Breaking Barriers in Image Synthesis: How Meta’s New Model Redefines Customization
- Meta introduces “Imagine Yourself,” a cutting-edge model for personalized image generation that operates without traditional tuning methods.
- The model addresses key challenges in image diversity, identity preservation, and visual quality by employing innovative techniques.
- Extensive evaluations demonstrate that “Imagine Yourself” outperforms existing personalization models, setting a new standard for user-centric image synthesis.
In recent years, diffusion models have become a cornerstone of advanced image generation, showcasing their prowess across various tasks from text-to-image synthesis to image editing. As the demand for personalized content grows, researchers are increasingly focused on refining these models to cater to individual user preferences. Enter “Imagine Yourself,” Meta’s revolutionary model designed to transform personalized image generation by eliminating the need for tuning and making it accessible to all users. This groundbreaking approach not only enhances user experience but also improves image diversity and quality.
Traditional personalization methods often involve tuning models specifically for each user, which can be inefficient and cumbersome. These approaches frequently fall short in balancing identity preservation, adherence to complex prompts, and maintaining visual fidelity. Users have reported issues such as the “copy-paste” effect, where generated images closely resemble reference images but lack the ability to make significant changes, like altering expressions or poses. “Imagine Yourself” breaks this mold by utilizing a tuning-free framework that allows for a shared base model, enhancing accessibility while delivering tailored results.
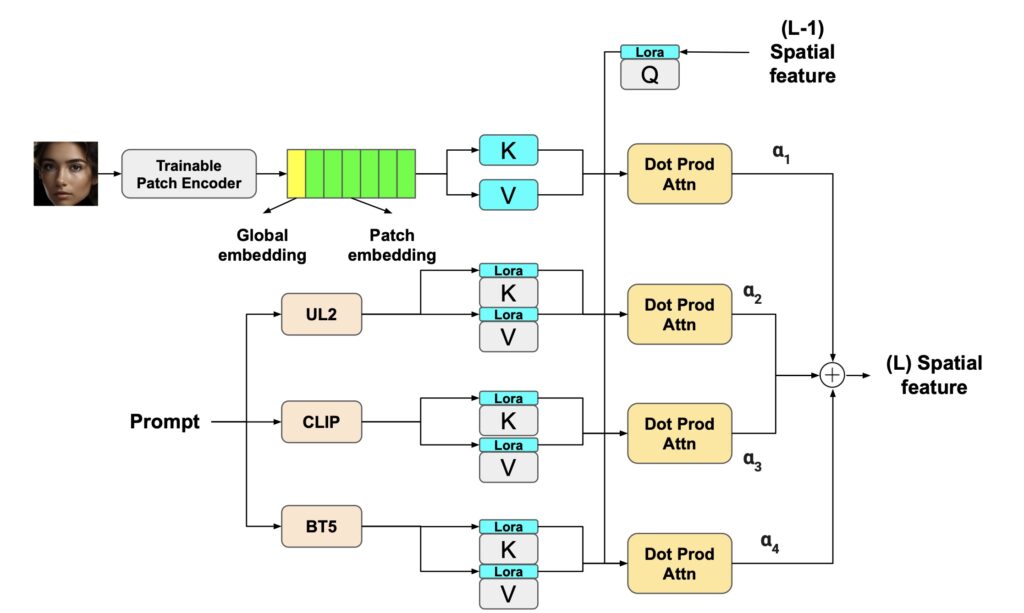
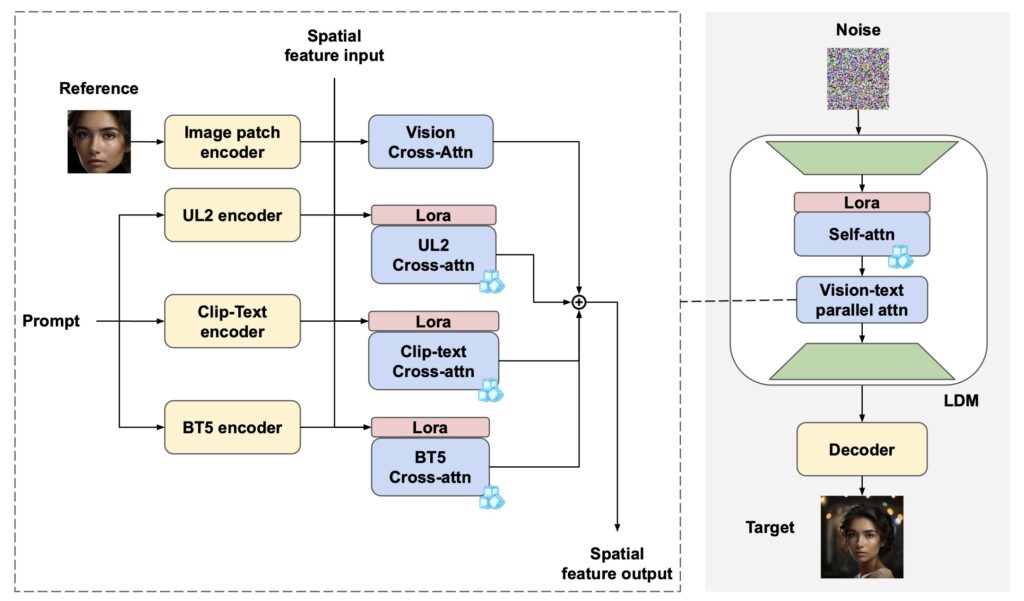
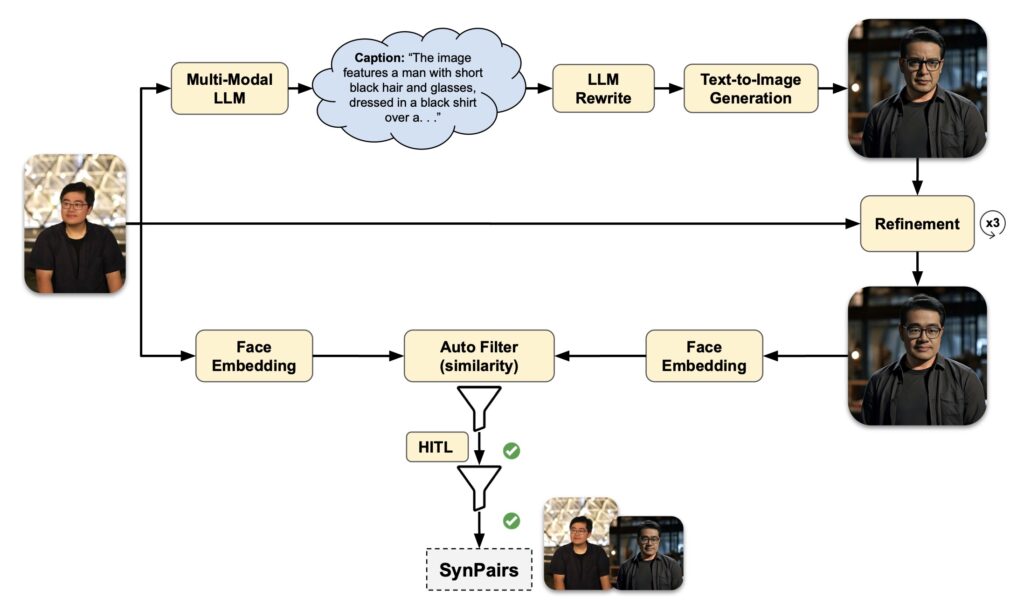
One of the standout features of “Imagine Yourself” is its innovative synthetic paired data generation mechanism, which fosters greater image diversity. This approach allows the model to generate a wider range of images from similar prompts, overcoming limitations seen in previous models. Additionally, the model employs a fully parallel attention architecture, featuring three text encoders and a fully trainable vision encoder. This design enhances text faithfulness, ensuring that generated images closely align with user prompts while preserving individual identity.
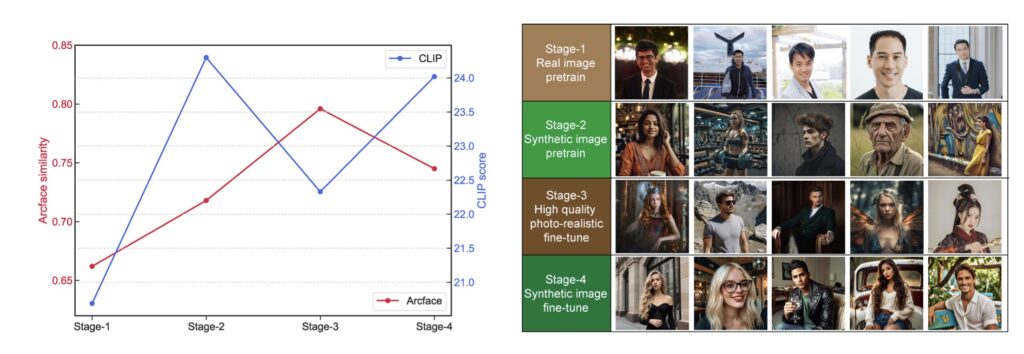
Moreover, the novel coarse-to-fine multi-stage fine-tuning methodology employed by “Imagine Yourself” significantly pushes the boundaries of visual quality. By progressively refining images through multiple stages, the model enhances details and aesthetics, producing results that stand out in terms of visual appeal. Human evaluations conducted on thousands of generated images indicate that “Imagine Yourself” not only matches but surpasses state-of-the-art personalization models in key metrics, including identity preservation, text alignment, and overall visual quality.

The implications of “Imagine Yourself” extend beyond mere technical advancements; it establishes a robust foundation for a variety of applications. From personalized avatars in gaming to customized content in marketing, this model opens new avenues for how users can interact with and enjoy digital imagery. By eliminating the need for individual model tuning, it democratizes access to high-quality personalized image generation, making it a valuable tool for creators and consumers alike.

Meta’s “Imagine Yourself” model signifies a pivotal shift in personalized image generation, overcoming the constraints of traditional tuning-based approaches. By focusing on diversity, identity preservation, and visual quality, this model sets a new benchmark in the field. As personalized content continues to gain traction, “Imagine Yourself” not only meets the demands of today’s users but also paves the way for future innovations in image synthesis and customization.

