From “Text-and-Wait” to Fluid Reality—The Chinese Open-Source Model That Sees, Listens, and Speaks in Real-Time.
- True Full-Duplex Interaction: Unlike traditional AI that takes turns, MiniCPM-o 4.5 enables “live streaming” conversations where the AI can see, hear, and speak simultaneously, allowing for natural interruptions and proactive reactions.
- Small Model, Giant Performance: Despite having only 9 billion parameters, it outperforms proprietary titans like GPT-4o and Gemini 2.0 Pro in visual benchmarks, proving that local, open-source AI has officially caught up to the cloud giants.
- Extreme Versatility and Accessibility: From high-resolution OCR and voice cloning to seamless local execution via llama.cpp and Ollama, this model brings state-of-the-art multimodal intelligence to personal hardware like MacBooks.
For a long time, interacting with Artificial Intelligence felt like sending a letter and waiting for a reply. Even with the fastest LLMs, the “turn-based” nature of the exchange reminded us we were talking to a processor, not a person. That barrier just shattered. MiniCPM-o 4.5, a groundbreaking open-source model, has arrived to transform AI from a reactive chatbot into a proactive, omni-modal companion. It doesn’t just process your prompt; it lives in your environment.

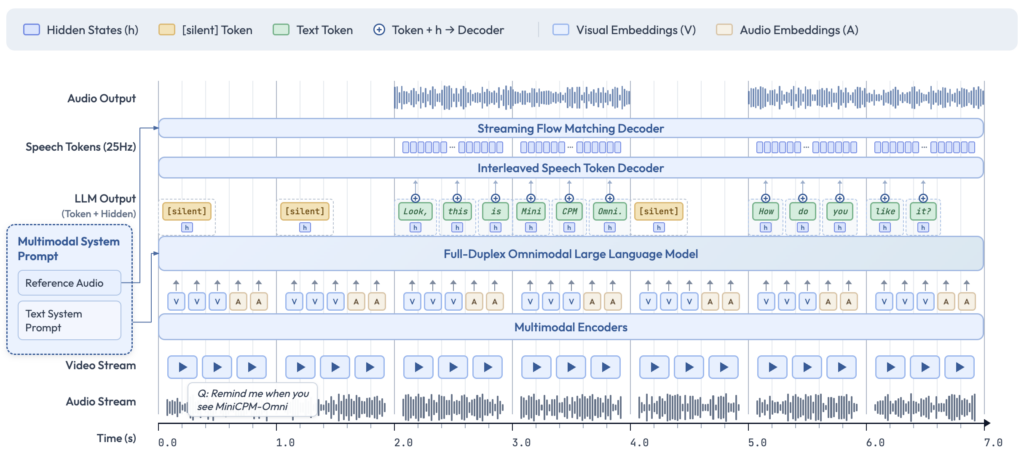
The standout feature of this model is its full-duplex multimodal live streaming. In plain English: it works like a phone call with vision. Built on an end-to-end architecture combining SigLip2, Whisper-medium, CosyVoice2, and Qwen3-8B, the model can process continuous video and audio streams while simultaneously generating speech and text. This means you can interrupt it mid-sentence, it can react to something it sees in your room while it’s talking, and it can even proactively nudge you with a reminder. It is the first time local AI has truly felt “alive.”
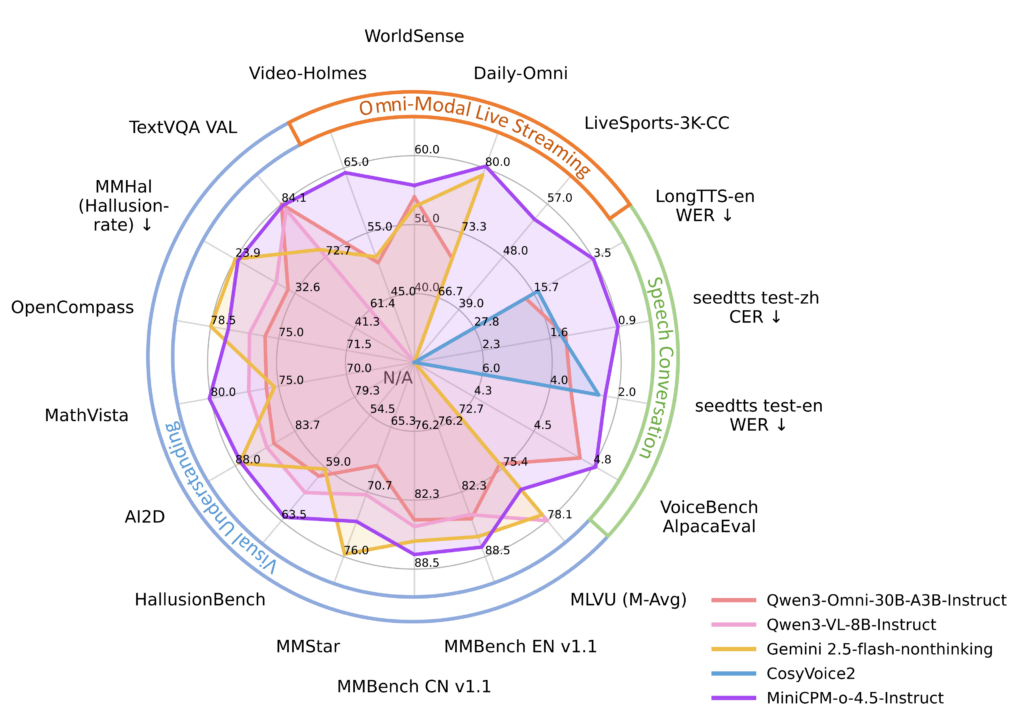
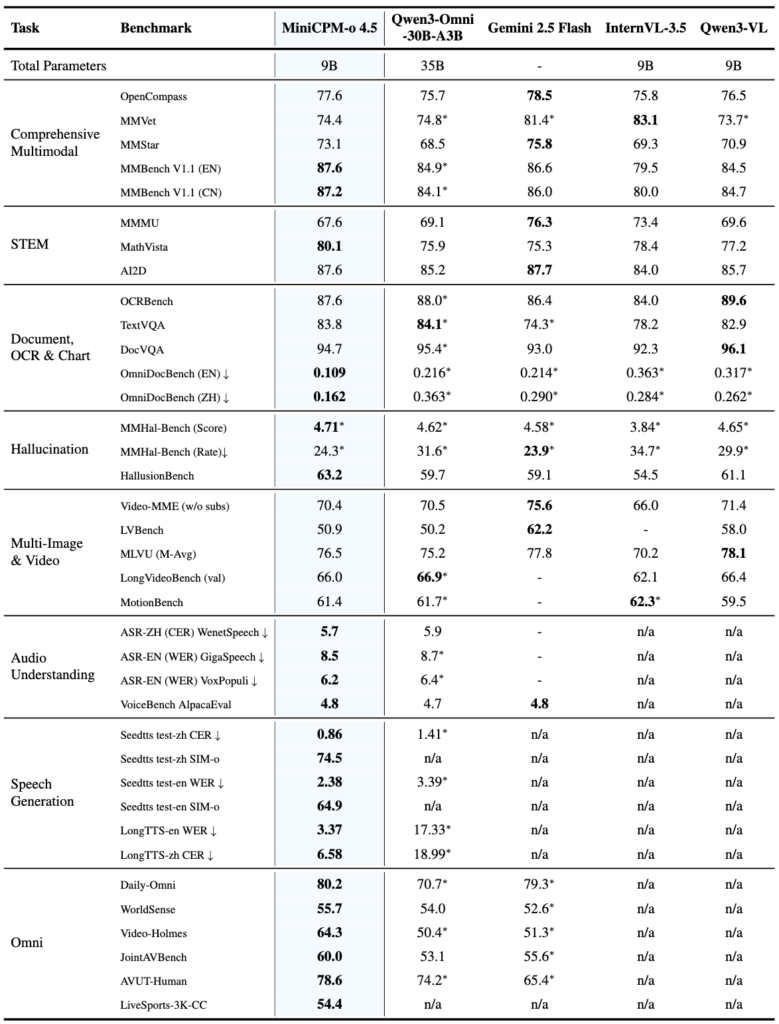
Despite its relatively lean 9B parameter size, MiniCPM-o 4.5 is a heavyweight in performance. It achieved a staggering 77.6 on the OpenCompass benchmark, surpassing proprietary giants like GPT-4o and Gemini 2.0 Pro in vision-language tasks. Its vision isn’t just fast; it’s precise. The model handles high-resolution images up to 1.8 million pixels and high-FPS video, outperforming specialized tools in document parsing. Whether it’s reading a complex English technical manual or identifying a blurred object in a 10fps video stream, the model’s “Thinking Mode” ensures accuracy that rivals the most expensive paid services on the market.
Beyond sight, its auditory soul is equally impressive. Supporting bilingual English and Chinese conversation, MiniCPM-o 4.5 offers voice cloning and role-play capabilities that surpass many dedicated Text-to-Speech tools. By providing a simple audio snippet, users can customize the model’s voice, making interactions feel deeply personal. Furthermore, it addresses the “hallucination” problem head-on, matching the trustworthiness of Gemini 2.5 Flash on the MMHal-Bench, ensuring that its bilingual chatter is as reliable as it is expressive.
Perhaps the most exciting aspect for developers and enthusiasts is its local accessibility. You don’t need a multi-million dollar server farm to experience this. With support for llama.cpp, Ollama, and GGUF quantization, MiniCPM-o 4.5 can run efficiently on local devices like a MacBook. The rollout of the llama.cpp-omni framework and WebRTC demos means that the “wow” factor of a seamless, seeing, and talking AI agent is now available to anyone with a decent laptop. We are no longer waiting for the future of AI; it’s officially running on our local machines.