Meta’s Large Concept Models (LCMs): A New Paradigm in AI Language Modeling
- Semantic-Level Modeling: LCMs operate on high-level “concepts” rather than token-by-token processing, enabling a deeper understanding of language and multimodal data.
- Enhanced Generalization: Trained on English texts, LCMs exhibit strong zero-shot performance across multiple languages and modalities, outperforming similar-sized LLMs.
- Open-Source Research: Meta provides free access to LCM training code, encouraging innovation in alternative AI architectures.
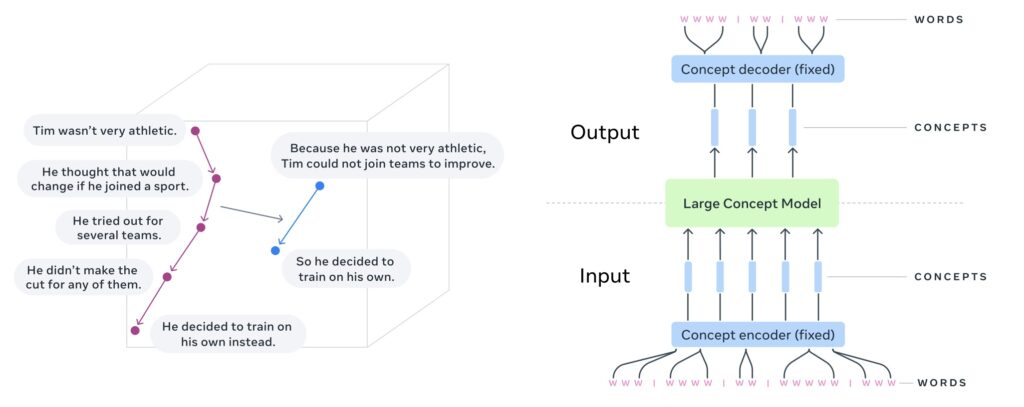
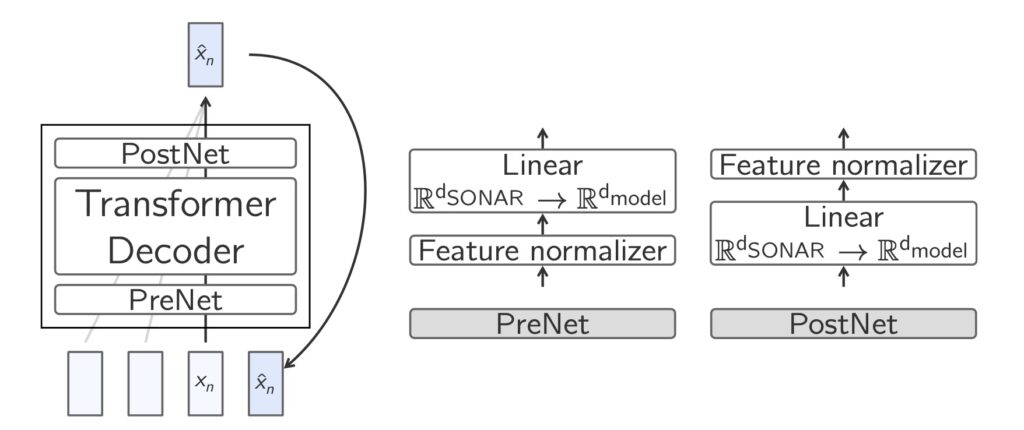
Large Concept Models (LCMs) by Meta represent a significant departure from traditional Large Language Models (LLMs), which focus on token-level processing. Instead, LCMs analyze and generate language at a conceptual level, where “concepts” are defined as high-level semantic representations such as sentences or speech segments.
This innovative approach decouples reasoning from language structure, enabling LCMs to function seamlessly across multiple languages and data modalities. By leveraging the SONAR sentence embedding space, which supports 200 languages, LCMs shift the focus from discrete tokens to a richer, more abstract semantic layer.
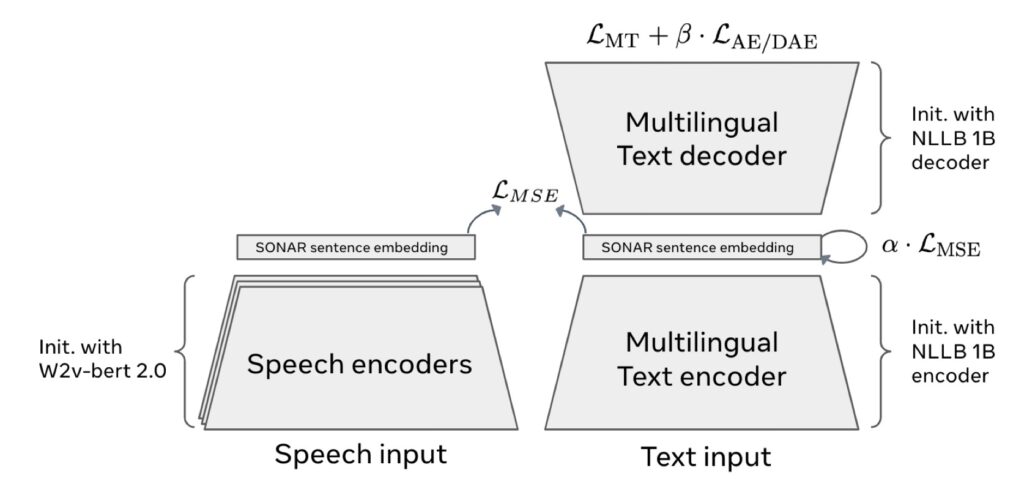
Innovative Architecture and Training
The LCM architecture relies on advanced diffusion-based methods, embedding modeling, and quantized SONAR representations. Key features include:
- Concept-Level Autoregression: Predicting the next sentence or high-level concept in a sequence.
- Zero-Shot Capabilities: Exceptional generalization to languages and contexts not included in training.
- Scaling Up: Models range from 1.6B to 7B parameters, with training data exceeding 2.7 trillion tokens.
LCMs perform tasks such as summarization and summary expansion, surpassing benchmarks set by Gemma, Mistral, and Llama-3.1-8B-IT models of similar size.

Challenges and Future Directions
While LCMs exhibit impressive generalization and multilingual performance, they face unique challenges:
- Semantic Ambiguity: Predicting the next sentence is inherently more complex than token prediction, given the vast space of possible continuations.
- Embedding Limitations: Errors in embedding space can result in invalid or nonsensical outputs.
- Beam Search and Scoring: Current models lack robust mechanisms to sample and rank sentence embeddings for optimal predictions.
Future work will focus on refining concept embeddings, scaling models beyond 70B parameters, and enhancing fine-tuning techniques.
Open-Source Commitment and Industry Impact
Meta’s decision to open-source the LCM training code and supporting scripts reflects a commitment to fostering innovation in the AI research community. By challenging the dominance of token-based LLMs, LCMs open new pathways for improving multilingual, multimodal, and semantically rich AI applications.
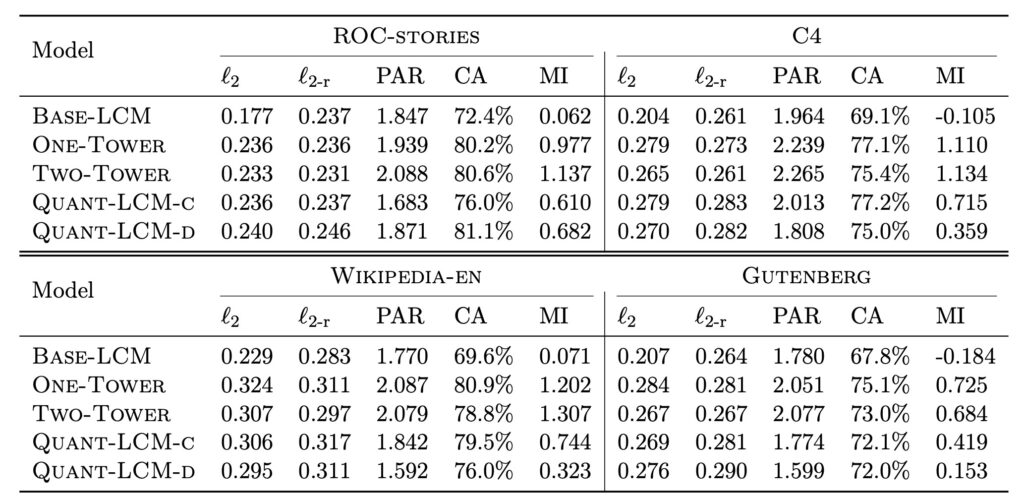
LCMs signal a shift in AI language modeling, offering a promising alternative to traditional architectures and paving the way for more intuitive, concept-driven machine intelligence.