Why Floating-Point Isn’t Always the Winner in the Race for Efficient Large Language Models
- The Crossover Point Revealed: While floating-point (FP) formats shine in coarse-grained quantization by handling activation outliers effectively, integer (INT) formats gain the upper hand in fine-grained scenarios, offering superior accuracy and efficiency for formats like MXINT8.
- Bit Width Matters: In 8-bit fine-grained quantization, INT outperforms FP in both algorithmic precision and hardware performance, but for 4-bit formats, FP often edges out—unless outlier-mitigation techniques like Hadamard rotation tip the scales back toward INT.
- Challenging Industry Trends: This study advocates for a shift away from a one-size-fits-all FP approach in hardware like NVIDIA’s Blackwell, pushing for fine-grained INT formats to achieve better balance in accuracy, power, and efficiency for future AI accelerators.
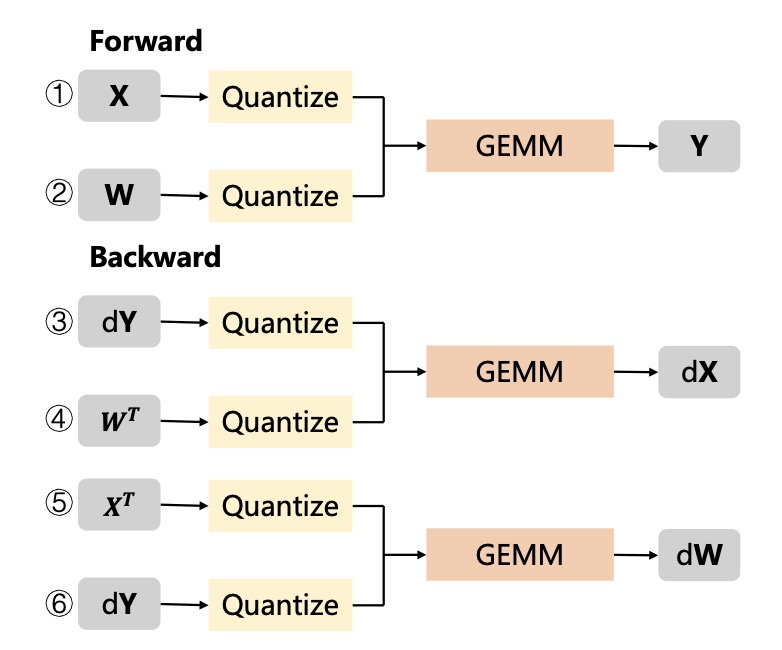
In the fast-evolving world of artificial intelligence, Large Language Models (LLMs) like those powering chatbots and virtual assistants have become indispensable. But their massive size brings hefty computational and memory demands, making quantization—a technique to compress models into lower-precision formats—essential for real-world deployment. Enter the showdown between integer (INT) and floating-point (FP) quantization formats. Modern AI hardware, exemplified by NVIDIA’s cutting-edge Blackwell architecture, is betting big on low-precision FP formats like FP8 and FP4 to tackle the pesky problem of activation outliers in LLMs. These outliers, rare but massive spikes in data values, wreak havoc on low-precision representations, and FP’s dynamic range seems tailor-made to handle them gracefully. Yet, as this comprehensive study reveals, the industry’s FP favoritism might be overlooking a more balanced contender: INT formats, especially when quantization gets fine-grained.
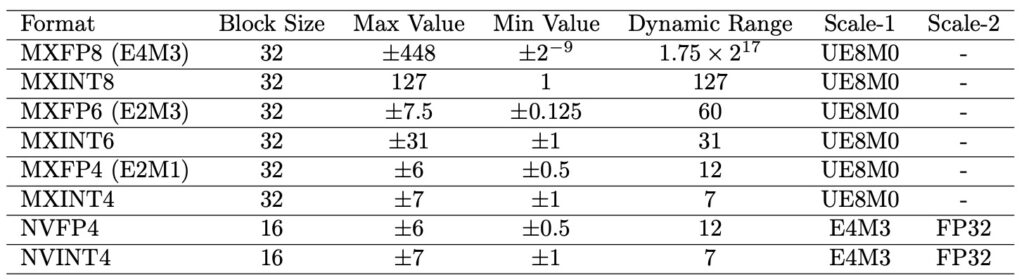
The core challenge in quantizing LLMs stems from their Transformer-based architecture, where activation distributions often feature significant outliers—large-magnitude values that occur infrequently but demand a wide dynamic range. Traditional INT formats struggle here because they distribute precision uniformly, potentially clipping these outliers and degrading model performance. In contrast, FP formats allocate more precision to larger values through their exponent bits, making them a natural fit for outlier-heavy scenarios. This is why hardware giants are pivoting toward FP: it promises efficient deployment without sacrificing too much accuracy. However, this trend is built on shaky ground. Most prior research has either zeroed in on one format or compared them only at coarse levels, like per-channel quantization, ignoring how the story changes at finer granularities. Fine-grained, or block-wise, quantization—dividing data into small blocks (e.g., 32 elements in Microscaling or MX formats, or 16 in NVIDIA’s NV formats)—has become a go-to method for taming outliers. But without a unified comparison, algorithm and hardware designers lack clear guidance on when FP truly outshines INT.
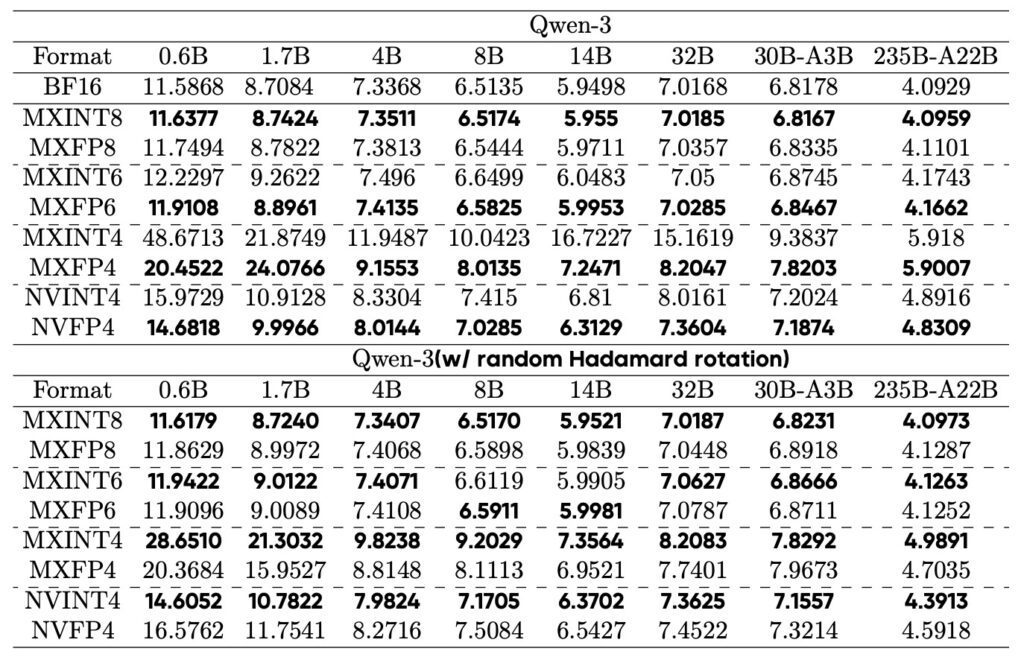
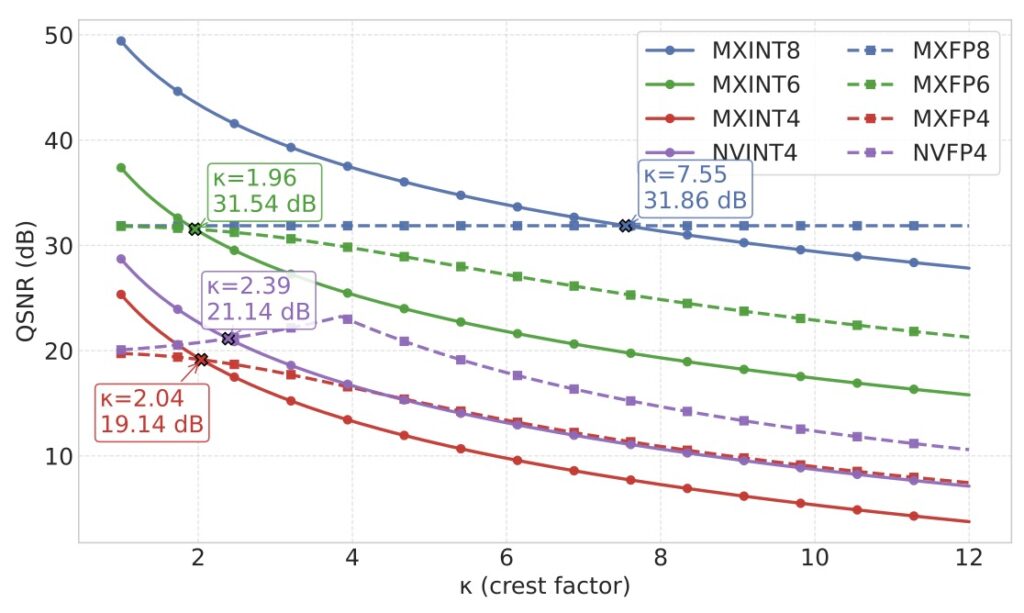
This paper bridges that gap with a systematic investigation, introducing integer variants like MXINT8, MXINT6, MXINT4, and NVINT4 to directly pit against their FP counterparts (MXFP8, MXFP6, MXFP4, NVFP4). The results uncover a fascinating “crossover point” in performance. At coarse granularities, FP reigns supreme, leveraging its dynamic range to manage broad distributions effectively. But as block sizes shrink and granularity finer, the local dynamic range within each block narrows, allowing INT’s uniform precision to shine. Suddenly, INT isn’t just competitive—it’s often superior. For instance, in popular 8-bit fine-grained formats like MX with a block size of 32, MXINT8 outperforms MXFP8 in both algorithmic accuracy and hardware efficiency. This isn’t just a minor edge; it translates to real-world gains in power consumption and processing speed, making INT a smarter choice for resource-constrained environments like edge devices or data centers.
Diving deeper into lower bit widths, the trade-offs become even more nuanced. For 4-bit formats, FP variants like MXFP4 and NVFP4 typically hold an accuracy advantage, better preserving model performance amid aggressive compression. However, the study demonstrates that this isn’t set in stone. By applying outlier-mitigation techniques such as random Hadamard rotation—a method that rotates data to distribute outliers more evenly—NVINT4 can actually surpass NVFP4 in accuracy. This highlights how clever algorithmic tweaks can elevate INT formats, challenging the notion that FP is inherently better for low-bit scenarios. Moreover, the research introduces a novel symmetric clipping method to address gradient bias in fine-grained low-bit INT training. This innovation enables nearly lossless performance for MXINT8 training, ensuring that models don’t just deploy efficiently but also train without unnecessary accuracy hits.
These findings aren’t just academic—they carry profound implications for the future of AI hardware. The current trajectory, heavily skewed toward FP as seen in architectures like Blackwell, assumes a one-size-fits-all solution that’s proving suboptimal. Fine-grained INT formats, particularly MXINT8, offer a compelling balance: they match or exceed FP in accuracy while delivering better power efficiency and simpler hardware implementation. Imagine AI accelerators that run cooler, consume less energy, and scale more easily across devices—from smartphones to supercomputers. By advocating for algorithm-hardware co-design that prioritizes these INT options, this study calls on academia and industry to rethink their strategies. It’s time to move beyond FP hype and embrace a more nuanced approach, ensuring that the next generation of LLMs isn’t just powerful, but sustainably efficient.
This comprehensive comparison doesn’t just fill a research void; it sparks a broader conversation about innovation in AI. As LLMs continue to proliferate, driving everything from personalized recommendations to creative writing, optimizing their quantization will be key to democratizing access. Whether you’re a hardware engineer, a machine learning researcher, or just an AI enthusiast, these insights underscore that the best path forward lies in flexibility—evaluating INT and FP not in isolation, but across the spectrum of granularities and techniques. The result? Smarter, greener AI that pushes the boundaries of what’s possible.