V-Triune’s innovative reinforcement learning system empowers vision-language models to master both complex thought and detailed sight, heralding a new era of versatile AI.
- Unified Training Breakthrough: V-Triune introduces a pioneering reinforcement learning (RL) system, enabling vision-language models (VLMs) to learn both intricate visual reasoning and precise perception tasks concurrently within a single, unified training pipeline.
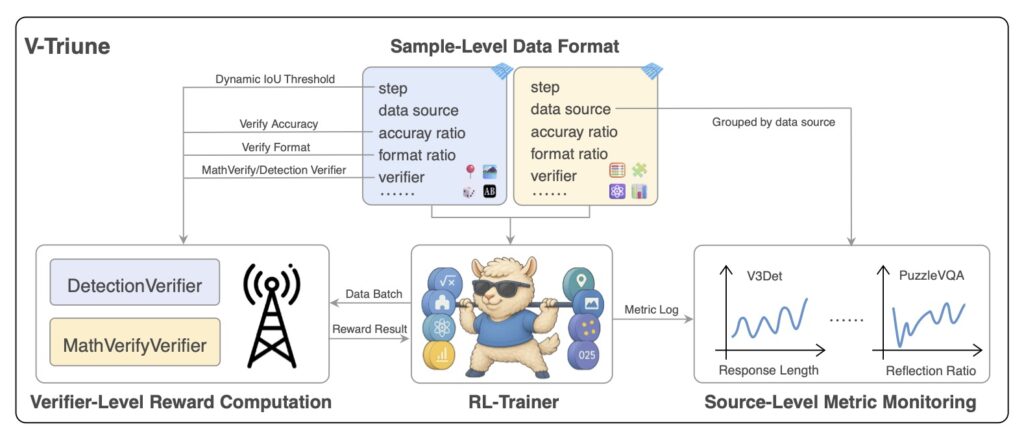
- Triple-Component Innovation: The system’s power lies in its three complementary components—Sample-Level Data Formatting, Verifier-Level Reward Computation, and Source-Level Metric Monitoring—alongside a novel Dynamic IoU reward mechanism designed to significantly improve performance on perception tasks.
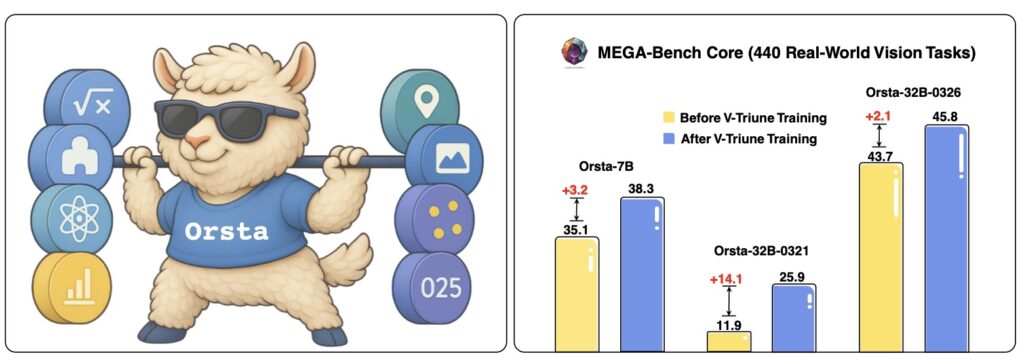
- Significant Performance Gains: Models trained using this system, dubbed Orsta, demonstrate substantial improvements (ranging from +2.1% to +14.1%) across diverse benchmarks, showcasing the effectiveness and scalability of this unified approach for advanced AI development.
The landscape of artificial intelligence is rapidly evolving, with reinforcement learning (RL) emerging as a powerful technique to enhance the capabilities of vision-language models (VLMs). While RL has shown promise in boosting reasoning skills, its application to perception-intensive tasks like object detection and grounding has remained a significant challenge. Addressing this gap, a novel system named V-Triune (Visual Triple Unified Reinforcement Learning) has been developed, offering a groundbreaking approach to jointly train VLMs on both visual reasoning and perception tasks. This unified framework not only simplifies the training process but also leads to substantial performance improvements, as demonstrated by the Orsta family of models.
Bridging Reasoning and Perception
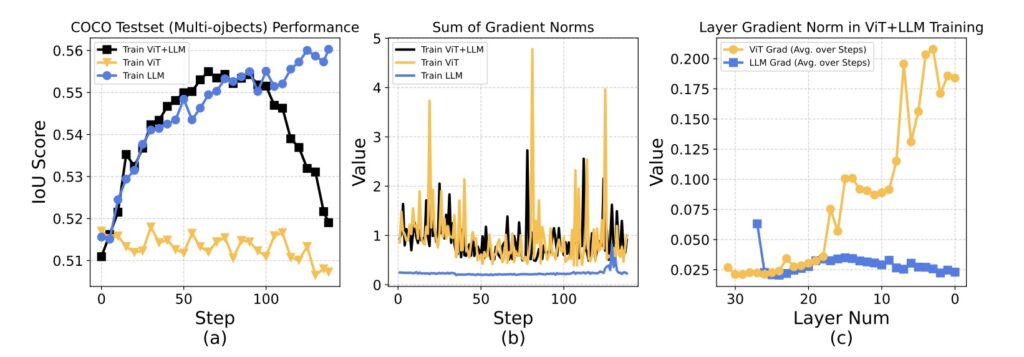
Recent advancements in large language models (LLMs) and VLMs have shifted focus from merely scaling pre-training to enhancing test-time performance, often through techniques like extending context length for Chain-of-Thought (CoT) reasoning. While RL has been explored for post-training VLMs, its use has largely been confined to narrow domains, typically visual reasoning tasks such as math and science question-answering. These applications often mirror RL training paradigms already established in LLMs. However, the effective scaling of RL to visual perception tasks, which demand distinct reward mechanisms and measures for training stability, has remained an open question. Perception tasks require the model to not just understand an image conceptually but to identify and locate objects with precision, a fundamentally different challenge than abstract reasoning.
V-Triune: A Three-Tiered Solution
V-Triune introduces a comprehensive solution through its three complementary components, each operating at a distinct level to achieve unification:
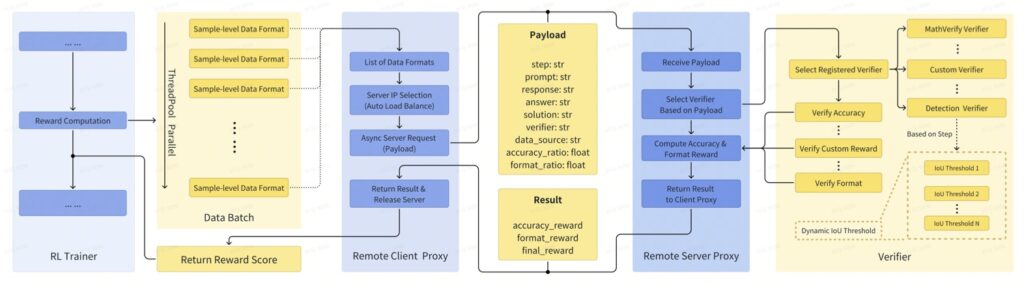
- Sample-Level Data Formatting: This component addresses the diverse nature of tasks and their reward requirements. It allows each individual data sample to define its own reward setup and specify the verifier (a mechanism to assess performance) it needs. This flexibility is crucial for handling a wide array of inputs within a single pipeline.
- Verifier-Level Reward Computation: To ensure modularity and task-adaptability, V-Triune assigns the responsibility of reward generation to specialized verifiers. These verifiers are tailored for specific task groups, delivering custom rewards that accurately reflect performance on those particular tasks. This means that a reasoning task might get rewarded for a correct textual answer, while a detection task gets rewarded for accurately drawing a bounding box.
- Source-Level Metric Monitoring: Managing a multi-task, multi-source learning environment requires robust tracking and diagnostics. This component logs metrics for each data source, which is vital for identifying potential issues with data quality or distribution and ensuring stable training across the board.

A key innovation within V-Triune is the Dynamic IoU (Intersection over Union) reward. This mechanism is specifically designed for visual perception tasks like object detection and grounding, which often struggle with fixed IoU thresholds for rewards. The Dynamic IoU reward addresses this by progressively adjusting the IoU threshold, starting with more relaxed criteria and gradually becoming stricter. This adaptive approach provides useful learning signals early in training, guides the model towards higher precision, and ultimately contributes to a more stable and scalable training procedure for perception tasks.

Orsta: Demonstrating Unified Power
Leveraging the V-Triune system, researchers have developed the Orsta model series, with variants ranging in size from 7 billion (7B) to 32 billion (32B) parameters, built upon the Qwen2.5-VL family of baseline models. These Orsta models underwent joint optimization across a diverse set of eight tasks. These included four visual reasoning tasks (Mathematics, Puzzle, Chart, and Science) and four visual perception tasks (Grounding, Detection, Counting, and Optical Character Recognition – OCR).
The results have been compelling. On the MEGA-Bench Core benchmark, a comprehensive test covering over 400 real-world visual tasks, Orsta models demonstrated substantial performance gains. These improvements ranged from +2.1% to an impressive +14.1% across the various 7B and 32B model variants compared to their strong backbones. These benefits also extended to prominent downstream benchmarks such as MMMU, MathVista, COCO, and CountBench, validating the effectiveness and scalability of the V-Triune approach. Interestingly, experiments suggest that RL in VLMs, as implemented by V-Triune, primarily acts as an alignment strategy. It refines the model’s decision-making processes and response behaviors rather than enabling the acquisition of entirely new knowledge, enhancing the utility and robustness of pre-trained VLMs.
Limitations and Future Horizons
Despite these successes, the researchers acknowledge areas for further investigation. One observation is the limited performance scaling in perception tasks compared to reasoning tasks. While reasoning tasks show clear trends of increasing response length and reflection (akin to test-time scaling in LLMs), such patterns are not as evident in perception. The underlying drivers for perception improvements remain somewhat unclear, suggesting that exploring multi-step RL for perception, similar to approaches like OpenAI’s o3, might offer new insights.
Another area ripe for exploration is the potential of “RL-zero” (Reinforcement Learning from scratch or with minimal supervision) in VLMs. Current research in this specific area is limited, but early indications suggest RL-zero could surpass the limitations imposed by supervised fine-tuning (SFT). Given that multi-modal alignment is a fundamental challenge in VLMs, and SFT may have inherent constraints in fully addressing this, RL-zero could potentially redefine the optimization paradigm and unlock new capabilities for these sophisticated models.
The V-Triune system and the Orsta models represent a significant step forward in creating more versatile and capable vision-language models. By unifying the training for reasoning and perception, this work paves the way for AI systems that can not only understand complex information but also perceive and interact with the visual world in a more nuanced and accurate manner. The researchers plan to make the V-Triune system and Orsta models publicly available, hoping to inspire further research into RL as a general-purpose training paradigm for vision-language understanding, and to encourage the exploration of richer reward schemes, advanced reasoning strategies, and task-specific adaptations.