Unlocking Spatio-Temporal Intelligence for Smarter Video Understanding
- Bridging the Evidence Gap: Open-o3 Video introduces explicit spatio-temporal grounding, highlighting timestamps, objects, and bounding boxes to make video reasoning transparent and verifiable, far surpassing text-only traces in traditional models.
- Overcoming Data and Training Hurdles: By curating high-quality datasets like STGR-CoT-30k and STGR-RL-36k, and employing a synergistic supervised fine-tuning (SFT) plus reinforcement learning (RL) strategy, the framework tackles the challenges of joint temporal and spatial localization in complex videos.
- Superior Performance and Future Potential: Achieving state-of-the-art results on benchmarks like V-STAR with massive gains in accuracy and alignment, Open-o3 Video not only boosts reliability but also enables confidence-aware scaling for real-world applications.

Understanding the intricacies of video content has long been a holy grail for artificial intelligence, where static images pale in comparison to the whirlwind of motion, interactions, and evolving scenes captured in footage. Videos pack in temporal dynamics—think a bustling street scene with cars zipping by and pedestrians weaving through—and spatial details that demand precise tracking over time. While large multimodal models have made strides in tasks like action recognition and video question answering, they often stumble when it comes to fine-grained reasoning over long, cluttered sequences. Enter Open-o3 Video, a groundbreaking non-agent framework that embeds explicit spatio-temporal evidence directly into the reasoning process, transforming how AI interprets the moving world.
Inspired by recent successes in “thinking with images”—where models like OpenAI’s o3 use operations such as cropping or zooming to weave visual evidence into language-based reasoning—the Open-o3 Video team sought to extend this paradigm to videos. But videos aren’t just images in sequence; they’re dynamic tapestries fraught with challenges like occlusions, rapid camera shifts, and fleeting events. Pinpointing when and where something happens requires coherent localization across both time and space, a feat that’s far trickier than handling still shots. Previous efforts in video reasoning have leaned on textual rationales or rough temporal spans, but they’ve fallen short on the precision needed for complex scenarios. Open-o3 Video steps in to fill this void, generating not just answers but highlighted timestamps, key objects, and bounding boxes that ground every step in observable visuals.
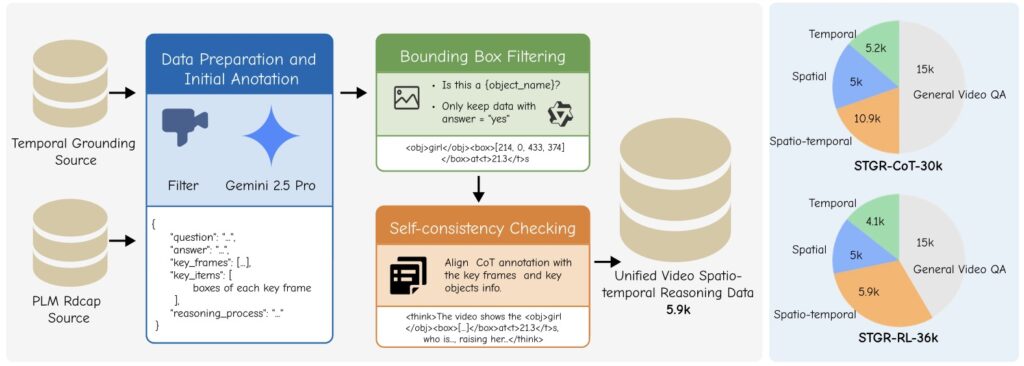
At the heart of this innovation is a meticulously crafted training corpus that addresses the glaring data shortage. Most existing datasets provide either temporal annotations for videos or spatial boxes for images, but rarely both in a unified way, let alone with detailed reasoning traces. To bridge this, the researchers curated two complementary datasets: STGR-CoT-30k for supervised fine-tuning (SFT) and STGR-RL-36k for reinforcement learning (RL). These draw from existing resources while adding 5.9k freshly annotated high-quality samples, each featuring question-answer pairs, timestamped key frames, localized bounding boxes, and chain-of-thought explanations that explicitly connect evidence to logic. For instance, imagine querying a video about a soccer match: the model wouldn’t just say “the ball crossed the goal line”; it would flag the exact 2:15 timestamp, zoom to the ball’s bounding box, and trace how that moment seals the score. This spatio-temporal supervision isn’t just additive—experiments show that without it, models falter dramatically, but incorporating even filtered samples from sources like VideoEspresso yields +2.8% in mean Average Precision (mAM) and +7.4% in mean Localized Grounding Metric (mLGM). The new annotations push those gains to +5.4% mAM and +10.4% mLGM, proving the pipeline’s power in fostering effective grounding.
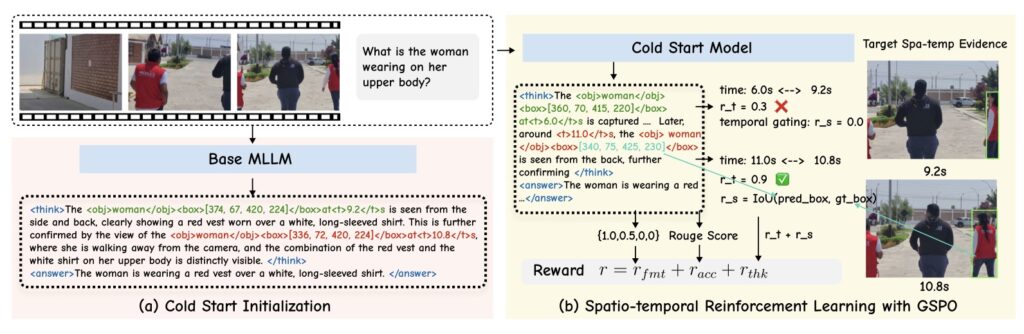
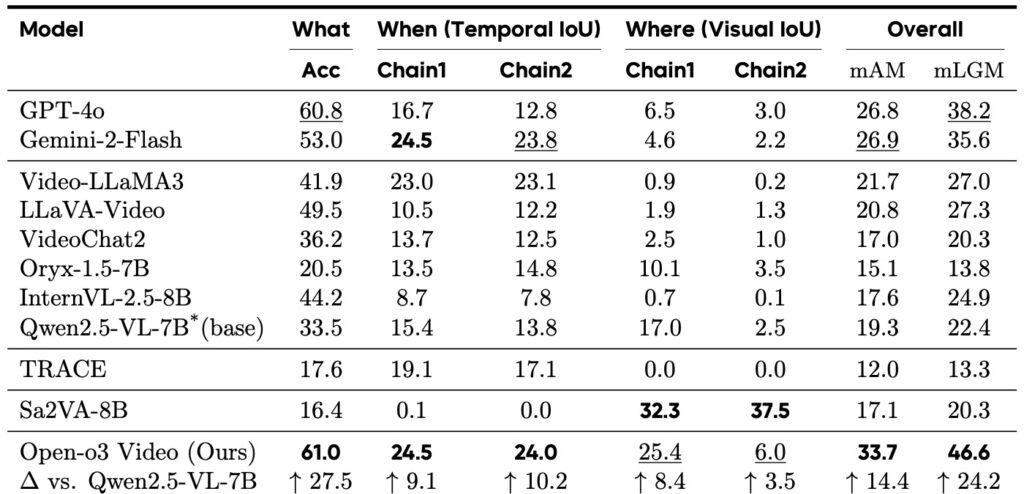
Training Open-o3 Video is no less ingenious, employing a cold-start RL strategy with rewards tailored to juggle answer accuracy, temporal alignment, and spatial precision. RL alone outperforms SFT by +2.1% mAM and +4.6% mLGM, as it directly optimizes for alignment, while SFT lays a stable foundation for reasoning formats. Combining them is where the magic happens: the duo hits 33.7% mAM and 46.6% mLGM on the V-STAR benchmark, a 14.4% mAM leap and 24.2% mLGM surge over the Qwen2.5-VL baseline. Within this joint approach, the Group’s Stable Preference Optimization (GSPO) edges out Group Relative Policy Optimization (GRPO) with +0.9% mAM and +1.3% mLGM, thanks to steadier rewards and better long-horizon temporal localization (a +2.9% boost in Chain1 temporal Intersection over Union, or tIoU). The reward design shines with innovations like adaptive temporal proximity, which scales penalties based on how closely predicted timestamps match annotations, and temporal gating, which filters out irrelevant segments to avoid distraction. Ablations confirm their impact: ditching proximity drops performance by 0.7% mAM and 1.4% mLGM, while removing gating causes steeper declines of 1.4% mAM and 1.7% mLGM.
The proof is in the benchmarks, where Open-o3 Video doesn’t just win—it dominates. On V-STAR, it eclipses strong contenders like GPT-4o, showcasing its prowess in grounded reasoning. Broader evaluations reveal consistent uplifts across video understanding tasks: VideoMME, WorldSense, VideoMMMU, and TVGBench all benefit from its precision. But the framework’s value extends beyond raw scores. Its grounded traces enable test-time scaling, like confidence-aware voting that verifies predictions using evidence scores—outpacing naive majority voting, as detailed in the appendix with prompts and results. This reliability boost is crucial for real-world deployment, where trusting an AI’s video analysis could inform everything from autonomous driving to forensic reviews.

Open-o3 Video sets a new standard for video AI, emphasizing transparency and precision in an era where multimodal models must handle the full spectrum of visual storytelling. Future iterations could weave in audio modalities or tackle even longer, more intricate clips, pushing toward holistic scene comprehension. Ethically, the work is grounded in public benchmarks and open-source data, with the new datasets slated for release to fuel community progress—free of private info and aligned with research licenses. While risks like annotation biases exist, the focus remains on academic advancement, ensuring this tool empowers rather than misleads. In a world increasingly shaped by video, Open-o3 Video isn’t just reasoning—it’s witnessing, with eyes wide open to every frame.