This groundbreaking dataset and framework achieve robust garment modeling from in-the-wild images, addressing challenges of complex poses and deformations.
- Advanced Dataset: GarVerseLOD introduces a large-scale dataset with 6,000 meticulously detailed 3D garment models to improve AI’s handling of complex clothing styles and poses.
- Hierarchical Framework: Using levels of detail (LOD) allows the model to capture garment shapes and intricate deformations with unprecedented accuracy from just one image.
- Robust Applications: The method’s versatility supports applications in visual effects, VR, and professional design by creating standalone, high-fidelity garment models.

In an impressive leap forward for 3D garment reconstruction, GarVerseLOD offers a dataset and framework that enables high-fidelity modeling of garments from a single, unconstrained image. Traditional AI models often struggle with complex cloth deformations and unusual body poses, but GarVerseLOD tackles these challenges by using a multi-layered approach that captures various levels of garment detail. With this breakthrough, GarVerseLOD provides a flexible solution for digital designers, game developers, and AR/VR professionals needing realistic, standalone garment models.
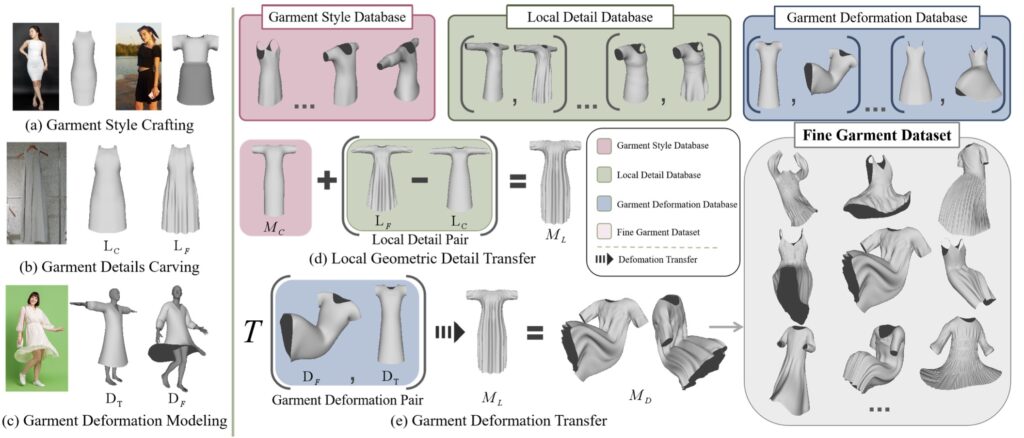
Breaking Down the GarVerseLOD Approach
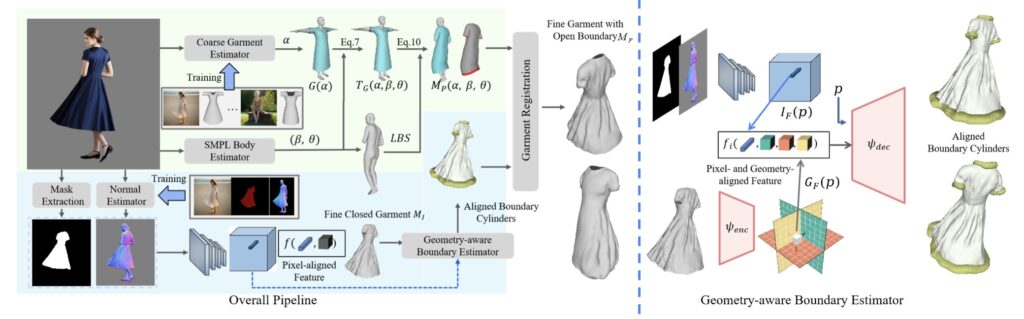
The key to GarVerseLOD’s innovation lies in its hierarchical dataset structure, which organizes garment details across multiple levels. This approach, known as levels of detail (LOD), allows the model to move from basic garment outlines to intricate, pixel-aligned features. GarVerseLOD’s vast dataset includes 6,000 high-quality 3D models created by professional artists, giving the AI a rich base for learning fine-grained geometry and complex cloth dynamics. This modularity lets the model handle a wide range of garment styles and deformations, making it a versatile tool for any application requiring garment reconstruction.
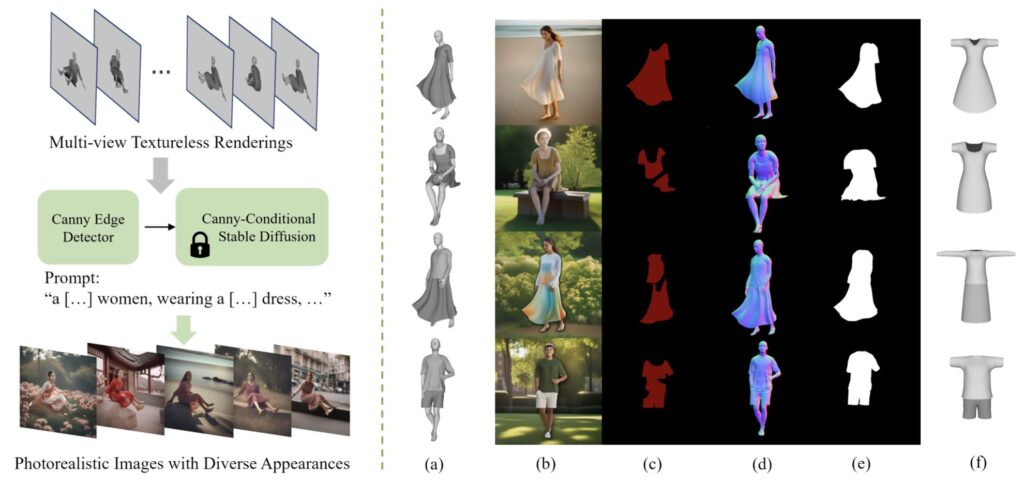
Addressing Challenges in Garment Reconstruction
One of the biggest obstacles in 3D garment modeling has been the scarcity of high-quality data, limiting AI’s ability to generalize across various clothing types and human poses. GarVerseLOD overcomes this by pairing each garment with detailed, photorealistic images generated by a conditional diffusion model. This allows the model to recognize and reconstruct garments even when posed in challenging positions or partially obscured by other objects, a feat that surpasses the capabilities of current state-of-the-art methods.
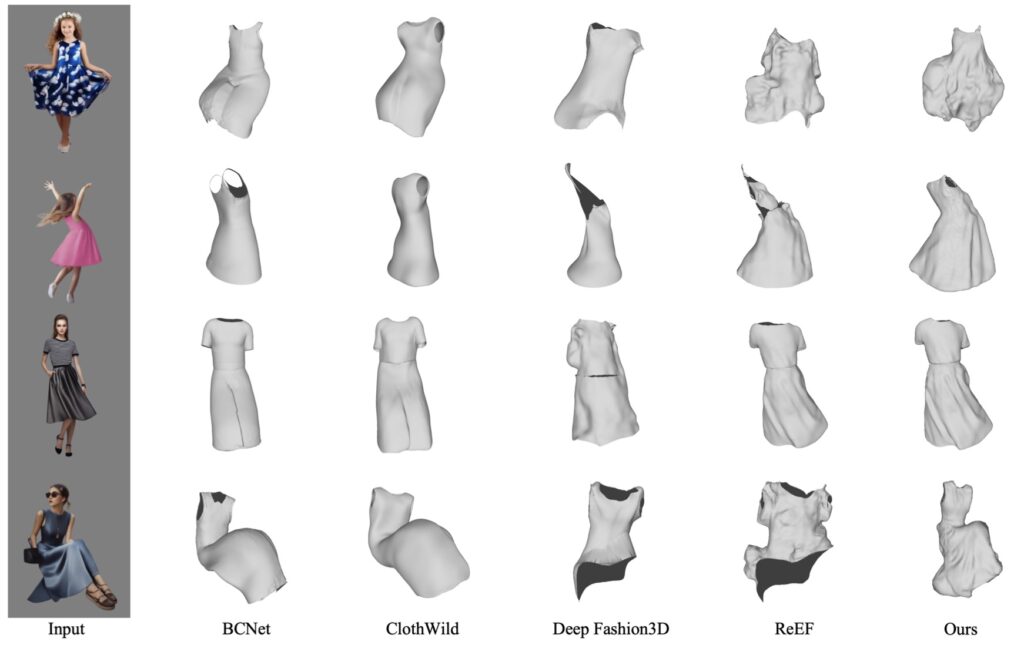
Experimental Results Show Superior Performance
In rigorous tests on real-world, in-the-wild images, GarVerseLOD’s framework outperformed existing models like DeepFashion3D and BCNet. Quantitative metrics such as Chamfer Distance, Normal Consistency, and IoU confirm that GarVerseLOD captures finer details and produces more accurate garment boundaries. Qualitative comparisons also reveal its strength in handling intricate garment features, from wrinkles to layered cloth structures. The GarVerseLOD approach not only improves garment fidelity but also enhances generalization, making it reliable for diverse applications.

Potential and Limitations
While GarVerseLOD sets a new standard in 3D garment reconstruction, some limitations remain. Its single-layer model struggles with complex, multi-layered clothing like skirts with slits or dresses with layered designs. Expanding the dataset with more diverse garment styles could help address these challenges. Future updates may also explore advanced data representations to support multi-layered structures, further extending GarVerseLOD’s capabilities.
GarVerseLOD represents a significant step forward in AI-driven garment reconstruction, providing a powerful dataset and framework that combine high fidelity with flexibility. By capturing various garment details in a scalable, hierarchical manner, GarVerseLOD opens new doors for applications in gaming, virtual fashion, and digital design. As this model evolves, it promises to become an essential tool for creators and professionals across industries, bringing realistic 3D garment reconstruction within reach from just a single image.

