Achieving Human Parity with Advanced Neural Codec Language Models
- Human Parity Achieved: VALL-E 2 marks the first instance of achieving human parity in zero-shot text-to-speech synthesis.
- Enhanced Stability and Efficiency: Introduces Repetition Aware Sampling and Grouped Code Modeling to improve stability and speed.
- Broad Applications: Potential for aiding individuals with speech impairments and other practical applications.
The field of text-to-speech (TTS) synthesis has seen remarkable advancements with the development of neural codec language models. The latest breakthrough, VALL-E 2, has set a new standard by achieving human parity in zero-shot TTS, making it the first of its kind to accomplish this feat. This model not only enhances the quality of synthesized speech but also addresses key issues of stability and efficiency, paving the way for broader applications and improved accessibility.
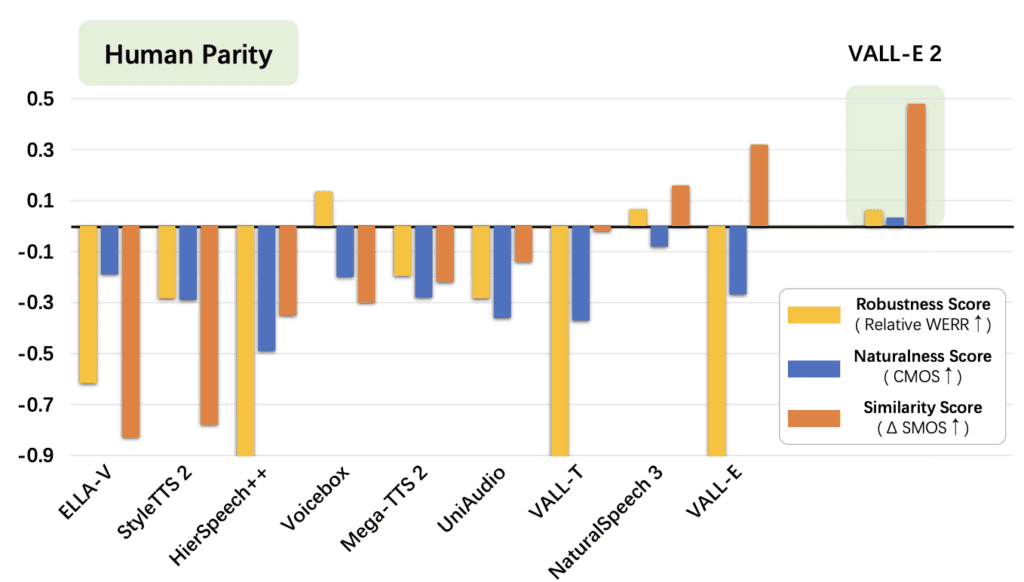
Human Parity in Text-to-Speech
VALL-E 2 builds on the success of its predecessor, VALL-E, by introducing two significant enhancements: Repetition Aware Sampling and Grouped Code Modeling. These advancements allow VALL-E 2 to generate speech that is indistinguishable from human speech in terms of naturalness, robustness, and speaker similarity. Through extensive testing on datasets like LibriSpeech and VCTK, VALL-E 2 has demonstrated its capability to synthesize high-quality speech, even for complex sentences and repetitive phrases.
Enhanced Stability and Efficiency
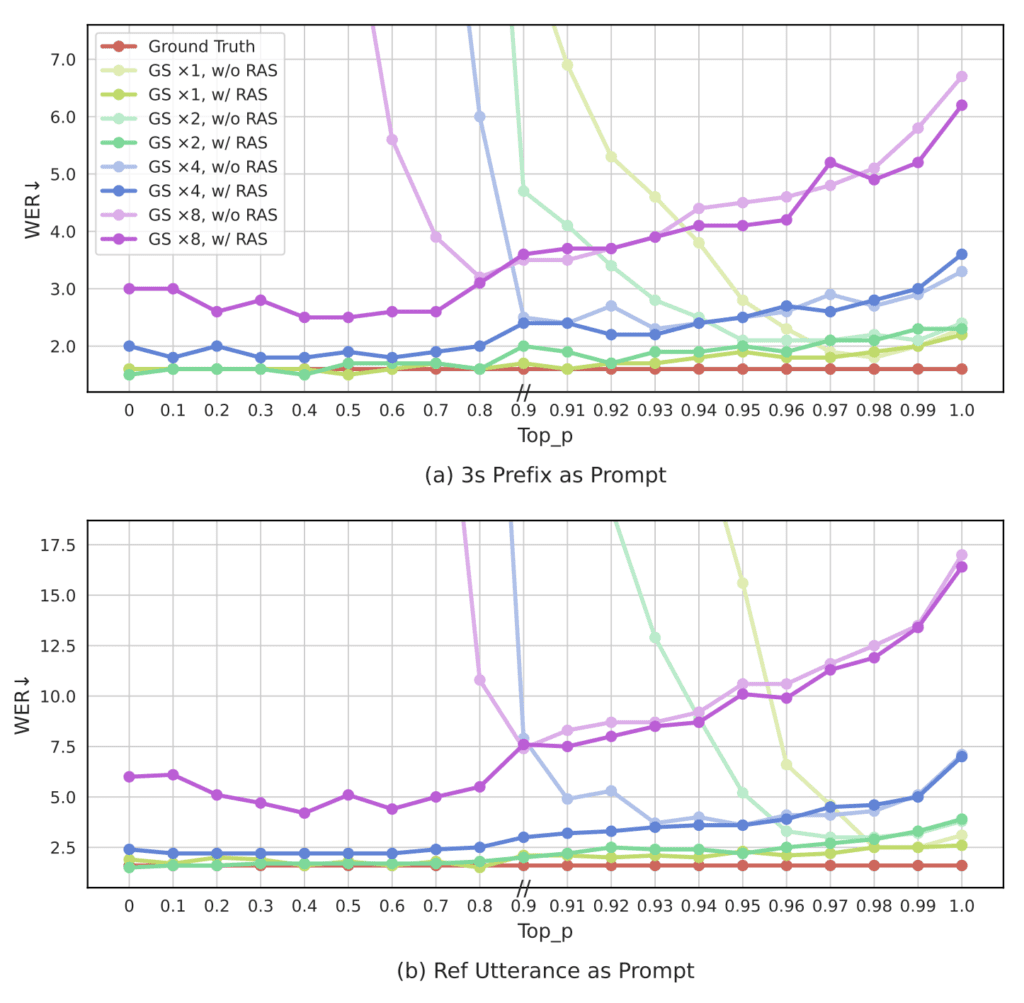
One of the major challenges with previous models, including the original VALL-E, was maintaining stability during the inference process. VALL-E 2 addresses this with Repetition Aware Sampling, which refines the nucleus sampling process by accounting for token repetition in the decoding history. This method stabilizes decoding and prevents the infinite loop issue that plagued earlier models.
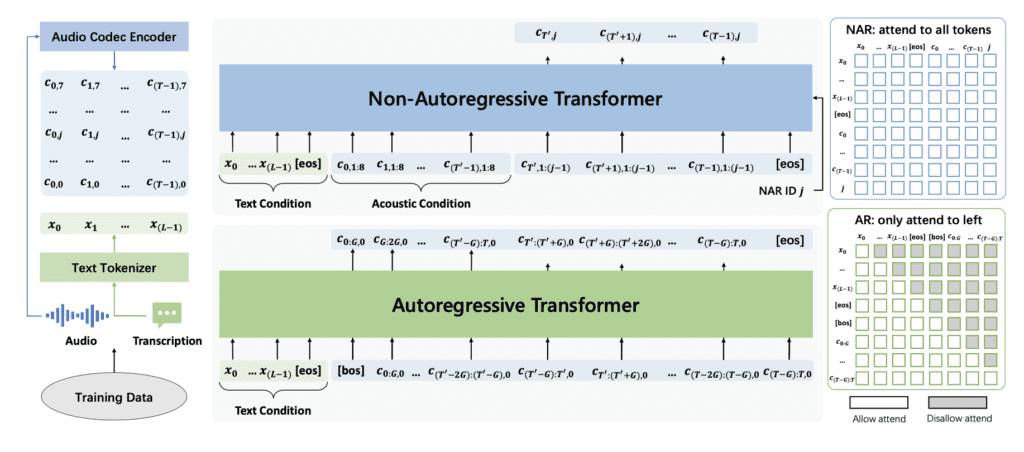
Additionally, VALL-E 2 introduces Grouped Code Modeling, which organizes codec codes into groups to shorten the sequence length. This enhancement not only boosts inference speed but also improves the model’s efficiency in handling long sequences. As a result, VALL-E 2 achieves a significant reduction in computational overhead, offering around 23 times speedup compared to traditional models like Stable Video Diffusion (SVD) and six times speedup over existing works, without compromising on the quality of generated speech.
Broad Applications and Implications
The advancements brought by VALL-E 2 have far-reaching implications. For instance, it holds significant potential in assisting individuals with speech impairments, such as those with aphasia or amyotrophic lateral sclerosis (ALS). By generating speech that closely mimics the speaker’s voice and emotion, VALL-E 2 can help these individuals communicate more effectively.
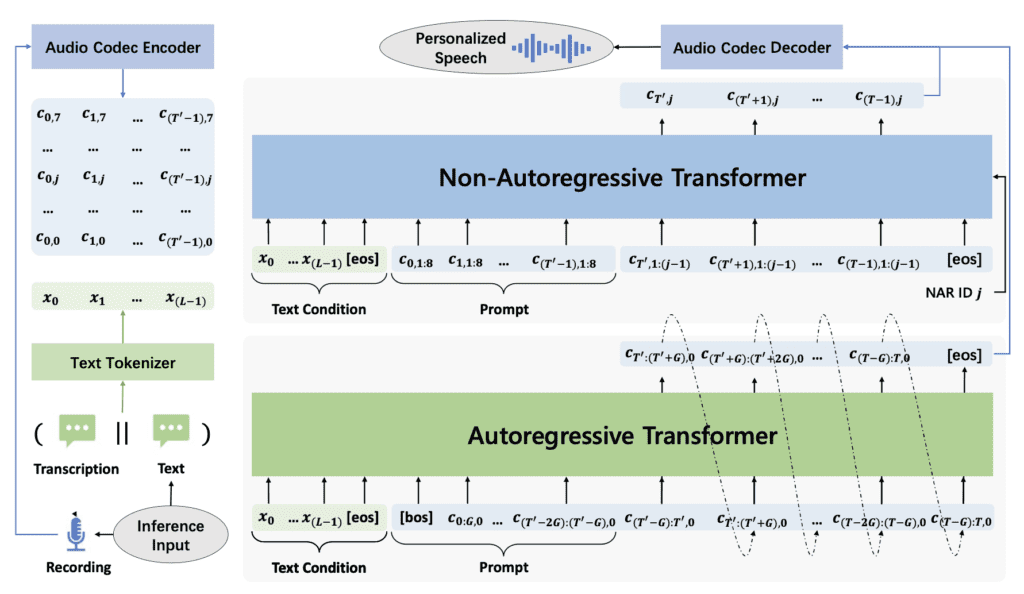
Moreover, VALL-E 2’s ability to synthesize high-quality speech with minimal input opens up new possibilities for applications in digital assistants, customer service bots, and other AI-driven communication tools. The model’s efficiency and performance make it suitable for real-time applications, enhancing user experience and accessibility.
The journey to achieving human parity in zero-shot text-to-speech synthesis has been marked by significant milestones. VALL-E 2 represents a major leap forward, addressing the limitations of previous models and setting new benchmarks in the field.
Real-World Applications
The practical applications of VALL-E 2 are vast. For individuals with speech impairments, VALL-E 2 can provide a voice that closely mimics their own, helping them communicate more naturally. In customer service, digital assistants powered by VALL-E 2 can offer more human-like interactions, improving customer satisfaction.
Furthermore, VALL-E 2’s efficiency and performance make it ideal for real-time applications, such as virtual assistants and interactive voice response systems. By providing high-quality speech synthesis quickly and reliably, VALL-E 2 enhances the user experience across various platforms.
VALL-E 2 marks a significant advancement in the field of text-to-speech synthesis, achieving human parity and setting new standards for stability and efficiency. With its innovative Repetition Aware Sampling and Grouped Code Modeling, VALL-E 2 addresses key challenges in TTS synthesis, offering high-quality, natural-sounding speech with minimal computational overhead.
The model’s potential applications are vast, from assisting individuals with speech impairments to enhancing digital assistants and customer service bots. As AI technology continues to evolve, VALL-E 2 paves the way for more accessible, efficient, and high-quality text-to-speech solutions, bringing us closer to a future where seamless, human-like communication is the norm.