When Mixture of Experts Meets Sparse Attention – A Paradigm Shift for Enterprise-Grade RAG Systems
- MoBA’s Hybrid Architecture combines MoE efficiency with dynamic attention routing to achieve 95.31% sparsity
- 10M-token context windows become practical through subquadratic scaling – 16x faster than conventional attention
- 100% open-source implementation allows seamless integration with existing LLMs while maintaining full model capabilities
The artificial intelligence landscape witnessed a tectonic shift this week as researchers from Moonshot AI and Tsinghua University unveiled Mixture of Block Attention (MoBA) – a breakthrough attention mechanism that effectively removes context length limitations for large language models. This innovation arrives just months after DeepSeek’s R1 announcement, positioning China at the forefront of long-context AI development.
The Architecture Revolution
At its core, MoBA reimagines attention computation through three radical design choices:
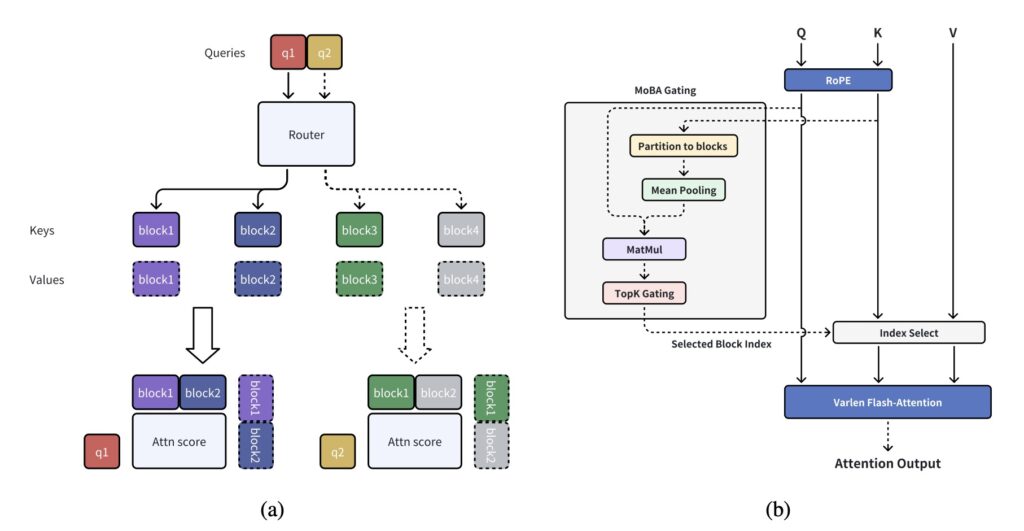
- Blockwise Expert Specialization
By dividing context into 512-token blocks with independent key-value memories, MoBA enables localized attention patterns similar to human cognitive processing. The system’s dynamic gating mechanism (top-k=3 selection) mimics how our brains retrieve relevant memories while ignoring irrelevant information. - Causal Hybrid Processing
Unlike previous sparse attention methods, MoBA maintains crucial current-block attention with causal masking while dynamically retrieving historical blocks. This dual-stream approach achieves 2.6× better trailing token accuracy compared to pure sparse attention baselines. - Training-Free Optimization
Through innovative “attention layer hot-swapping,” organizations can convert existing LLMs to MoBA architecture without full retraining. Early adopters report 81.25% compute savings during prefill phases when handling million-token documentation sets.

Real-World Implications
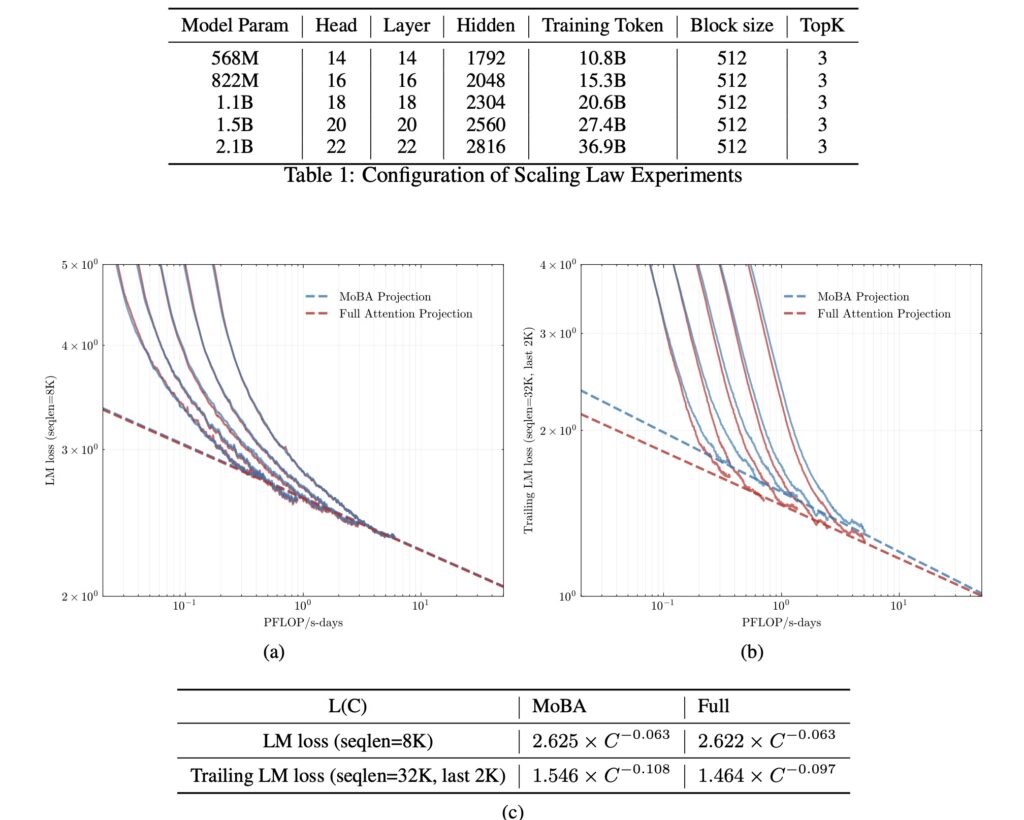
The research paper demonstrates staggering practical results:
- 95% accurate information retrieval in 1M-token codebases (vs 63% for sliding window approaches)
- 6.5x faster legal document analysis compared to FlashAttention-optimized models
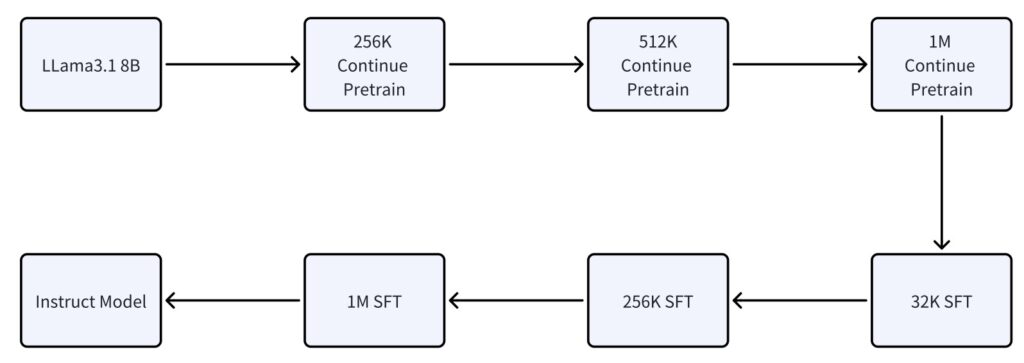
- Seamless 32K→1M context window expansion using progressive block size scaling
“This isn’t just about handling longer sequences – it’s about enabling AI systems to develop true contextual awareness,” explains Dr. Wei He, lead architect of the project. “Imagine an AI developer that understands every file in your codebase, or a legal assistant that remembers every clause in a 10,000-page contract.”
The Open Source Advantage
Unlike previous long-context solutions locked behind API paywalls, MoBA’s complete implementation is available on GitHub. This democratization enables:
- Enterprise Adoption – On-prem deployment for sensitive data environments
- Research Acceleration – Built-in support for 10M-token experiments via distributed query heads
- Ecosystem Growth – Pre-trained adapters for Llama, Mistral, and Qwen architectures
As global enterprises scramble to implement this technology, early benchmarks suggest MoBA could become the de facto standard for RAG systems within 12 months. With its unique combination of efficiency gains and architectural flexibility, this innovation doesn’t just push context boundaries – it redefines what’s possible in enterprise AI integration.