Introducing WorldPlay: The streaming diffusion model that finally balances 24 FPS speed with long-term geometric memory.
- Breaking the Trade-off: WorldPlay solves the persistent conflict between real-time generation speed and long-term memory, enabling instant visual feedback without the environment “forgetting” its structure.
- The Trio of Innovation: The model relies on three novel components—Dual Action Representation for control, Reconstituted Context Memory for stability, and Context Forcing for efficient learning.
- High-Fidelity Simulation: Capable of generating streaming 720p video at 24 FPS, WorldPlay opens new frontiers for embodied robotics and game development by creating consistent, navigable 3D worlds from a single prompt.

Artificial Intelligence is currently undergoing a pivotal shift. We are moving beyond the era of strictly language-centric tasks and entering the age of visual and spatial reasoning. At the forefront of this evolution are “world models”—computational systems capable of simulating dynamic 3D environments. These models empower agents to perceive surroundings and interact with complex geometries, promising a revolution in everything from video game development to embodied robotics.
However, until now, developers have faced a frustrating wall: the “Speed vs. Memory” trade-off. WorldPlay, a new streaming video diffusion model, has arrived to dismantle this barrier.
The Great Balancing Act: Speed vs. Consistency
To create a truly interactive virtual world, an AI must perform autoregressive prediction—predicting future video frames instantly in response to a user’s keyboard or mouse commands. This requires immense speed (low latency). However, to make that world feel real, the AI must also possess long-term geometric consistency. If you walk past a building, turn around, and walk back, the building should still look the same.
Historically, achieving both simultaneously has been an open problem. As illustrated in recent research:
- The Speed-First Approach: Some methods prioritize speed using distillation techniques. While fast, they neglect memory. The result is a dream-like inconsistency where scenes morph or vanish upon revisiting them.
- The Memory-First Approach: Other methods preserve consistency using explicit or implicit memory banks. While accurate, these systems are computationally heavy, making real-time interaction sluggish and making the distillation process non-trivial.
WorldPlay resolves this by offering the best of both worlds: superior consistency at real-time speeds.
Under the Hood: Three Key Innovations
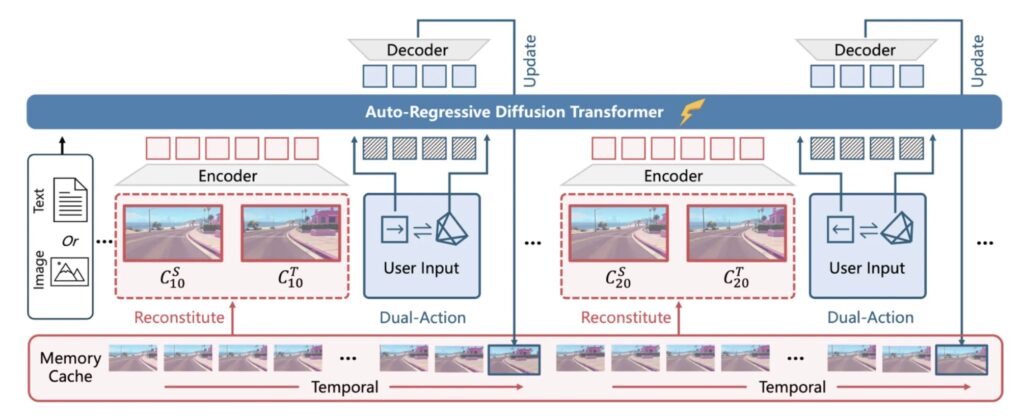
How does WorldPlay achieve what previous models could not? The architecture draws its power from three specific technical breakthroughs designed to handle user inputs, manage memory, and optimize speed.
1. Dual Action Representation
For a world to be interactive, it must understand user intent. WorldPlay utilizes a Dual Action Representation system. This mechanism is designed to enable robust action control, translating the user’s keyboard and mouse inputs into immediate visual changes within the generated video. This ensures that the world reacts fluidly to navigation commands.
2. Reconstituted Context Memory
To solve the issue of the environment “morphing” over time, the researchers developed Reconstituted Context Memory. This system dynamically rebuilds context from past frames.
Crucially, it employs temporal reframing. In standard models, “memory attenuation” occurs—the model slowly forgets older data. Temporal reframing keeps geometrically important but long-past frames accessible. This ensures that the structure of the world remains solid, even if the user interacts with it for a long duration.
3. Context Forcing
Perhaps the most distinct innovation is a novel distillation method called Context Forcing. To achieve real-time speeds, complex models are often “distilled” into faster, lighter versions (a teacher-student dynamic).
However, traditional distillation often loses the complex memory capabilities of the teacher. Context Forcing aligns the memory context between the teacher and the student. This preserves the student model’s capacity to use long-range information, preventing “error drift” (where small mistakes pile up over time) while maintaining the speed necessary for live interaction.
Performance and Future Horizons
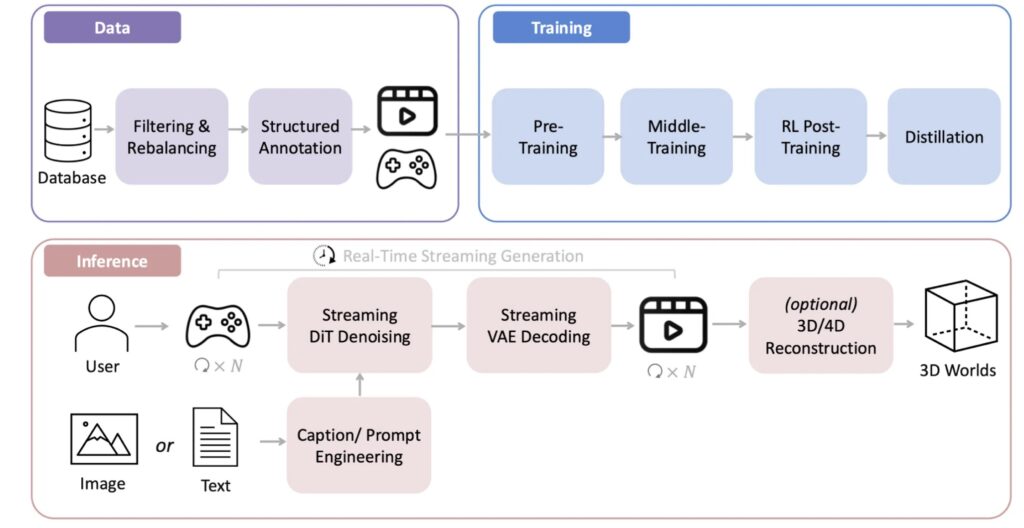
The results of these innovations are tangible. WorldPlay generates long-horizon streaming video at 720p resolution at 24 frames per second (FPS). It compares favorably with existing techniques, showing strong generalization across diverse scenes. Users can customize unique worlds starting from nothing more than a single image or a text prompt.
While the current framework focuses primarily on navigation control, the architecture holds the potential for much richer interactions, such as dynamic, text-triggered events.
WorldPlay provides a systematic framework for control, memory, and distillation, marking a critical step toward creating consistent and interactive virtual worlds. As research continues, extending this technology to generate longer videos, support multi-agent interaction, and simulate complex physical dynamics represents the exciting future of computational intelligence.