The “Lost in Conversation” phenomenon reveals a critical flaw in LLM architecture that standard benchmarks have completely missed.
- The Multi-Turn Performance Gap: While top-tier models like GPT-4.1 and Gemini 2.5 Pro achieve 90% success in single prompts, their performance plummets to just 65% when tasks are broken into a natural, multi-turn conversation.
- Reliability vs. Intelligence: The failure isn’t a lack of “brain power”—aptitude only drops by 15%—but rather a 112% explosion in unreliability, where models make premature assumptions and fail to self-correct.
- The “One-Shot” Solution: Current reasoning models (o3, DeepSeek R1) and traditional fixes like setting temperature to 0 fail to bridge this gap, leaving “everything-upfront” prompting as the only reliable workaround.
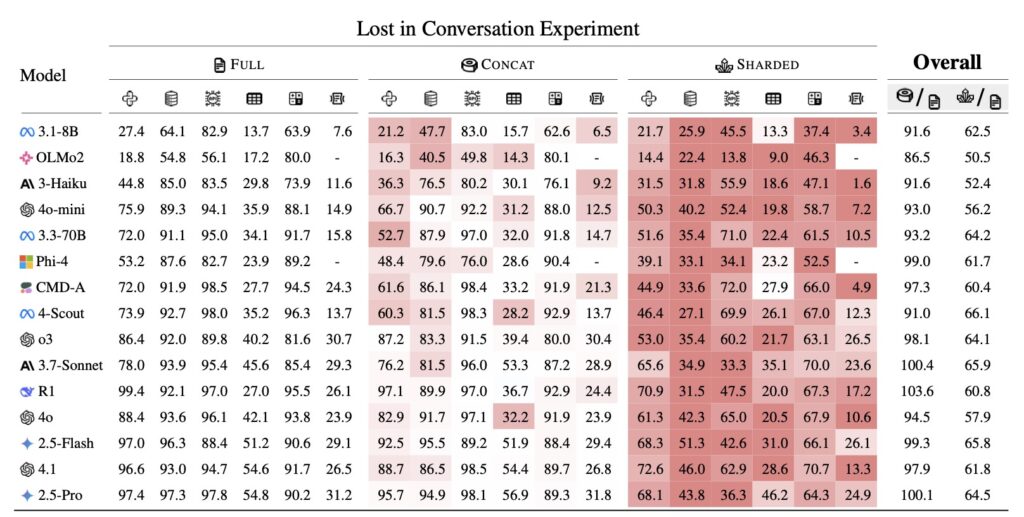
A groundbreaking joint research paper from Microsoft Research and Salesforce has sent shockwaves through the AI development community. After testing 15 of the industry’s most advanced Large Language Models (LLMs)—including GPT-4.1, Gemini 2.5 Pro, Claude 3.7 Sonnet, o3, DeepSeek R1, and Llama 4—across more than 200,000 simulated conversations, researchers have identified a systematic failure they call the “Lost in Conversation” phenomenon.
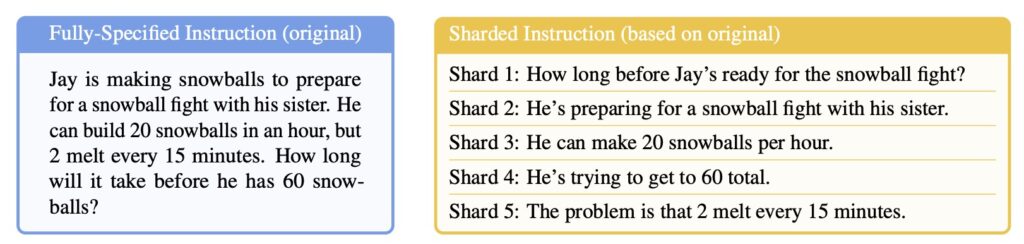
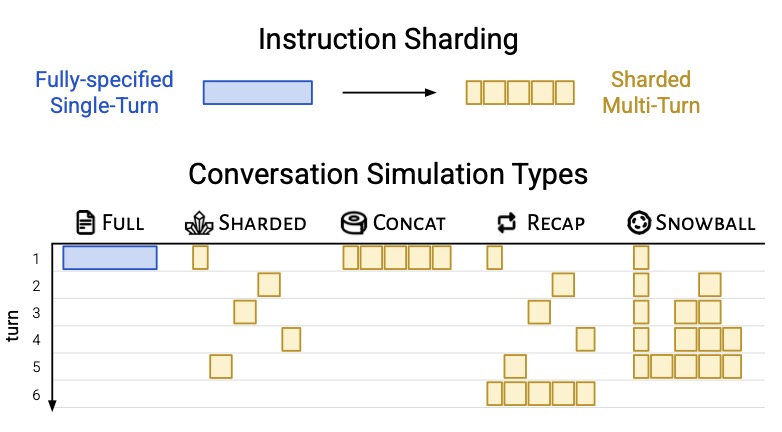
The core of the issue lies in how we interact with AI. While LLMs are marketed as conversational interfaces, they are primarily evaluated on “single-turn” benchmarks—perfect laboratory conditions where the AI receives all instructions at once. In reality, human communication is messy and underspecified; we reveal details gradually. The study found that as soon as a task is “sharded” across multiple turns, even the most “intelligent” models begin to fall apart.
The Anatomy of a Collapse
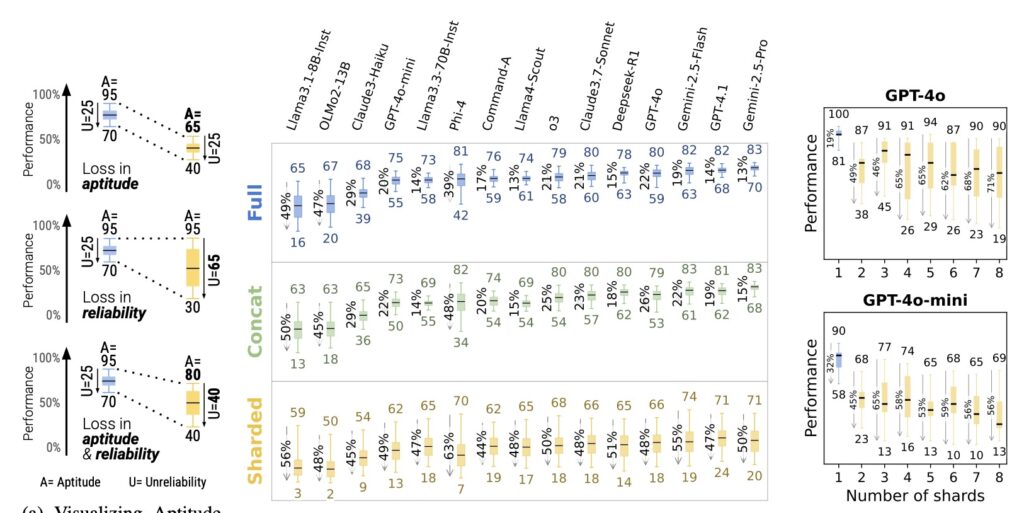
The data paints a grim picture for those building agents or complex chat workflows. In a single-turn prompt, the tested models maintained a robust 90% performance rate. However, when the exact same information was delivered through a multi-turn exchange, that success rate dropped to 65%.
Crucially, the researchers discovered that the models aren’t losing their fundamental ability to solve the problem—their aptitude only decreased by about 15%. Instead, their unreliability skyrocketed by 112%. This means the models still “know” how to do the work, but they become wildly inconsistent, essentially flipping a coin on whether they will successfully track the conversation’s context.
Why Do They Get Lost?
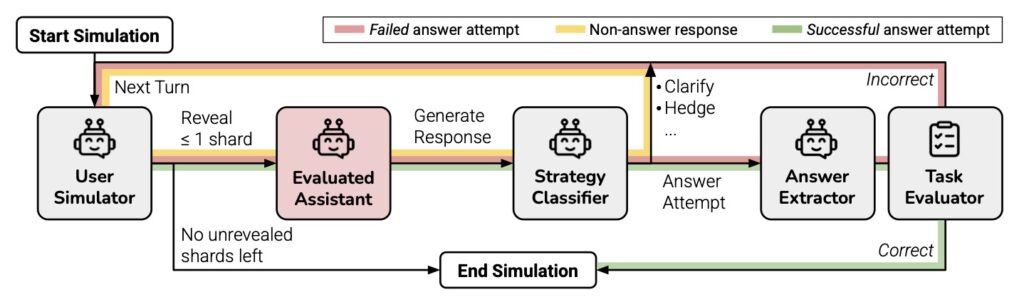
The study identified several behavioral “culprits” that lead to this degradation. First, LLMs suffer from premature generation: they often attempt to provide a final solution before the user has finished explaining the requirements. Once the model makes an incorrect assumption in an early turn, it “falls in love” with that mistake. Rather than correcting itself as new information arrives, the AI builds upon its initial error, leading to a compounding failure.
Furthermore, the phenomenon of “answer bloat” was observed, where multi-turn responses became 20% to 300% longer than single-turn equivalents. These longer responses introduce more “hallucinated” assumptions, which then get baked into the conversation’s permanent context. Even the latest reasoning models, such as OpenAI’s o3 and DeepSeek R1, which use extra “thinking tokens” to process logic, showed no significant improvement in these multi-turn settings.

Implications for the AI Industry
This discovery suggests that current AI benchmarks are fundamentally misleading. By testing models in “perfect” single-turn scenarios, developers are ignoring how the models behave in the real world. Setting the model’s temperature to 0—a common tactic to ensure consistency—offered almost no protection against this specific type of conversational decay.
For now, the only effective “fix” is a counter-intuitive one: stop treating AI like a conversational partner. To get the best results, users and builders should provide all necessary data, constraints, and instructions in a single, comprehensive “mega-prompt” rather than a back-and-forth dialogue. Until LLM builders prioritize native multi-turn reliability over raw single-turn scores, the smartest models on the market will continue to lose their way the moment the conversation gets interesting.