High-Performance Coding and Reasoning for Local Hardware
- Elite Efficiency: Utilizing a Mixture-of-Experts (MoE) architecture, GLM-4.7-Flash delivers 30B-class intelligence while activating only ~3.6B parameters per token, ensuring speed without compromise.
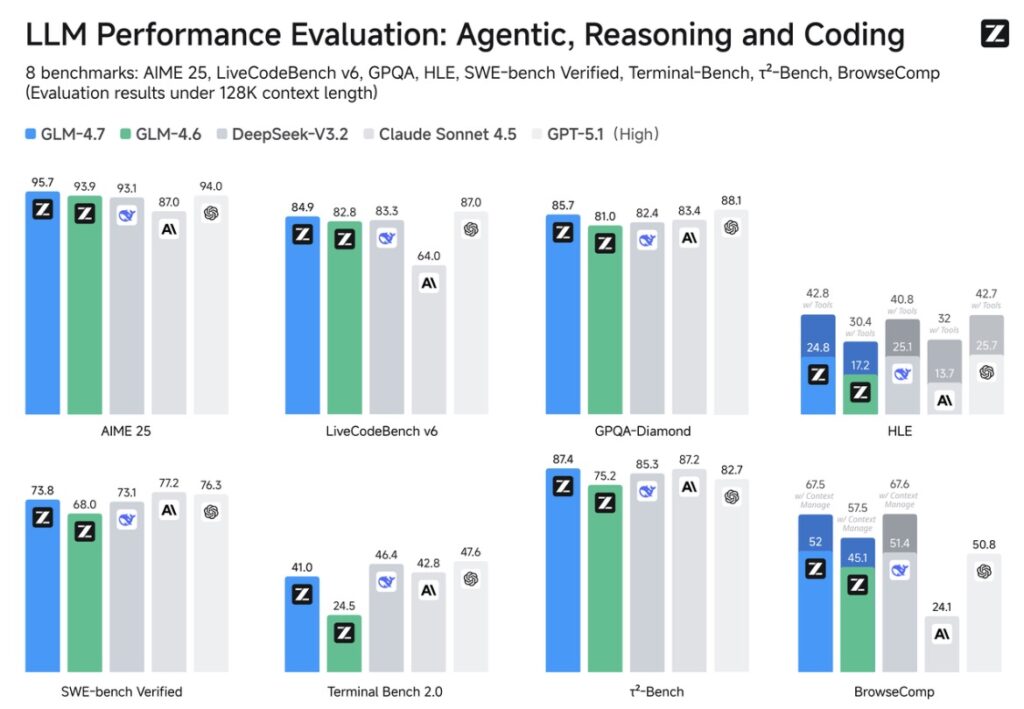
- Top-Tier Reasoning: With a massive 200K context window, it leads the SWE-Bench and GPQA leaderboards, excelling in coding, agentic workflows, and creative roleplay.
- Run It Locally: Optimized for consumer hardware, it runs comfortably on 24GB VRAM (or just 18GB at 4-bit precision) and supports fine-tuning via Unsloth.
Z.ai has redefined what is possible on local devices with the release of GLM-4.7-Flash. Designed to bridge the gap between massive server-side models and lightweight local deployment, this model sets a new benchmark for the 30B parameter class. Its secret lies in a highly efficient Mixture-of-Experts (MoE) architecture. While it retains the knowledge base of a large model, it selectively activates only about 3.6 billion parameters during generation. This allows it to offer the rapid inference speeds of a small model while delivering the complex reasoning capabilities usually reserved for flagship giants.
Coding, Agents, and Creativity
GLM-4.7-Flash is not just fast; it is incredibly capable. It currently stands as the best-performing 30B model on SWE-Bench and GPQA, making it the premier choice for developers needing a local coding assistant or an autonomous agent backend.
The model boasts a substantial 200K context window, allowing it to digest vast amounts of information—from entire codebases to long literary works—without losing track of the details. This makes it an exceptional tool for long-context creative writing, translation, and immersive roleplay, providing a versatility that goes beyond simple chat interactions.
How to Run and Fine-Tune
Bringing this power to your desktop is surprisingly accessible. GLM-4.7-Flash is engineered to sit in the “sweet spot” of high-end consumer hardware:
- Hardware Requirements: The model runs natively on 24GB VRAM GPUs (like the RTX 3090/4090) or unified memory systems.
- Optimization: For best performance, we recommend using 4-bit precision, which brings the memory requirement down to approximately 18GB.
- Fine-Tuning: Thanks to support from Unsloth, you can not only run the model but also fine-tune it locally, allowing you to customize it for specific datasets or languages.
Whether you are building complex software agents or need a creative partner that runs offline, GLM-4.7-Flash delivers enterprise-grade performance right on your device.