A New Benchmark to Challenge Vision-Language Models with Counterfactual Reasoning
- HalluSegBench introduces a pioneering benchmark to evaluate hallucinations in vision-language segmentation models, using a novel dataset of 1340 counterfactual instance pairs across 281 unique object classes.
- The benchmark reveals that vision-driven hallucinations are far more common than label-driven ones, with models often failing to adapt to subtle visual edits, exposing critical gaps in grounding fidelity.
- Through new metrics and experiments, HalluSegBench highlights the vulnerability of even advanced models to counterfactual visual manipulations, paving the way for more robust segmentation approaches.

Vision-Language Models (VLMs) have taken the world of multimodal AI by storm, blending visual and textual data to achieve groundbreaking results in tasks like visual question answering, image captioning, and object detection. Their ability to align linguistic cues with pixel-level visual details has opened up exciting possibilities, especially in reasoning-based segmentation and spatial understanding. Imagine a model that can segment an object in an image not just by its appearance, but by understanding the context described in a natural language query. This fine-grained integration is a game-changer, pushing the boundaries of how machines interpret complex visual scenes. Yet, beneath this impressive progress lies a troubling flaw: hallucinations. These models often “see” things that aren’t there, producing segmentation masks for nonexistent objects or mislabeling irrelevant regions, which can lead to critical failures in real-world applications.
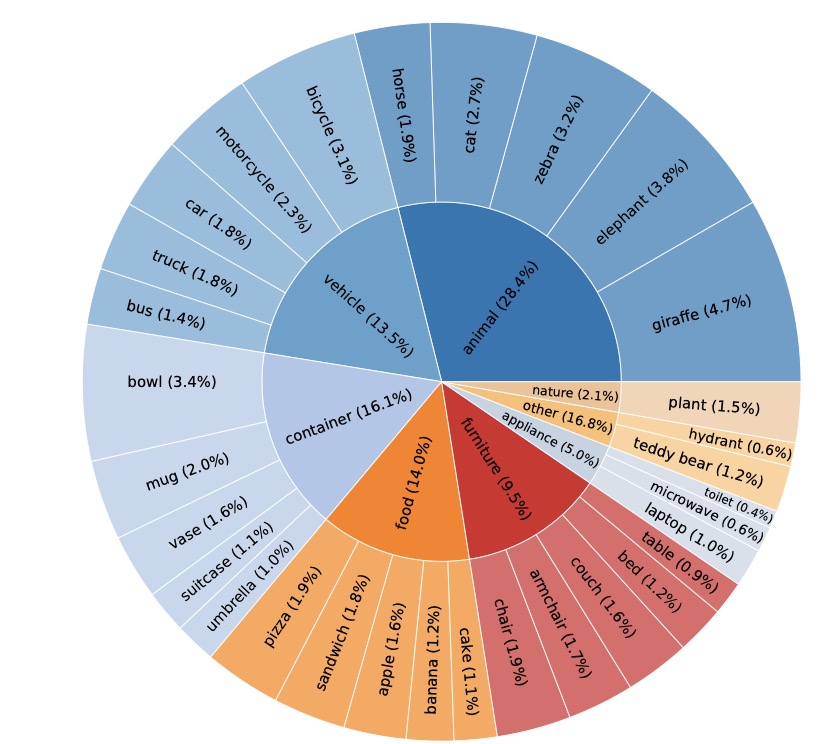
Enter HalluSegBench, a groundbreaking benchmark designed to tackle this issue head-on by evaluating hallucinations in visual grounding through the lens of counterfactual visual reasoning. Unlike existing evaluation protocols that focus narrowly on label or textual hallucinations without altering the visual context, HalluSegBench takes a bolder approach. It constructs a unique dataset of 1340 counterfactual instance pairs spanning 281 distinct object classes. These pairs involve carefully crafted image edits where specific objects are replaced with visually similar alternatives while keeping the rest of the scene intact. This setup allows for controlled testing of whether models are truly grounding their predictions in visual evidence or simply hallucinating based on prior biases or incomplete reasoning. The result? A stark revelation that vision-driven hallucinations are significantly more prevalent than those triggered by labels alone.
What makes HalluSegBench stand out is its emphasis on counterfactual reasoning—a method that challenges models to adapt to subtle visual changes and tests their fidelity to the actual content of an image. The benchmark introduces a set of innovative metrics to quantify both performance degradation and spatial hallucination under these object-level visual edits. Through rigorous experiments with state-of-the-art vision-language segmentation models, the findings are eye-opening. Many models persist in false segmentation even when the visual context shifts, stubbornly clinging to incorrect predictions. This suggests a deeper issue: current models, even those explicitly designed to minimize hallucinations, struggle to generalize when faced with visually grounded reasoning tasks. HalluSegBench exposes these weaknesses with precision, showing that prior mitigation strategies fall short when the visual context is manipulated in meaningful ways.
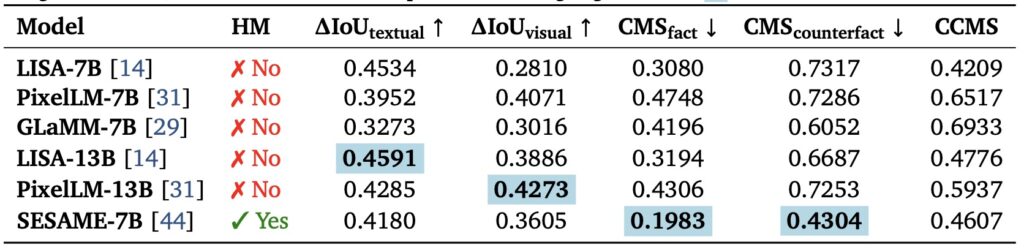
The implications of this benchmark are profound. By focusing on pixel-level hallucinations elicited through counterfactual edits, HalluSegBench offers a more effective way to diagnose and understand the limitations of today’s segmentation models. It’s not just about identifying errors; it’s about understanding why they happen. For instance, when an object’s identity is subtly altered in a scene, models often fail to adjust their segmentation masks accordingly, revealing a lack of true visual grounding. This isn’t a minor glitch—it’s a fundamental challenge that could undermine trust in VLMs for critical applications like autonomous driving or medical imaging, where precision is non-negotiable.
Looking at the broader landscape, the rise of VLMs has been fueled by large-scale multimodal datasets that enable remarkable performance across diverse tasks. From reasoning-based segmentation to spatial reasoning, these models are pushing the envelope of what’s possible. But with great power comes great responsibility, and the persistent issue of hallucinations reminds us that there’s still a long way to go. HalluSegBench isn’t just a diagnostic tool; it’s a call to action for the AI community to prioritize robustness in visual grounding. By laying bare the vulnerabilities of current models, it sets the stage for developing segmentation approaches that can withstand the complexities of real-world visual scenes.
Ultimately, HalluSegBench is more than a benchmark—it’s a stepping stone toward a future where vision-language models can be trusted to see the world as it truly is, not as they imagine it to be. The journey to eliminate hallucinations is far from over, but with tools like this, we’re one step closer to bridging the gap between human-like understanding and machine perception. As researchers and developers dive into this dataset and its metrics, the hope is to inspire innovations that don’t just perform well on paper but excel in the messy, unpredictable reality of visual interpretation. So, the next time a model segments an image, will it see what’s really there, or will it fall into the trap of its own illusions? HalluSegBench is here to help us find out.