 seconds with minimal quality loss.
- This breakthrough enables faster, hardware-efficient video generation without retraining, paving the way for practical deployment of high-resolution video diffusion models.
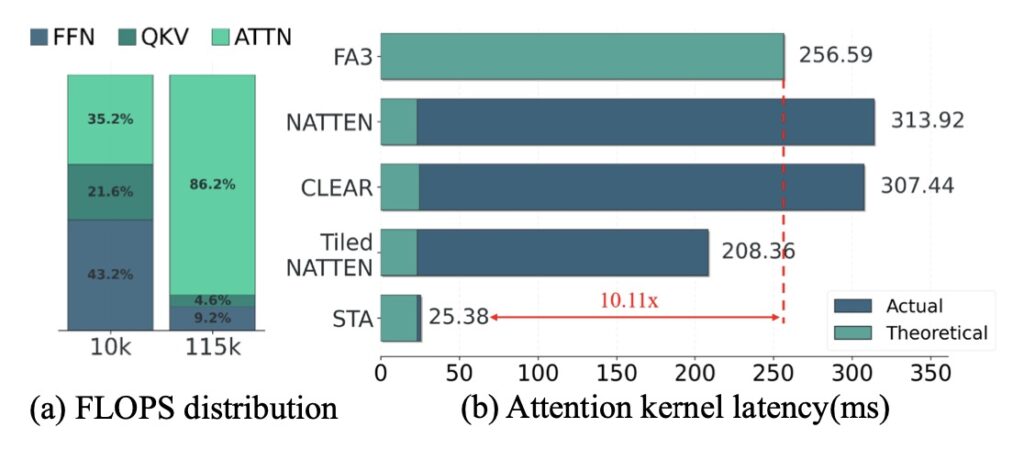
Diffusion Transformers (DiTs) have emerged as the gold standard for generating high-resolution, long-duration videos. These models, such as HunyuanVideo, leverage 3D attention mechanisms to capture spatial and temporal dependencies across video frames, producing visually coherent and realistic outputs. However, this cutting-edge capability comes at a steep computational cost. The quadratic complexity of full attention in 3D space makes both training and inference prohibitively slow, especially as video resolutions and durations increase.
For instance, generating a mere 5-second 720p video using HunyuanVideo on a high-end GPU like the NVIDIA H100 takes 16 minutes, with attention computation alone consuming 800 out of 945 seconds of total inference time. This bottleneck severely limits the practical deployment of DiTs, making them unsuitable for real-time or large-scale applications.
Enter Sliding Tile Attention
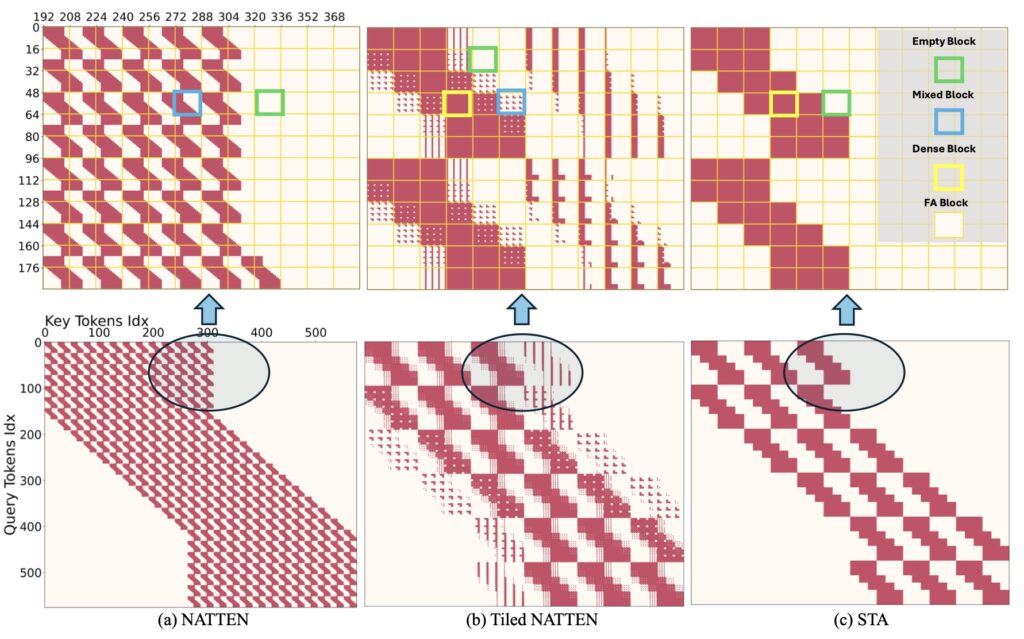
To address this challenge, researchers have introduced Sliding Tile Attention (STA), a novel approach that reimagines how attention is computed in video diffusion models. STA is built on the observation that attention scores in pretrained video diffusion models are predominantly concentrated within localized 3D regions. Instead of computing full attention across the entire video sequence, STA focuses on smaller, localized spatial-temporal windows, sliding across the video in a tile-by-tile manner.
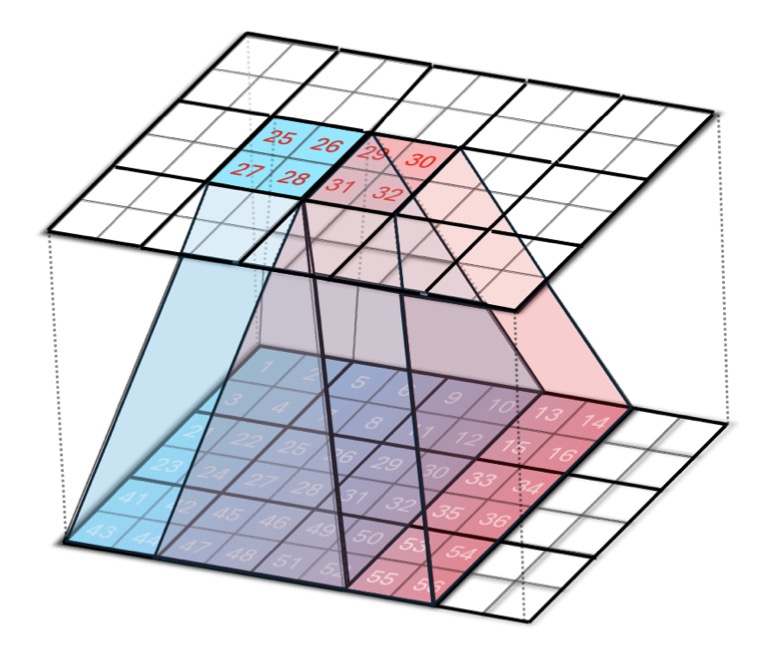
This approach eliminates the redundancy inherent in full attention while preserving the expressiveness of the model. Unlike traditional token-wise sliding window attention (SWA), STA operates at the tile level, making it more hardware-efficient. By leveraging a hardware-aware sliding window design and kernel-level optimizations, STA achieves the first efficient 2D/3D sliding-window-like attention implementation.

Performance Breakthroughs
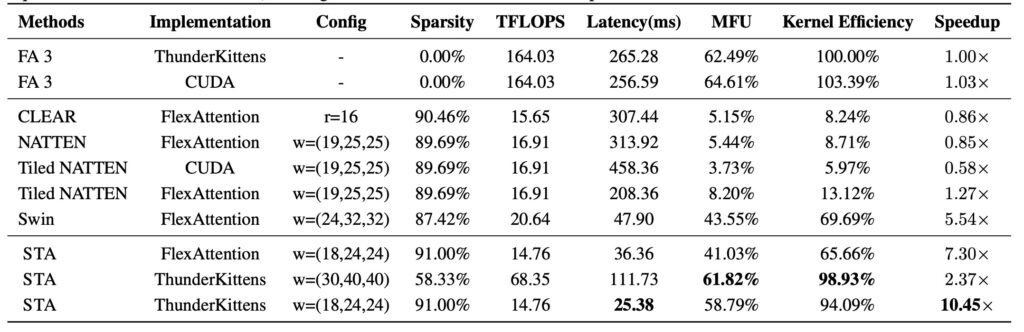
The results of STA are nothing short of groundbreaking. It accelerates attention computation by 2.8–17× compared to FlashAttention-2 (FA2) and 1.6–10× compared to FlashAttention-3 (FA3), two of the most advanced attention mechanisms available. On the HunyuanVideo model, STA reduces end-to-end latency from 945 seconds (using FA3) to 685 seconds without any quality degradation.
For those willing to fine-tune their models, STA offers even greater efficiency. With minimal retraining, STA can lower latency to just 268 seconds, with only a 0.09% drop in performance on the VBench benchmark. This makes STA not only a powerful tool for accelerating inference but also a practical solution for real-world applications where speed and quality are both critical.

Why STA Matters
The introduction of STA represents a significant leap forward in the field of video generation. By addressing the computational bottlenecks of 3D attention, STA makes high-resolution video diffusion models more accessible and scalable. This has far-reaching implications for industries ranging from entertainment and gaming to virtual reality and content creation.
Moreover, STA is conceptually orthogonal to other acceleration techniques, such as caching and consistency distillation. This means it can be combined with these methods for even greater efficiency gains in the future.

The Road Ahead
While STA has already demonstrated its potential to revolutionize video generation, there is still room for further exploration. Future research could focus on integrating STA with other optimization techniques, as well as extending its applicability to other domains beyond video generation.
In conclusion, Sliding Tile Attention is a game-changing innovation that addresses one of the most pressing challenges in video diffusion models. By combining efficiency, scalability, and quality, STA paves the way for a new era of fast, high-resolution video generation.
