Transforming Text into Harmonies: How FluxMusic Revolutionizes Music Generation with AI
Dive into the future of music creation with FluxMusic, an advanced AI model that turns text into melodic masterpieces. Here’s a quick overview of this groundbreaking technology:
- Revolutionary Approach: FluxMusic builds on the Flux1 model to transform text into music using rectified flow transformers within a latent VAE space, offering a sophisticated approach to audio generation that outperforms traditional diffusion methods.
- Advanced Architecture: By integrating multiple pre-trained text encoders and a unique modulation mechanism, FluxMusic captures intricate textual details and time-step embeddings to generate high-quality mel-spectra, leading to more accurate and flexible music predictions.
- Promising Results: The model’s performance has been validated through various automatic metrics and human preference evaluations, showing significant improvements over existing methods. Future research will focus on scalability and efficiency enhancements to further advance the technology.
In the realm of artificial intelligence, where creativity meets technology, FluxMusic is setting a new standard for text-to-music generation. This innovative model extends the capabilities of the diffusion-based rectified flow Transformers, bringing a fresh perspective to the creation of music from textual descriptions.
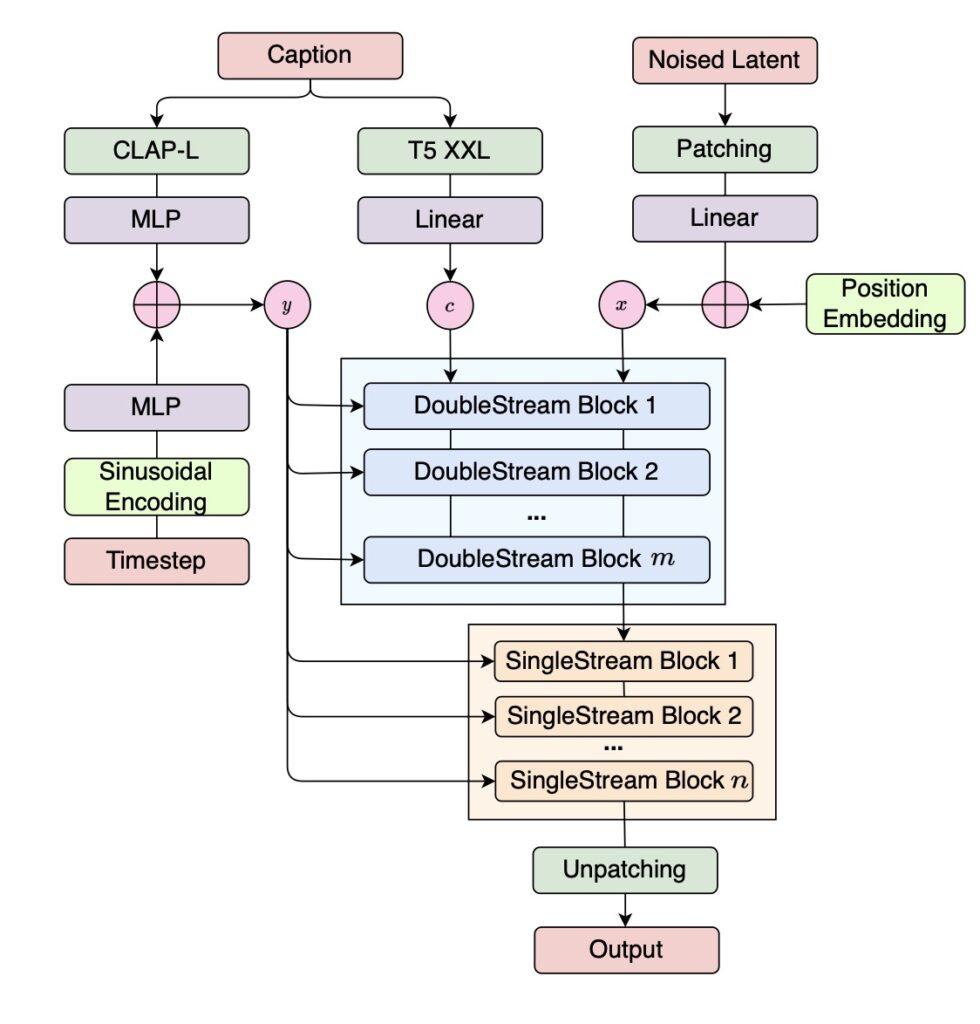
FluxMusic, an evolution of the advanced Flux1 model, introduces a novel approach by leveraging rectified flow transformers to predict mel-spectra in a latent VAE space. This process begins with applying a sequence of independent attention mechanisms to a dual text-music stream, followed by a focused music stream for refined denoised patch prediction. By incorporating multiple pre-trained text encoders, FluxMusic effectively captures both broad caption semantics and detailed textual nuances, ensuring a high degree of flexibility and accuracy in music generation.

The model’s unique architecture integrates coarse textual information with time-step embeddings through a modulation mechanism, while fine-grained textual details are combined with music patch sequences as inputs. This sophisticated approach not only enhances the quality of generated music but also ensures that the output aligns closely with the provided text.
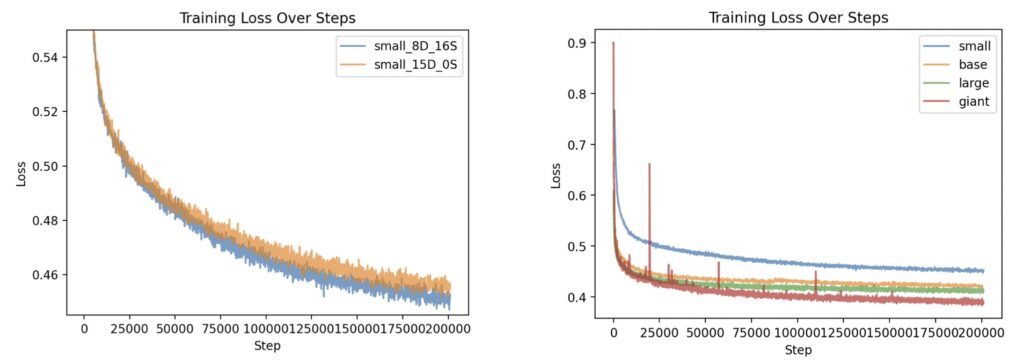
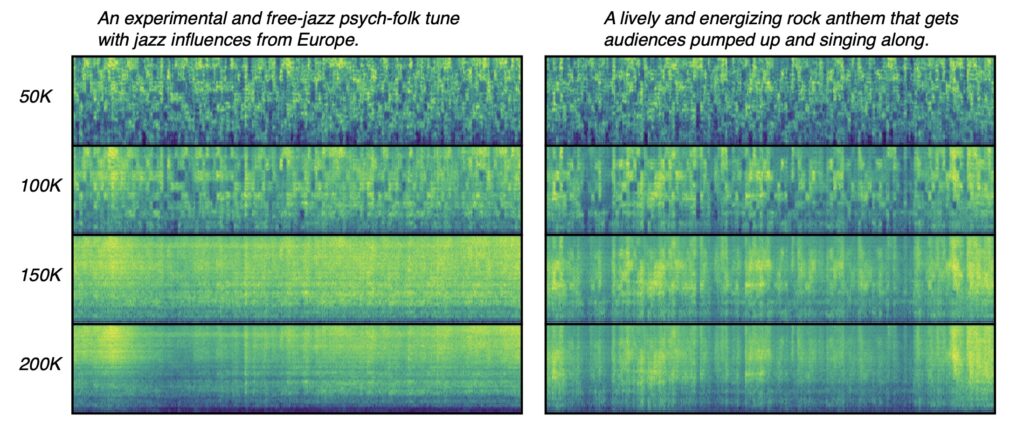
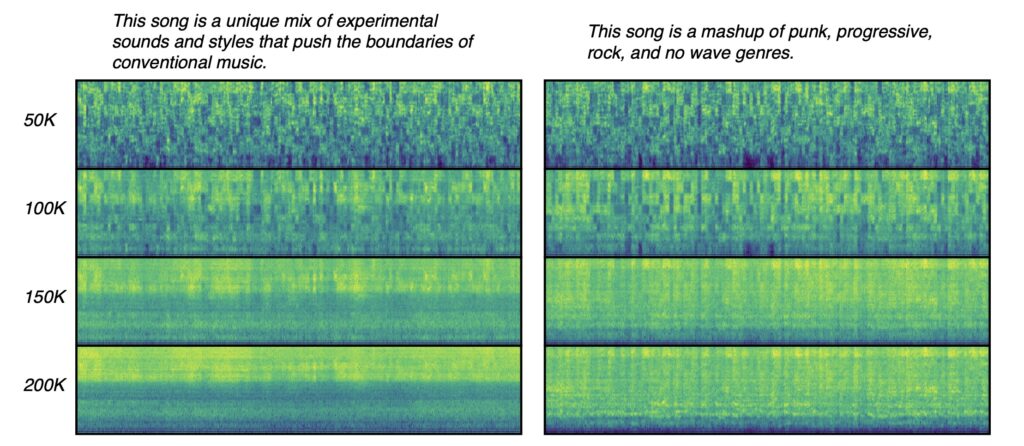
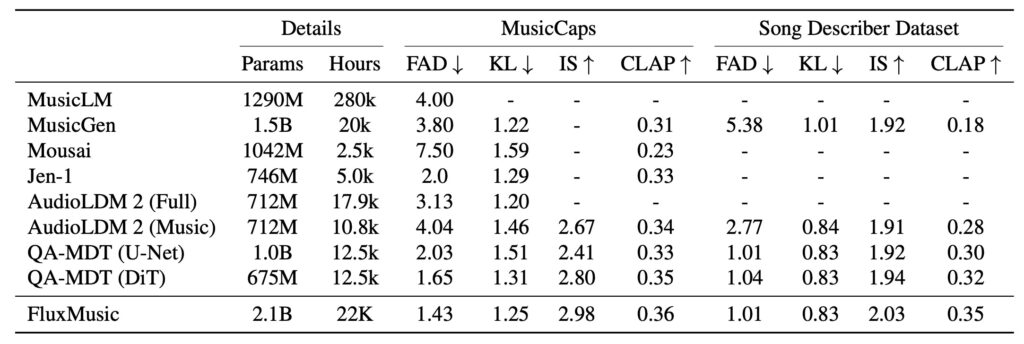
Results from extensive testing reveal that FluxMusic significantly surpasses established diffusion methods in performance, as evidenced by both automatic metrics and human evaluations. The research also highlights key insights, such as the effectiveness of the rectified flow transformer for audio spectrograms and the identification of optimal learning strategies through ablation studies.
Looking ahead, future research will explore the scalability of FluxMusic by incorporating mixture-of-experts architectures and distillation techniques, aiming to boost inference efficiency and broaden the model’s applicability.
FluxMusic represents a major leap forward in the field of AI-driven music generation. By marrying advanced technology with creative processes, it opens new avenues for translating text into harmonious and engaging musical compositions.